Hirdetés
- Szívós, szép és kitartó az új OnePlus óra
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Indiában Philips okostelefonokat is lehet majd választani
- Samsung Galaxy A56 - megbízható középszerűség
- Kis méret, nagy változás a Motorolánál
- Megérkezett a Google Pixel 7 és 7 Pro
- Kapható a strapamobil, aminek kikapcsolása nélkül lehet kicserélni az aksiját
- Bemutatkozott a Poco X7 és X7 Pro
- Külföldi prepaid SIM-ek itthon
- EarFun Air Pro 4+ – érdemi plusz
Új hozzászólás Aktív témák
-
#1230
 Petykemano
veterán
S_x96x_S
#1225
Petykemano
veterán
S_x96x_S
#1225
Petykemano
veterán
válasz
 S_x96x_S
#1225
üzenetére
S_x96x_S
#1225
üzenetére
Az ötleteléseidet kedvesebb közönség fogadja itt. Ha valaki vitázik is, nem azért, hogy kiutálja azokat, akik nem olyan belsős infókat hoznak, amiből cikket lehet írni egy másik újságban.
Nézd csak mire lehet jó a PCIe4:
AMD gets Western Digital Memory Extension tech for EPYC Optane battle
Western Digital: And when I pull the covers off, behold as NAND becomes virtual DRAMAzt nem tudom, hogy ehhez egyáltalán kell-e vagy hasznos lehet-e a későbbiekben CCIX vagy inkább Gen-Z. De biztos, mert a GEn-z-nek és az opencapi-nak tagja a WD és az AMD is.
Esetleg ott lehetne ilyesminek szerepe, hogy a CPU és a GPU is egyaránt tudja használni a memory extender eszközt saját céljaira (HBCC)Persze mindig fel lehet tenni azt a kérdést, hogy jó, de egy mainstream termékbe ez minek? marketing szempontból biztos jól mutat. Meg hát a programok memóriaigénye nem csökken.
Én látok benne fantáziát, még akkor is, ha ez ma még inkább csak a HPC és workstation piacon tűnik ténylegesen kihasználhatónak. Megmagyarázná az X570 hűtést, miközben ugyebár A PCIe4-et a világon semmi nem használja ki mainstream felhasználás során.
-
#1216
 Mahrenburg
őstag
S_x96x_S
#1179
Mahrenburg
őstag
S_x96x_S
#1179
Mahrenburg
őstag
-

awexco
őstag
válasz
S_x96x_S
#1032
üzenetére
Időközben utóbbi tippemet 4,6 ra módosítottam még megjelenés előtt. Ahhoz , hogy 4.3 ról 5.0 ra ugorjanak annak súlyos ára lett volna . Valószínűleg fejlesztési költségek az egekbe szálltak volna illetve jóval nagyobb chippeket kellett volna gyártani plusz magasabb lett volna a selejt arány . Így , hogy sok ponton reszeltek picit az végsősoron azt eredményezi , hogy 12 magon többszálon verik az intellt . Proci fronton lehet valami jó stratégiai team amely nagyon okosan sakkozik és nem próbál izmozni hanem okos döntéseket hoz .
-
#1187
Petykemano
veterán
S_x96x_S
#1176
Petykemano
veterán
válasz
S_x96x_S
#1176
üzenetére
Én magasabb frekvenciákra számítottam. 4.7-4.8-ra.
Ez Így kb 20%-os előrelépést jelent minden szegmensben azonos áron, magszám növekedése nélkül.
Nem rossz, de szerintem pont nem üti meg azt a lélektani határt, hogy legalább egy rövid időre vitán felül azt lehessen mondani, az Amdé a jobb processzor.Ez olyan, mint amikor a kedvenc csapatod döntetlent játszik a bajnokkal. Elismerésre méltó, hogy ezt a teljesítményt kisebb költségen rakták össsze, de lehet mondani: a bajnoknak rossz napja volt, és még így se, a bajnok a B csapatot játsszatta, és még ha nem is győzött, így is bajnok maradt.
A B csapat az amdnél már biztos a zen2+-on dolgozik. 😃
-
#1184
Petykemano
veterán
S_x96x_S
#1179
Petykemano
veterán
válasz
S_x96x_S
#1179
üzenetére
Pontosan mi indokolja a 11-15W fogyasztást?
Meg a $600 árat?
Mihez kell a 14-16 fázis? Ezekhez a 65-105W prüntyögőkhöz?
Olyan, mintha az alaplapgyártók adoredtv leakjéből dolgoztak volna és vmi ütősebb felhozatalra számítottak.
Ki fog $500-os cpuhoz $600-os alaplapot venni? -

Devid_81
félisten
válasz
S_x96x_S
#1182
üzenetére
Ez szinte biztos volt, hogy marad TR platform kozottunk

Elobb kell nekik az EPYC-hez minden fullon mukodo 8 magos CCX, epp ezert nem kaptunk most 12 magnal nagyobb Zen2-ot sem.
Majd ha kiszolgaltak a vevoket az EPYC-el, onnan johet a TR 3xxx es kozben Intel kiadja ev vegen a 10 magos 1151 v3-as procit, akkor jon ellencsapasnak a 16 magos Zen2 AM4.
Kb ennyi -

S_x96x_S
addikt
válasz
S_x96x_S
#1176
üzenetére
Ami még (nekem) lényeges:
- lebutított X570 ( minusz 4 PCIe sáv ) - cseréb csak 11W
- Akár 600$ -os alaplapok!
- Van remény a Threadripper-re."The new X570 chipset has 16 lanes, four for the upstream connection to the CPU, and twelve downstream for other devices. There is some discontinuity here – we heard from partners that AMD actually removed four PCIe lanes from the chipset design in order to bring the TDP of the chipset down from 15W to 11W; but the full-fat 15W version will be on the next editions of the high-end desktop (which would suggest that Threadripper isn’t dead, contrary to a lot of reporting – this is a question we will be asking Lisa Su later today). We have already seen a number of X570 motherboards ready to enter the market, and we expect around 25 new X570 models in total. It is clear that motherboard manufacturers are now getting serious on AM4 – some of these boards are likely to retail up to $600. These manufacturers are clearly expecting AMD to hit Intel hard, and have designed the motherboards to match the best that they make for Intel's CPUs."
( via ) -
S_x96x_S
addikt
válasz
S_x96x_S
#1173
üzenetére
Ami még érdekes A 3DMark PCIe tesz.
"9900K + 2080Ti" vs "3800X vs RX5700" in a Gen 3 vs Gen 4 dedicated test
Az új Ryzen konfig +67% -al jobban teljesített ( 14 FPS vs 25 FPS ) - lenyomja az Intel+nVidia párost!
( persze ez csak egy speciliázált teszt, és nem minden játékra igaz )
-
S_x96x_S
addikt
válasz
S_x96x_S
#1171
üzenetére
Összefoglaló:
Rome : Coming in Q3
( 2x28c Intel Platinum < 2x62core AMD Rome ) habár nem 2x teljesítménye van a Rome-nak.
------------
NAVI: Julius ( junius 10; E3 - további infók) !
RDNA - új architektúra;
- New Compute Unit Design, Improved Efficiency and increased IPC
- Multi-Level Cache Hierarchy - reduced latency, higher bandwidth, lower power
- Streamed graphics pipeline - optimized for performance per clock and high clock speed
RDNA vs Vega, 1.25x perf/clock and 1.5x perf/watt
1.25x is architectural efficiency
Announcing Radeon RX5000 Family
RTX 2070 vs Navi RX 5000 Series : about +10% perf in favor of Navi------------
Sok partner ..
- Microsoft: Ryzen family is going to hit 50% of modern devices this year
- ASUS X570 Motherboards
- Acer: AMD = Astonishing Miracle Delivery
- Acer Notebook: ACER Predator Helios 500, 23k Geekbench score
-----------Ryzen 3gen
- New 7nm Zen 2 core, 3rd Gen on AM4, World's first PCIe 4.0 PC Platform
- 2x Floating Performance - faster perf in creative workloads
- 2x cache size - reduced memory latency for gaming
- +15% IPC over Zen
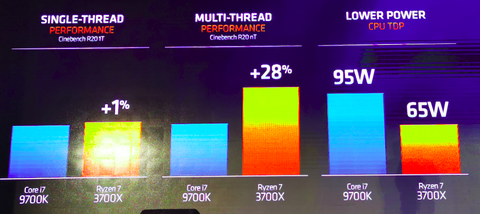
-
#1124
Petykemano
veterán
S_x96x_S
#1122
Petykemano
veterán
válasz
S_x96x_S
#1122
üzenetére
"Operating over standard PCIe, CCIX supports signaling rates between 16 GT/s and 25 GT/s per link with support for port aggregation for higher performance. " (CCIX)
AdoredTV leakjében szerepelt az X570-nel összefüggésben egy 64GB/s - gondolom ez valami össz PCIe4 lane bandwidth lehet. Ez már azért az a szint, amire rá lehetne kapcsolni valami optane/z-nand cuccot memory extendernek?
Ha gen-Z akkor az, ebből a szempontból mindegy.A gigabyte-os kijelentésének okát keresem.
-
#1119
Petykemano
veterán
S_x96x_S
#1117
Petykemano
veterán
válasz
S_x96x_S
#1117
üzenetére
PCIE4 elég lehet - több csatornával - valami RAM extender megoldásnak (HBCC-vel, ahol a DDR4 a gyorsítótár)? Olyan, mint amilyen az intel féle DIMM foglalatos 3dXpoint, csak PCIE4 csatornán keresztül és nyilván valami CCIX, vagy más memória-koherens fabricon, ami rá tud épülni a PCIe4-re?
-
#1116
Petykemano
veterán
S_x96x_S
#1115
Petykemano
veterán
válasz
S_x96x_S
#1115
üzenetére
Consumer AM4-ként én még mindig nem igazán látom a hasznát. Mármint egy játékos gépbe nem raksz bele 3 nvme drive-ot, nem?
De mondjuk a 16 magos proci alá, amit ilyen threadripper alatti munkagépnek szánnak, már inkább elfér. TEhát nem azt mondom, hogy semmire nem lehet használni, csak ez azért célpiac függénye.NEm? -
#1112
Petykemano
veterán
S_x96x_S
#1110
Petykemano
veterán
válasz
S_x96x_S
#1110
üzenetére
Tehát arról lenne szó, hogy a chipset.eddig pcie2 csatornát tudott csak kifelé, miközben pcie3-mal kommunikált a procival?
Merthogy igen, arról volt szó, hogy régi alaplap új procival BIOS frissítéssel tudná a pcie4-et, de nyilván csak azoknál az eszközöknél/csatlakozásoknál,.ami közvetlenül a procihoz megy
És ehhez képest az x570 kifelé is pcie4-et fog kínálni? Ha így van, az elég komoly előőrelépés a pcie2-höz képest. De mondjuk ez mire lesz használható?
Nyócmillió nvme drive am4-en?
Vagy haldokló multigpu? -
#1109
Petykemano
veterán
S_x96x_S
#1107
Petykemano
veterán
válasz
S_x96x_S
#1107
üzenetére
Szerver alaplapon nincs.chipset?
Miért pakoltak volna az epyc io lapkájából funkciókat a chipsetbe és nem a ryzen io lapkájába?A ryzen 1k ha jól emlékszem teljes lapka volt, elketyegett volna chipset nélkül is. A chipset csak kiszélesítette a funkcionalitásokat. Lehet, hogy emiatt esetleg az epycnek nem volt chipsete.
De akkor sem értem, hogy miért kerülne át bármi is a chipsetbe az io lapka helyett.
-
-

TRitON
aktív tag
-

Simid
senior tag
válasz
S_x96x_S
#1073
üzenetére
Azért adjunk már arra is némi esélyt, hogy az az álláspont igaz, ami Abu írt. Lehet tényleg a megnövekedett Rome kereslet miatt csúszik.
Szerintem sem nyírja ki a TR-t egy 16 magos Ryzen 3000. Kevésbé lesz kelendő a mostani a széria az biztos, de a TR esetleges előnyei nem csak a magszámból adódnak.
-
#1039
Petykemano
veterán
S_x96x_S
#1038
Petykemano
veterán
-
#1033
Petykemano
veterán
S_x96x_S
#1030
Petykemano
veterán
válasz
S_x96x_S
#1030
üzenetére
Azt nem vágom, hogy mi van a 300milliós design költségekkel. Mindig az van, h AMD nem tervez lapkát, mert 7nm már $300m egy új lapka csupán némi mókolással is. (Utoljára talán a pollaris 20-nál volt, hogy az többtízmillió dollár volt) Ez a supercomputer cakkundpakk $600$ és van/lesz benne 2 kereskedelmi forgalomban nem kapható lapka. Hogy éri ez meg? Vagy mégse 300misi egy-egy design (7nm-en)?
-
#1026
Petykemano
veterán
S_x96x_S
#1025
Petykemano
veterán
válasz
S_x96x_S
#1025
üzenetére
"Future-generation High Performance Computing (HPC) and Artificial Intelligence (AI) optimized, custom AMD EPYC CPU, and Radeon Instinct GPU processors supported by High Bandwidth Memory (HBM) and extensive mixed precision ops for optimum deep learning performance;
A custom high-bandwidth, low-latency coherent Infinity Fabric, connecting four AMD Radeon Instinct GPUs to one AMD EPYC CPU per node;
An enhanced version of the open source ROCm programming environment, developed with Cray to tap into the combined performance of AMD CPUs and GPUs"Persze az, hogy custom sokmindent jelenthet. Akár azt is, hogy olyan fícsöröket raknak bele, amit később szériatermékben is bemutatnak (ahogy a konzolokban)
-
#960
Petykemano
veterán
S_x96x_S
#959
Petykemano
veterán
-

Cathulhu
addikt
válasz
S_x96x_S
#937
üzenetére
Kicsit almat a kortevel erzesem van, semmi se egyezik a ket gepben, meg az akksi merete sem. Csak azert furcsallom, mert akkora ugras nincs a ket CPU kozott ami ezt a kulonbseget indokolna. Jobb lett volna, ha a 2700U-t is a referencia alaplapba tettek volna, illetve teljesitmeny adatoknak is tudnek orulni (papiron magasabb orajelekre van love a 3700U, ami kb negalja is a 12 nano elonyet).
-
#934
Petykemano
veterán
S_x96x_S
#929
Petykemano
veterán
válasz
S_x96x_S
#929
üzenetére
ez most akkor vajon zen+ vagy cat-core?
Valami kommerszializált konzol chip?
Mi lehet a cél?Én nem állítom, hogy az AMD-nek nem kéne jelenlét a mini-pc-k piacán, de korábban azt nyilatkozták, hogy a zen mindenhová jó. Vajon lehet-e az, hogy az MS (vagy a Sony) kiszervezte a cloud gaminghez alkalmas hardvergyártást zotac, gigabyte és hasonló cégeknek?
-
#924
Petykemano
veterán
S_x96x_S
#919
Petykemano
veterán
válasz
S_x96x_S
#919
üzenetére
Mit gondolsz, a core alapú licencelést a szoftverlicencelő érdeke bevezetni, vagy az Intelé, aki elvileg ugyanazt a teljesítményt kevesebb magból volt képes adni, de 64 maghoz nincs ellenfele.
Apropó, most jelentették be az 56 magos 9200-as Xeont. AVX512, INT8 - nem tudom ezek mennyit nyomnak a latba. De eltekintve a 400W-os TDP-től versenyképesnek tűnik. és kevesebb magra kell licencet fizetni. -
#911
Petykemano
veterán
S_x96x_S
#910
Petykemano
veterán
válasz
S_x96x_S
#910
üzenetére
Persze, én csak tippelek, tévedhetek is.
Csak az elmúlt években az AMD eléggé rászokott erre, hogy nem dobálja évente a teljesen új architektúrákat. Nyilván mert nem futja rá, és bár már két éve piacon van a zen, a pénzügyi helyzetük nem lépett olyan szintet, amiből arra lehetne következtetni, hogy sűrűsödhetnek a kiadások. -
#909
Petykemano
veterán
S_x96x_S
#907
Petykemano
veterán
válasz
S_x96x_S
#907
üzenetére
Valóban, jöhet a számonkérés. De hát az vesse rájuk az első követ, akinek kisebb nodeja van.
Az elmúlt 3-4 évben folyamatosan azt hallgatta, hogy mennyivel drágul a fejlesztés az egyes node-okra és hogy valójában mennyire minimális a nyereség a korábbi lépésekhez képest.
Meg aztán az egész chipletelésnek az lenne a lényege, hogy egyfélét gyártanak többféle piacra. Persze az igaz, hogy van 12nm-es Ryzen is, de az végülis majdnem ugyanazA naviról korábban volt szó, hogy EUV lesz, de aztán Abu azt mondta, hogy az AMD összes terméke most még DUV.
Azt nem tartom lehetségesnek, hogy a radeon VII már EUV lett volna. A navi és a rome/ryzen3k esetén még egy olyan scenáriót el tudnék képzelni, hogy azért csúsztatták el fél évvel, hogy átálljanak DUV-ról EUV-ra. De erre egyelőre nincs bizonyíték. Őszintén szólva én inkább arra számítanék, hogy az AMD most kihoz minden terméket DUV-ra, és jövőre frissít EUV node-ra navit, (vega20-at cseréli navi20-ra) és a ryzen3k-t. Epyc meg marad - pont mint előző körben.
Itt lehet némi zavar az elnevezésekben. Én úgy tudom, hogy a TSMC-nél 7nm DUV és 7nm EUV készül, utóbbi valami minimális perf és terület előnnyel. Ez utóbbit hívta a cikk 7nm+-nak nem?
-
S_x96x_S
addikt
válasz
S_x96x_S
#907
üzenetére
> és megint felteszik a "szokásos" kérdést, hogy miért van "mindig" lemaradva az AMD?
pedig a managereken nem múlik a dolog ; ők eröltetik.
A CPU termékgfejlesztés olyan mint a gyerekszűlés ? vagyis valamit nem lehet gyorsítani ?"Brooks rámutat arra, hogy egy nő kilenc hónap alatt hord ki egy babát; ugyanerre nem képes kilenc nő egy hónap alatt." wiki : Brooks-törvény
-
#889
Petykemano
veterán
S_x96x_S
#888
Petykemano
veterán
válasz
S_x96x_S
#888
üzenetére
Szerintem ez lesz:
május 1.
- 50 éves az AMD, Rome bemutatózás, "launch", 100 design wins.
- Esetleg kicsit többet villantanak meg a ryzen 3k-ból mint a CES-en, mondjuk bemutatnak egy működő 12 magosat, vagy hogy 65W TDP-n belül mit tud egymáshoz képest két 8 magos.május 27 computex
- ryzen paper launch. SKU-k bemutatása, benchmarkok (RVII@R7) árazással - availability júl 7.
- tesznek említést a Naviról, esetleg demóznak valamit... nagy eséllyel egy legkisebbet, ami 75W-ba belefér, de összességében nem gyorsabb az RX 590-nél. A többit költsék hozzá az influencerek
- rajt legkorábban augusztusban, inkább szeptember. Other Navi designs are on track, they are doing okayMég a Navi rajtja előtt lett légyen az bármikor is, biztos be fog futni egy 7nm-es Tesla, amiből lehet majd kapni $3000-3500-ért afféle Titant is.
Én meglepődnék, ha az AMD az E3-on navizna, ahogy az még januárban körbejárta az internetet.
-
#873
Petykemano
veterán
S_x96x_S
#872
Petykemano
veterán
válasz
S_x96x_S
#872
üzenetére
Én azt olvastam, hogy csak az X570-et fejlesztette az AMD házon belül, az alacsonyabb rendű chipseteket továbbra is az ASMedia szálítja. Fura lenne, ha mindkét fejlesztés zátonyra futott volna egy ponton és mindekettő fajtához a BIOS szállítása az alaplapgyártók oldaláról nehézségekbe ütközne. Nem?
-
#849
Petykemano
veterán
S_x96x_S
#848
Petykemano
veterán
válasz
S_x96x_S
#848
üzenetére
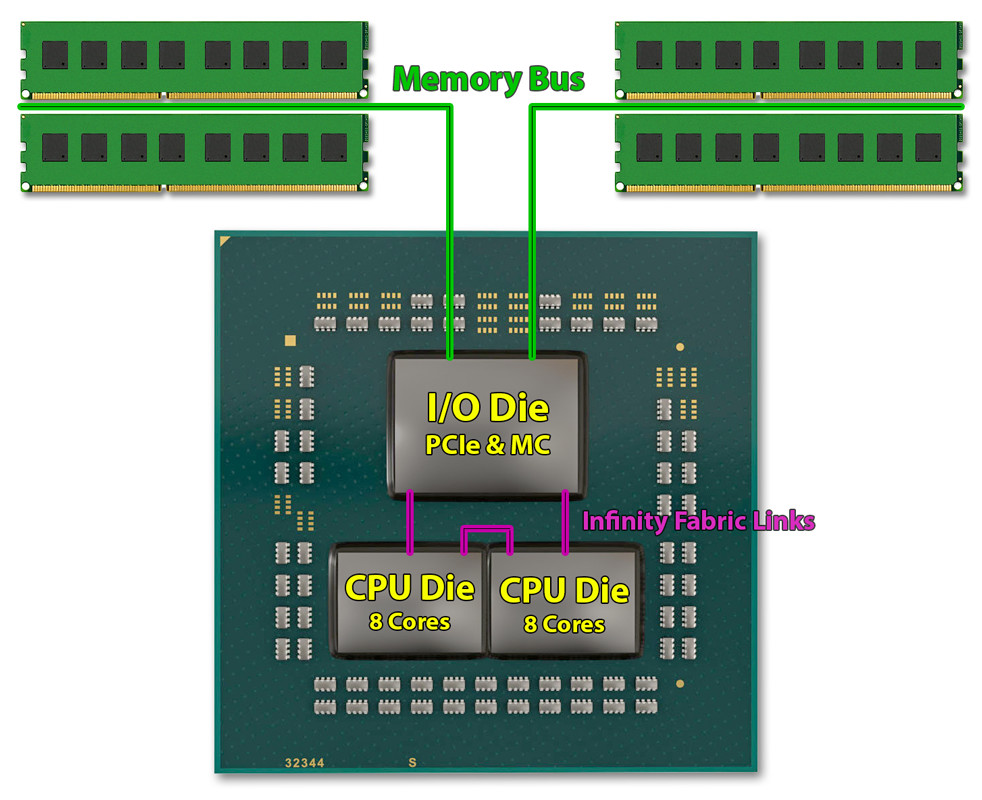
"CAKE, or "coherent AMD socket extender" received an additional setting, namely "CAKE CRC performance Bounds". AMD is implementing IFOP (Infinity Fabric On Package,) or the non-socketed version of IF, in three places on the "Matisse" MCM. The I/O controller die has 100 GB/s IFOP links to each of the two 8-core chiplets, and another 100 GB/s IFOP link connects the two chiplets to each other."
-
#825
Petykemano
veterán
S_x96x_S
#824
Petykemano
veterán
válasz
S_x96x_S
#824
üzenetére
> az eddigi bemutatók egy korai példánnyal demózott állapotok voltak.
Persze - az" over-hype" -ot ki kellene gyomlálni - de azért én nem következtetnék ebből egy végleges állapotra.Korai példány, korai állapot. Eddig azért volt hype, mert azt gondoltuk, hogy a végleges példány majd legrosszabb esetben is valamiféle lineáris arányossággal skálázódik fel, van abbanég kraft és még biztosan.jobb is lesz, ha csiszolnak a végelgesen. A hype eloszlatása abban áll, hogy ha sikerül reálisan látni: a bemutatott példányok a karakterisztika legideálisabb pontjára vannak kalibrálva. Mehet feljebb a frekvencia, de a mintapéldány értékeitől fölfelé az eredmények exponenciálisan romlanak.
Jó, akkor nem biztos.
De eddig az AMD a legjobb fényben demózott, nem tett úgy, mintha lényegesen jobb termék lenne a végeredmény, mint demózott változat, ezért esélyes, hogy az eddig látottak meghaladása (magasabb frekvencia) nem jön majd olcsón (exponenciálisan növekvő fogyasztás) -
válasz
S_x96x_S
#807
üzenetére
Akkor ezek alapján előbb jön a Matisse (3xxx Zen2 7nm), mint a Picasso (3xxxG Zen+ 12nm)? Utóbbit noti szegmensben már bemutatták (3xxxU/H), adná magát, hogy desktopon is jöjjön mielőbb. 2xxx szériában is előbb jött a 2xxxG, mint a 2xxx, ha jól rémlik.
De az is lehet csak lemaradtam a 3xxxG-hez való AGESA érkezéséről.
-
S_x96x_S
addikt
válasz
S_x96x_S
#785
üzenetére
pörög tovább .. Majus 4,-i hétre mondja a Bizgram Asia Pte Ltd .
( állítólag ~ AMD 50 éves évfordulója körüli dátum. )
(Reddit )Q:Thank you for the quick reply. Can you also provide me information on the ETA of each of the Ryzen 3000 series CPUs, including the Ryzen 5 3600X and the Ryzen 5 3600G?
A: "Respected Sir/Madam
expected may 4th week
Thanks & Regards
Sales & Admin
Geeta
Bizgram Asia Pte Ltd . "
-
Cathulhu
addikt
válasz
S_x96x_S
#771
üzenetére
Ismerek olyan fejlesztot, aki Macet preferal. Maganeletben. Munkara viszont egyet sem. Nalunk is van egy Mac build gep, hogy forditson Mac-es release-t, de ezen kivul mindenki linux vagy windows. Es az hogy frontend developer mit preferal irrelevans akkor, amikor szervert kell valasztani.
A kerdesekre amiket ideztel a valaszok pont ellentetes eredmennyel zarulnak:
"I’m a senior architect in SV, I’ve used both, and can say with certainty that Linux is a better choice for me. I believe it should be strongly considered by others."
"Most professional programmers don't prefer Macs."vagy pl
"3. servers are running linux so better to develop on the same OSThis is not correct, it is better to test on the same OS. There is no benefit to developing on that OS.
This is why they use OSX over Windows, because it is the best of both worlds. All the tools, and IDE’s, and the closest to linux you can get, without having all it’s technicalities thrown in.
You can run all the same server based software with homebrew."Ez meg abban a pillanatban megszunik, amint ARM alapu mac-ek lesznek es x86-os szerverek.
-
-
-
Cathulhu
addikt
válasz
S_x96x_S
#757
üzenetére
Huh, hát azért ezzel óvatosan. Nyilván best case scenario, szimulált és nem valós eredménnyel, 7nm-en fele annyi maggal rendelkező 14 nanos versenytársakkal szemben.
Nem haragszok az ARMra, szeretem is őket, de a fizika nekik se fekszik le a két szép szemükért, ha már a két másiknak több évtizedes szerver CPU tervezési tapasztalattal eddig sikerült eljutni.
Amúgy szépen jönnek fel az ARM szerverek teljesítményben, az eMAG is gigantikus ugrás az elődhöz képest, de megváltani nem fogják a világot, max kompetitívak lesznek. Másrészt látjuk az AMDnek mennyire nyögvenyelősen indul be az Epyc biznisz, pedig ott a vevőnek x86-ról x86-ra kellene váltania.














 ))
))










![;]](http://cdn.rios.hu/dl/s/v1.gif)











Új hozzászólás Aktív témák
- BMW topik
- CADA, Polymobil, és más építőkockák
- Szívós, szép és kitartó az új OnePlus óra
- Feltörték a regisztrációmat vagy elvesztettem a belépési emailcímet, 2FA-t
- sziku69: Szólánc.
- Melyik tápegységet vegyem?
- Autós topik
- Elektromos autók - motorok
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Indiában Philips okostelefonokat is lehet majd választani
- További aktív témák...

- Lenovo ThinkPad P1 Gen 4 i7 32GB RAM 512GB SSD NVIDIA T1200 16 2560 1600 Garancia
- Dell Precision 7550 i7 32GB RAM 512GB SSD NVIDIA Quadro T1000 FHD
- Dell Precision 5560 i7 32GB RAM 512GB SSD NVIDIA RTX A2000 FHD+
- BOMBA áron eladó új Microsoft Surface Laptop 4 garanciával! AMD Ryzen 5 /16GB /256 SSD/TOUCH/13.5"/
- Dell Latitude 7420 i7 / 32GB /1TB SSD / FHD IPS
- 145 - Lenovo Legion Pro 7 (16IRX9H) - Intel Core i9-14900HX, RTX 4090 (ELKELT)
- LENOVO Legion Pro 5 16IRX8 - 16" WQXGA 240Hz - i5-13500HX - 16GB - 1TB - RTX 4060 - 9 Hó garancia
- REFURBISHED és ÚJ - HP Thunderbolt Dock G2 230W with combo cable (3TR87AA)
- Tablet felvásárlás!! Apple iPad, iPad Mini, iPad Air, iPad Pro
- 156 - Lenovo LOQ (15IRH8) - Intel Core i5-13505H, RTX 4060
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest