- iPhone topik
- Yettel topik
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Samsung Galaxy Watch7 - kötelező kör
- Motorola Edge 60 és Edge 60 Pro - és a vas?
- Hivatalosan is bemutatta a Google a Pixel 6a-t
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Friss koncepciót hoz a Nothing Phone (3)
- Xiaomi 15 Ultra - kamera, telefon
- Íme az új Android Auto!
Új hozzászólás Aktív témák
-

5leteseN
senior tag
A két CPU-s rendszerek (azok alapján amit olvastam) csak 50% körüli plusz teljesítményt adnak, sok kérdőjellel és bizonytalansággal.
Ezért döntöttem a neves dupla-CPU-s szerver alkalmazás helyett(HPE ML350p, DELL-ek, HP380 G8/G9, ...) a tuningolható kínai mellett, ami szerintem jobb választás.
A felsoroltaknak van 5 x19-os VGA-juk, + még 2-3 kisebb, de nálam W10-11 alatt össze-vissza-akadtak, sok esetben nincs driver Windows-okhoz és bizonytalan(-abb, mit a kínai alaplapok esetében), mert a felsoroltak kimondottan szerver üzemmódra vannak tervezve, és a "Nagyok" nem adják ki az open-driverek megírásához szükséges kódokat/infókat.
A 2. évemet nyomom a "Nagyok" ezen (részükről üzletileg szándékosan gerjesztett)problémáinak kiismerésével és megoldásával.
Meguntam!
Szomorúan látom ráadásul, hogy az általuk "kínai-gagyi" kategóriásnak mondott eszközök állva hagyják a régi nagy neveket ezen a területen(is).A témához visszatérve: a kis tuninggal elérhető (Ryzen 5600X körüli) CPU-teljesítmény jól és fillérekért adja a kiegészítést és a szükséges hátteret az AI-n izzadó GPU-knak a modernek és ide nem optimális modern alaplapokhoz képest, de ehhez minimum 32(de még inkább 64)GB RAM kell.
Király: a valóban kicsit koros 8de ezzel az laplapi tuninggal egész jóteljesítményű) szerveres DDR3-akat most öntik a használ-piacra, és nem sokkal többért (és a desktop DDR4-nél és DDR5-nél főleg sokkal jobb áron) jönnek már a DDR4-es szerver-RAM-ok is. A 64GB RAM-mal és 1(-2) GPU-val ez az alaplap pár évig bőven elég lesz(reményeim szerint) egy élvonalbeli amatőr AI-s otthoni rendszerben, a ki tudja milyen(de folyamatosan botrányokkal tarkított) adatvédelmi káoszban.A GPU-k a CPU-hoz viszonyítva(sok szakfórum egyetértő megállapításai alapján) 7-15-szörös sebességgel futtatják az AI feladatokat.
A több VGA-s lehetőség rövidesen itt kopog az ajtómon!![;]](//cdn.rios.hu/dl/s/v1.gif)

-
5leteseN
senior tag
Kis hardver kitérő azoknak akiknek nem csak a legdrágább(és nem is mindig a legjobb), de elég-jó-vételes, jó teljesítményű, saját-építős hardver kell.
Ahonnan a későbbi döntésemig jutottam: Mivel a csábító Mini-PC-k a teljesítményhez képest drága lapos-RAM-okat használnak, azokat is csak két foglalattal, és csak külső eGPU lehetőséggel, és a "laposok" átépítése eGPU-val szintén nem győzött meg, ezért kis keresés után "meggyőződődtem", hogy a meglévő "több-kiló"(3-400GB
 ) szerver-RAM állományomat és a hozzá passzoló CPU-imat(E5-26xxv3-akat) meglepően jól tudom hasznosítani egy 2011-3-as alaplappal, Kínából. Az ECC-s DDR3 készletem a 4-RAM-csatornás alaplap és CPU segítségével közelíti a méregdrága és finnyás DDR5-ös rendszer RAM-sebességét, egyedül CPU-ban elmaradva. Erre viszont a fórum tárgyát képező AI-MI területen nincs is nagyon szükség, hiszen a VGA-GPU-k 8-15-ször jobban, hatékonyabban, gyorsabban dolgoznak az ezen a területen szokásos AI-feldolgozásnál a processzoroknál.
) szerver-RAM állományomat és a hozzá passzoló CPU-imat(E5-26xxv3-akat) meglepően jól tudom hasznosítani egy 2011-3-as alaplappal, Kínából. Az ECC-s DDR3 készletem a 4-RAM-csatornás alaplap és CPU segítségével közelíti a méregdrága és finnyás DDR5-ös rendszer RAM-sebességét, egyedül CPU-ban elmaradva. Erre viszont a fórum tárgyát képező AI-MI területen nincs is nagyon szükség, hiszen a VGA-GPU-k 8-15-ször jobban, hatékonyabban, gyorsabban dolgoznak az ezen a területen szokásos AI-feldolgozásnál a processzoroknál.EZEN a berendelt alaplapomba

az eBay-en pár-tíz €-ért vannak Ryzen 3600 körüli teljesítményű E5-ösök, alig több (alul-feszelt) fogyasztással, de jelentősen jobb memória-rugalmassággal és fejleszthetőséggel: nem kettő Ryzen-es, hanem 8 RAM foglalattal! Ugyanez ráadásul érvényes a VGA-k számára is, ahol a Ryzen-ek viszonylag drága alaplapjai egy VGA-t szeretnek kezelni, míg az öregecske 2011-3 egy (szerver-)CPU-val is lazán visz 3(x16PVIe3.0-ás) VGA-t és 8 DDR3-DDR4-es RAM-ot. Egy viszonylag drágább, akciós alaplapom jön(meg, remélem hétvégére), de aki nálam is nagyobb fejlesztési lehetőséget akar(még több VGA, még több RAM), annak vannak nem sokkal drágábban(70- €-tól indulva, Ali-k, duplája: eBay) két-processzoros alaplapok is. Bevallom én kicsit túllőttem a fenti alaplappal az eredeti 2011-3-as célomon,
ami még mindig a korábbi(elvetett) Ryzen-es tervemnél jóval többet tud a két VGA-ak(+4xPCIe, +1xPCIe, ...) és 4 DDR3-DDR4 RAM aljzatokkal(128GB). Egy gazdaságos indulást tervező AI-s felhasználónak EZ a 2011-3-as alaplap is több mint elég az induláshoz, de én most ennél kicsit "nagyobbat markolok".
Mindezeket az hardver 5leteket és infókat úgy említem, hogy bár jelenleg (még) nem nagyon használnak az egyéni felhasználóknak összerakott AI-s programok(Fooocus, LM Studio, Ollama, ...) több VGA-t, de becslésem szerint azok is idők is sebesen közelegnek, tehát az a plussz 10-20€ befektetés a több-VGA-s alaplapokba nem túl nagy kockázat, a többlet RAM lehetőséggel főleg!
Gondolom én!Ki unaloműző szösszenet, amíg megérkeznek a Flux és RAG videók!
+ 
-
5leteseN
senior tag
-
5leteseN
senior tag
válasz
 gabranek
#962
üzenetére
gabranek
#962
üzenetére
Most, hogy nézem a képet beugrott egy lehetséges hiba, ami nálam is volt és jelentősen lassított, talán: Az adrenalin beállításoknál valami "Advanced" beállítás, Adrenalinos lapváltásnál nem látható egyből, hanem (nálam, akkor, fél évvel ezelőtti Adrenalin verziónál a baloldalon volt egy alsó menüpont alatt), ahol ez a "Valamilyen Memória megosztás"-t be lehetett állítani, ami bekapcsolva azt csinálta, hogy a VRAM és sokkal lassabb "sima" RAM-ot osztotta meg, ezzel minden memória műveletet a sokkal lassabb "sima" RAM sebességére butítva. Ezzel lehetett használni a VRAM méreténél nagyobb AI-adatbázisokat, Tensor-okat, LoRA-kat a sokkal lassabb "sima" RAM sebességen. Úgy látom, hogy ez akár lehet a hiba nálad is ez esetben, mert a betöltéskor a "sima" RAM használat is ugrik az egekbe, a VRAM-mal együtt!!
Ezt nézd meg szerintem. Sajnos(mint említettem), most én magam nem tudom ezt megnézni(hogy hol van ez a beállítás az Adrenalinban), mert átépítés alatt áll az AI-s konfigom.
Annál az 1GB VRAM-nál meg az az érdekes helyzet volt(akkor, ami helyzet gyorsan változik a piszok-gyors fejlesztés miatt), hogy sok VGA modellnél (nálam is szerencsére) az egyik frissítésnél a probléma érdekesen oldódott meg, mert kiírva maradt az 1GB VRAM, de használni használta amennyire szükség volt.
Úgy látom, hogy nálad is ez a szerencsés helyzet van, mert ugyan 1 GB-ot ír ki ezek szerint a terminálban, de a Feladatkezelő-ben szinte az egész memória foglaltként szerepel.
Nekem ez a Memória-megosztás a leggyanúsabb!Ha nem ez lesz az ok, majd nézzük tovább!

-
5leteseN
senior tag
Akkor "lemaradtam"!

Igazad van!A "professzionálisban" mikkel ilyen jó az AMD?
A nekünk, "halandóknak" szánt kategóriában az nVIDIA (még) az egyértelműen nyerő, csak a mazochisták(, mint én is) erőltetik a consumer-AMD-VGA-kat.
Arról meg aztán szinte semmit nem találok, hogy például a Fooocust, LM Studio-t, többieket hogyan tudnám futtatni négy AMD-s MI25=>WX9100-on(Windows 10/11).
Nyomnék pár teszt-kört mielőtt eladom!

-
5leteseN
senior tag
A "szupereknél" emlékeim szerint nem az AMD vezet és nincs többségben az emlékeim szerint főleg a jelentősen rosszabb energia-hatékonysága miatt.
Esküt nem teszek rá, de így hirtelen kutakodva a szürkeállományomban ezek ragadtak meg.
Ha ROCm meg nem lesz jó a MI25-eimre, akkor hiába volt "jó-áras", menniük kell rövidesen.
Jelenleg az MI25-ők Windows alatt nem nagyon tudnak"ROC"-ogni(talán Linux alatt), de volt már rá példa a(z IT-)Történelemben is a driverek-nél, hogy visszamenőleg is jöttek korábban letiltott képességek a régi(Legacy-s) vasakhoz. Az mintha egyébként főleg pont az nVidia-knál lett volna....lekopogtam, hátha "műxik", bevetik ezt a piaci értékelést (a megelégedett AMD-s tulajokon keresztül) befolyásoló meglepetés-faktort az AMD-nél !
Cég-érték(nVIDIA): Igen, egyébként, az AI-őrület hullámaira ülve szépen túl-, felfújódott az nVIDIA-lufi a tőzsdéken.
-
5leteseN
senior tag
A VGA-k esetében segítség lehetne mindenkinek infók arról, hogy - a (gondolom nem ok nélkül) kb. fél-áras AMD VGA-k tényleg ennyivel gyengébbek-e,
- Linux-alatt például(van program ahol jobbak mint az nV-k),
- a lassan de biztosan "alájuk"(AMD-khez) fejlődő-fejlesztés alatt álló ROCm valóban kezd-e egy CUDA szintet közelíteni, ahogy azt ígérte(-ígéri) az AMD,
- stb-k...Példa: én kb egy hasonló nVidia VGA-hoz képest harmadáron vettem az AMD VEGA56-ot, ami utána VEGA64-re (BIOS-)módosítva a Fooocus alatt tudta az említett áras nVidia szintet.
Az is ide tartozik, hogy sok AI szoftvernél még a készítői oldalon sincs meg (ismeretlen ok miatt
 + ) az AMD-k támogatása.
+ ) az AMD-k támogatása.
Korábban, kb egy éve például a Fooocus is csak 16GB-os, vagy nagyobb VRAM-os AMD-n "tudott" elindulni és még most is ott van "béta-fázis" infó a Fooocus telepítői oldalakon, bár nekem nincsenek egyértelműen rossz tapasztalataim.
Csökkenő az AMD-s hátrány, de folyatódik-e? A 2-3-4 éves (akkor drága, és még most is jó sebességű) AMD-k visszamenőleg megkapják-e az AI-s szoftver támogatást(ROCm), stb...Nem tragikus, nem egyértelműen rossz, de bizonytalanságot jelző hírek az AMD-ről, főleg egy szinte robbanás szerűen fejlődő területen. Gyorsan javulhat is, és kontra is...
Én még "kicsit" tartogatom a saját AMD-imet(VEGA 56=>64, MI25-ök=>WX9100-ra, ...).
-
5leteseN
senior tag
válasz
gabranek
#954
üzenetére
Most van átépítés alatt az AI-hardver nálam, nem tudom futtatni pillanatnyilag a Fooocus-t(sem)! Saját gépen nem tudok ránézni.

Arra emlékszem, hogy sokaknál(nálam is sokáig) azért volt gond, mert csak 1GB VRAM-ot látott a Fooocus az éppen altuális VGA 8 vagy 16 GB-jából. Ezt a az indító terminál szövegében tudod megnézni, ott lesz egy külön sor, ahol meg van adva, hogy mennyi VRAM-ot lát-használ a Fooocus.
Mennyit?
A Windowws Feladatkezelő teljesítmény ablakáben látod, hogy hova tölti a Fooocus a Tensor-t, LoRA-t: a sima RAM-ba, vagy a VGA VRAM-jába. Látszik majd a folyamat a memória foglaltságok változásánál a sok GB-os méretek miatt, egyértelműen: előtte-utána.
Miközben a Fooocus indul, én már az alatt szoktam nézni! -
5leteseN
senior tag
válasz
gabranek
#951
üzenetére
Szia!
A Fooocus-nál külön AMD-s indító verzió van. Azt beraktad az indító .bat-ba?
Gyorsan ránézek a Fooocusra, hogy változott-e. Annyi még előtte, hogy korábban volt olyan AMD-s gond, hogy csak 1GB-osnak látta a kártyát.
Milyen VGA-d van?Ránéztem, még időn belül.
ITT van az amit én használok, és itt ezt írják az AMD VGA-kra:Windows (AMD GPUs)
Note that the minimal requirement for different platforms is different.
Same with Windows. Download the software and edit the content ofrun.batas:.\python_embeded\python.exe -m pip uninstall torch torchvision torchaudio torchtext functorch xformers -y .\python_embeded\python.exe -m pip install torch-directml .\python_embeded\python.exe -s Fooocus\entry_with_update.py --directml pause
Then run therun.bat.
AMD is not intensively tested, however. The AMD support is in beta.
For AMD, use.\python_embeded\python.exe entry_with_update.py --directml --preset animeor.\python_embeded\python.exe entry_with_update.py --directml --preset realisticfor Fooocus Anime/Realistic Edition.Ezen nálad rendben vannak?
-
5leteseN
senior tag
Elnéztem, és a 3080 lett az összehasonlítási pár.
Igen, dupla teljesítmény, kb dupla fogyasztás, dupla áron a használt 3090.Sokkal jobb, de nekem túlértékeltnek tűnik. Ilyen a piac, és látjuk az (AI-s) okát is. Nekem az a 350W és az azzal járó (leírt
) kockázatai zavaróak még mindig, egy garanciai nélküli használt VGA-nál főleg.
Ha nem, akarok ilyen kockázatot, akkor meg alulfesz és MHz-limit -5-7-10%.
Viszont nem sürget semmi, az idő(árcsökkenése) nekem dolgozik. Remélem!A hardvernél maradva: nálam is a duplázott VGA a tervezett jövő, de nem nagyon hallok híreket, hogy ezek hogy működnek(működnek
) együtt?
Az ilyen esetekre a műszaki életben "általános" 1,7-es szorzó(a második-többi VGA-ra) áll-e? Mi a (várható szoftver)helyzet a második(többi ) VGA-ra?Most is ott vannak a polcomon az MI25-ök, ezekenek(és az utódainak) épül át bányászrigből az saját Szuper-Házi-AI/MI-s "dobozkám".
...lassan és biztosan!
-
5leteseN
senior tag
válasz
 Mp3Pintyo
#939
üzenetére
Mp3Pintyo
#939
üzenetére
Zakatolnak a buksimban az infók, köszönet.
A korábbi Tom'shardware-es képen
 :
: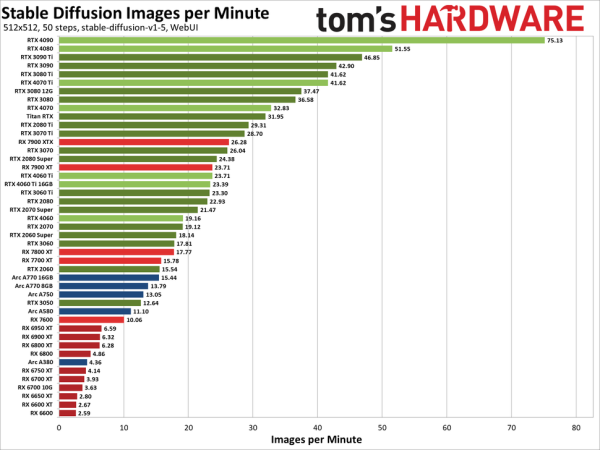
... néztem, hogy a 4060Ti "csak" 30-35%-kal tud kevesebbet a 3090-nél, fele(sem ? ) fogyasztással, valahol fele új-ára körül.
A 16GB VRAM amivel "vesztésre áll" egyedül, a többinél (fajlagosan) a kis-öcskös(4060Ti) áll nálam nyerőre.És még kis "magánügy" is: Azon múlik igazán, hogy jól fogok-e tudni kiszállni az AMD-kből!
Valóban jobb lenne egy új 3090.
"Átgondolás" (€/$/Ł/HUF... ) van folyamatban nálam is, mint sokaknál! -
5leteseN
senior tag
válasz
 freddirty
#935
üzenetére
freddirty
#935
üzenetére
Nagyon új még az AI-terület, és "tép, mint az állat..." (
 )a fejlesztést-fejlődést tekintve!
)a fejlesztést-fejlődést tekintve!A 4060Ti-s kártyáról jut eszembe: (amit majd én is meg fogok nézni) az eddigi tuningolható kártyápmat szinte mindig meglepően jól tudtam húzni a VRAM-ok MHz-eit tekintve.
Most éppen AMD-kel vagyok tele, nem tudom újra megnézni, de emlékszem, hogy az nV-k is jól mentek felfelé.
Meg tudod esetleg ezt a VRAM freki-húzást nézni "előtte/utána" módon a 4060Ti-nél?
Érdekelne, hogy a VRAM MHz-ek mennyire számítanak. -
5leteseN
senior tag
Gyors összegzésem, magamnak, kb: +20% (Video-) teljesítményt nyújt(a Passmark szerint) a használt 3090(ami az AI-ban nem is lehet biztosan tudni, hogy több lesz, vagy kevesebb), +50% VRAM-mal(+8GB), +100% áron a használt 3090(750€-tól indul:eBay), az új 4060Ti-hez képest, amihez van-lesz 1-2-3 év garancia!
Ráadásul a saját 20 éves IT-hardveres tapasztalataim alapján a hétköznapi felhasználónak gyártott "bármi", ami 300W felett fogyaszt, az (tapasztalataim alapján) komoly kockázat, főleg garancia nélkül.Összeszedtem szinte mindent, ami mérlegelés alatt van.
Az új 4060Ti(340-400€) előnye növekszik. A családi költségvetésbe az annyival egyébként sem többet tudó(mennyivel egyébként, kb? ) ÚJ 3090 ára(1.000+ €) nekem sem fér bele, házon belül nincs is felvetve. : Kösz! Minden ilyen hír aranyat ér!
: Kösz! Minden ilyen hír aranyat ér! AI-ban még nincs elfogadott teljesítménymérés, ráadásul több, erősen eltérő eredmény is születhet azonos kártyák között, LLM, kép-generálás, eltérő módszer alapján dolgozó AI-chat esetén.
Nagyon új még terület, és "tép, mint az állat..." (
)a fejlődést tekintve! -
5leteseN
senior tag
-
5leteseN
senior tag
válasz
 DarkByte
#920
üzenetére
DarkByte
#920
üzenetére
Én ezért gondolkodom azon, hogy egy "lapos"(-top)-hoz rakok egy eGPU-s(vagy átépített bányász-rig átalakítással) összehozható, hasonló célú AI-szervert.
Ha nem kell éppen az AI, akkor 5-10-15W-ból netezgetek a laposon a külső monitorral. Amikor meg kell majd az AI, akkor felébresztem(vagy újra indítom) a fentebb említett AI-eGPU külső dobozkát(: a polcon erre a feladatra várakozó 1200W-os HP tápból és a szintén polcos 2-3-4 AMD-s VGA(GPU)-ból összedrótozva), aminek gyűlnek az elemei, hogy hónap végére ez is meg legyen.
Ha kel(-akarom) a "lapos"-hoz csapom hozzá ezt a "szuper-AI" dobozkámat, ha kell a(brutálka fogyasztású és memóriájú(64 vagy 128 GB DDR4 RAM-os) 2x2680v4-hez.
Gyülekeznek a polcomon a szükséges AI-elemek, gyülekeznek...
+ télen nem kell majd fűteni sem! -
5leteseN
senior tag
válasz
Mp3Pintyo
#912
üzenetére
Bizony, bontottam is egy sört, és ezúton is Köszönetek neked (
) a gyorsan megérkezett WebUI-s videóért!Bokros teendőim miatt az Ollama videó után nem írtam, hogy "Mikor érkezik ehhez az egész jó kis AI-hoz egy jól kezelhető felület?", és mire rászántam volna magam, addigra meg is jött a (gondolom) sokak által várt kezelőfelület.
Még túl is teljesítette az elvárásaimat, mert úgy tűnik, hogy egy általános, kvázi-szabványos kezelőfelület lesz több AI-részterület felé is.
Kellemes meglepetések! -
5leteseN
senior tag
válasz
DarkByte
#906
üzenetére
Igen, igen, igen
+ : "látatlanban" megtaláltad az okot (ami a RAM méret), ami miatt az ismerten jóval lassabb CPU-n(a jelenlegi költséghatékonyság mellet most még) van értelme ezen a kifutó szerver-procin is futtatni LLM-eket, a jobb LLM-ek 27-36-40+ GB-os méretei miatt.
Pont ezért(és biztonsági gyanúim miatt) most éppen "leszállok" az LM Studio-ról, és átnyergelek az Ollama-ra.
Már a parancssoros Ollama-videónál is gyanús volt, hogy túl jó ez ahhoz, hogy az elkényelmesedett felhasználók(kicsit én is ) ne kapják meg a "nekik járó" grafikus felületet, ami meg is jött nem sokkal később! -
5leteseN
senior tag
 , +tüzijáték, puszi a barátnőmnek, +pezsgő-bontás!
, +tüzijáték, puszi a barátnőmnek, +pezsgő-bontás!
...már települ is!Előtte ezért valaki még teszteljen egy 2x2=?-t, és ne füllentsen ám, a válaszról!

... jut eszembe: A hanyadik évben, és hány (tíz-)milliárd "elégetett" dodó után is vagyunk?
"Költöi" volt a kérdés, természetesen!Azért köszönöm!
-
5leteseN
senior tag
"... Amúgy meg sz általad felhozott szakértői rendszer is szegről-végről "AI", az egy decision tree model
"Igen(jól olvastál a soraim között
), mert valóban erre kívántam utalni: egy tizen-sok éve, sokkal kevesebb tudású(és árú) vasra jól megírt (szak-)szoftver jobb mint a "Közösségis" és-vagy sok-milliárd $/€-ós "Sokat/mindent-is-akar(t-volna-tudni)-a-szarka,-de..." stílusú és eredményű dolog!
Mondjuk azok tizen-sok éve is már tizen-sok millió(HUF)-ba kerültek(nem véletlenül). Az most 100m HUF nagyságrend...Ezért keresgélnék egy "Fa-ék" szinte belőle, amiből aztás a nekem tetsző szakterületre összerakom a saját "szakértői-rendszeremet"!
... kihagyva a "Sokat-akar...) kezdetű használhatatlan, kaotikus részt....de nem hagyjááák(hogy használhatót csináljaaaak)!
-
5leteseN
senior tag
válasz
DarkByte
#872
üzenetére
Bokros teendőimet ritkítottam, ezért megelőztél, de kb nekem is ez volt a nyelvem hegyén, mint vélemény: ha ilyen szinten el kell magyarázni, akkor annyi erőforrásból már sok esetben magát a feladatot is meg tudom oldani.
Egy tizen-sok évvel ezelőtti (jól összerakott és "megprogramozott") szakértői-rendszer kategóriájú szoftver az adott szakterületén még ma is jobb, mint a jelenlegi "sokat-markolok-de(-a túltolt marketinget lehámozva)-alig-valamit-tudok"(logikailag).
Talán az óvodai szintű Kő-Papír-Olló megy (8GB-os LLM-ből, egy 3090Ti-n 24GB VRAM-mal), de már ez az ovis logikai játék két szinten és (ráadásul logikailag)összekötve szerintem már azt sem tudná sikerrel megugrani!!Ez az adott IT-szakterületen a "Való-Világ"..Így vélem én!
Én meg közben(meg akik még komolyan vették a beharangozott eredményeket) lereagálom képletesen az "eredményeket", íme: 
-
5leteseN
senior tag
Nekem az lett a "saját" teszt-kérdésem, hogy ha Eva(név mindegy) a 32 éves nő, 9 hónap után szült egészséges gyermeket, akkor a hasonló korú barátnője várhatóan hány hónap terhesség után fog szülni?
Eddig egyetlen AI sem tudta az egyszerű, jó választ a tesztelt 20(+)-ból, ami jó válasz a "kb szintén kb 9 hónapra", hanem szinte mint 12 hónap(vagy nagyobb) számot mondtak, mondanak. Alapvető AI-hiányosságok vannak, + megnyugodtam: (értelmes, gondolkodni tudó) emberekre még sokáig szükség lesz!

-
5leteseN
senior tag
válasz
 ParadoxH
#819
üzenetére
ParadoxH
#819
üzenetére
Én a Fooocus programot szoktam használni, ami egy a Stable Diffusion-ből (ha jól emléxem erre) egyszerűsített text-to-image kategóriás képgeneráló AI-s program, ezért erről nyilatkozok:
* böngészőből egyszerűen kezelhető, saját-gépes/off-line üzemmódú "darab", Mp3Pintyo készített is róla egy jó kis videót. Én is abból tanultam, azóta használgatom.
* a böngészőből használva a bal alsó sarokban találod azt a funkciót ami neked érdekles lehet(tippelem én)
* az említett funkcióval egy meglévő képhez(esetedben a "mintázat"-hoz) hasonlót tudsz készíteni(beállíthatod, hogy mennyire hasonlítson), ami képalkotás így sokkal egyszerűbb(volt nekem is), mintha a nulláról kezded írni a promt-okat, majd azokat farigcsikálni,
* korábban raktam be egy magyar nyelvű használatot lehetővé tévő kiegészítést, valahol ott van Mp3Pintyo-Discord csatornáján. (még, gondolom), ebben a szinte csak a nemzetközileg használt szavakat meghagytam eredetiben,
* kezdetnek, szórakozás szinten(és tanulni) nekem jó-elég volt
* majdnem kimaradt: nVidia esetén elég neki egy 4GB-os kártya, AMD-ből 8GB-os kell, AVX2-es CPU-val(kb 10 éve mindegyik az, a neten rá tudsz keresni, ha nem vagy benne biztos). -
5leteseN
senior tag
Igen, az előző hozzászólásban említett programot (azon belül is a Faster-Whisper-t) teljes elégedettséggel használom!
Ami jár, az jár(Mp3Pintyó-nak): + Én annyit egyszerűsítettem magamnak úgy, hogy megcsináltam a videó-könyvtáras beállítást a videóból, így nem kell átnevezgetnem semmit, csak berakom a magyarra feliratozandó videót a könyvtárba és staaaart...
Kb egy kv-idő alatt megcsinálja az 5-25perceseket!...nem kell átnevezgetnem, beállítgatnom semmit, "kopi-paszta"!
-
-
#681
5leteseN
senior tag
Feketelaszlo
#679
5leteseN
senior tag
válasz
 Feketelaszlo
#679
üzenetére
Feketelaszlo
#679
üzenetére
Például az LM Studio!
Saját gépen futtatható Chat.
Már 6-8GB-os VGA-n is futtatható. A 6GB nVidia, a 8+ GB AMD-k.
Lassan használható lesz , javulgat! -
5leteseN
senior tag
Viszonylag elégedetten használom a Fooocus-t AMD VGA(GPU)-kal. Annyit viszont szeretnék megoldani, hogy a leírt AMD-s indításoknál minden alkalommal leszedi az nVidia specifikus elemeket és felrakja az AMD-s elemeket helyette. Mivel mindig AMD-t használok és néha baj is van a net-kapcsolattal(ami ilyenkor mindig kell) nem tudom net nélkül használni a programot, holott nem is kellene mindig újra-telepíteni.
Hogyan tudom ezt a problémát megoldani?
-
5leteseN
senior tag
Ilyen szintű dolgok "véletlenül"
nem szoktak ingyenes formában lenni. Amikor mégis összejönne, akkor a fizetős verziók formátumai szoktak változni(valamilyen "nagyon-nagyon-fontos" képesség miatt), ami miatt a nehezen elért átjárhatóság ismét elvész, lásd MS-Word .doc formátumainál, és egyebek...Olyanról hallottam, hogy hasonló esetben korábban pár elszánt(egyébként mérnök-)személy regisztrált személyenként 4-5-6-... mail-cimet, és azokkal elkezdték az ingyenes szoftverek fejlesztőcsapatait "támadni" és fél+ év kitartó levelezés után sikert értek el: megcsinálták a szabványok (szokásosnál gyorsabb) követését az adott területen.
Ez természetesen csak egy városi legenda, de állítólag igaz! Szerintem, ha megtaláltad azt a 2-3-ingyenes programot, amiből össze tudod állítani a neked szükséges "tudás-mixet", akkor regisztrálj pár Yahoo-Gmail-... címet és egy VPN-t hozzájuk...
Kis csapatmunkával meglepően jól lehet segíteni a "jó irányt" az ingyenes programok fejlesztőinél! Vannak csodák, meglepő módon dolgozni kell értük.
-
5leteseN
senior tag
Nem mindenre:
1, Meta: A "Cukorsüveg-fiú" cége(Facebook=>Meta) által finanszírozott/készített LLM-ek neve, a cégre utal,2, Llama-3: a 3. generációs Llama LLM, ez a legfrissebb
3, 8B: 8Billion=8GB-os méret
Q5: 5-ös kvantálású (tömörítésű/egyszerűsítésű) feldolgozás, az 5-6-7-es a jó hatékonyságú, a kisebbek gyakrabban hibáznak, a nagyobbak nagyon-nagy méretűek és lassúak a megfizethető asztali gépeken.
Kb ezeket tudom, a többi engem is érdekel.
-
5leteseN
senior tag
Azt én is látom, sőt mivel GGUF, már töltöm is (remélem, otthon elindítva hagytam a gépet), de a megadott oldalon hol van GGUF? Én nem látok olyat, és az LMS-em sem látta, mert csak a kompatibilis mutatása van bekapcsolva a keresésnél.
Nem gond, ez is jó este nézem majd...
-
-
5leteseN
senior tag
...és az LMStudionak most jött kia 2.20-as verziójára a ROCm.
Ma kezdem próbálgatni, hogy az én régebbi AMD-kártyáimon fut-e, mert alapból a 6600(XT)-től felfelé futna csak, de "megesett" már párszázszor, hogy a nem bejelentett régebbi modelleken is mentek programok/driverek, egyebek.További jó hír, AMD-seknek hogy az LMStudió már fut 8GB VRAM-os AMD-ken is(akár RX580/8GB VRAM-oson is) a korábbi irreális 16GB helyett.
Még 1-2 évtized és az AMD utoléri a jelenlegi nVidia szintet!
Állítólag a ROCm közelíti a CUDA-t. Van valakinek saját tapasztalata?
-
5leteseN
senior tag
Van uncensored LLM-is: jordan nevű például(=> "Gugli" barátunk).
Elmesélte uncensored-jordan, hogy hogyan tudnék Porsche Panama-rát lopni
, csak némi jogi kriminológiai figyelmeztetőt mellékelt hozzá, semmi "nem mondhatom el mert, bla-bla-bla..."Bevallom (de csak ha köztünk marad
), nem teszteltem le, hogy tényleg megy-e, csak azt teszteltem, hogy mennyire "uncensored"! Az is lehet persze, hogy ment a neten online ennek a híre a "Nagy testvérhez".A poén mellől visszatérve a szakmai részre: bár 13B-s alapban az uncensored-jorden, de van jól használható (5-ös kvantálású) belőle, ami 8GB VRAM-os kártyán is fut, és a mostani LM Studio már fut a 8GB VRAM-os AMD-ken is, a korábbi irreálisan magas 16GB-os(AMD-s) követelmény helyett!
-
5leteseN
senior tag
Nocsak, érkezik a ROCm???
Meglepően gyorsan.Örülnék neki, végre lépett volna az AMD!
Esetleg van arról, hír, hogy az AMD Radeon Instinct MI25 (és családja ) is támogatott? Betáraztam ezekből hármat kb 80€-ért(mikor "kilóra adták"), remélem nem meggondolatlanul!
Ennyi fér az ML350p-be(1300W táp ). -
5leteseN
senior tag
A lengyel úr elmeri mondani mennyibe került az A100-as? Elég húzós "Kikötői" árakra emlékszem tavalyról.
... nekem halandónak!
Nem ismerve a területet: nekem 2-3-4 darab RTX3090-ből összerakott gép költséghatékonyabbnak tűnik, ha ez a GPU-k közötti megosztás működik. Én ezt tenném meg, ha...A kiszivárgó infó-részletek alapján mintha ezek a tanítgató programok fel lennének készítve több GPU használatára. Ezért van fenntartva nálam erre a feladatra vagy két TESLA P40-em vagy három AMD MI25-öm, meg rengeteg időm is van, ellentétben a piaci-verseny miatt rohanásra kényszerülő "nagyokkal" szemben(hozzájuk képest). Ráadásul engem részterületek érdekelnek, ezért relatívan kis modell méretekkel, és nem is a mindent megváltó, és mindenre választ adó Szuper-Intelligenciát hajszolom.
Ezt meghagyom nekik! ...ahogy a Fúziós Energiát, az Örök Életet, és a Tökéletes Akkumulátort is, sok más egyébbel együtt! -
5leteseN
senior tag
Engem még mindig az érdekelne, hogy az LM Studio-n futtaható kisebb LLM-et szakterületre, hogyan lehet csinálni???
Elég homályos infók vannak erről a területről!
...vagy még azok sem! Miért is?Unalmas (nekem) a hangya-kukinyit különböző, szénné-Pol-korrek-telt, semmit mondó, de cserébe a : ..."de tudod, hogy találhatsz a neten továbbiakra ember/forrás/bármi, ..." szöveget minden blokkja végén az arcomba toló, újabb "világmegváltó" modelleket.
Eddig nekem gyakorlatilag a sokból csak a TheBloke-os mixtral x2 moe 34B és a jordan uncensored 13B volt használható: tudnak akár táblázatot is összehasonlításkor, és ezeket kis hibával tudják magyarul is.
Nálam 75 layer-rel futnak a modellek a TESLA P40-en, ami csak a 24GB VRAM-ja miatt van nálam és másoknál is a színpadon még, mert erőben valahol a sima 1080 körül kullog a mezőny után, de azok a versenyzők a 8-12-16GB VRAM-jukkal az ennél nagyobb modelleknél a durva hátránnyal elindulni is esélytelenek.Ahová meg a 24GB VRAM nem elég az általában már más szint, ott már ezer, tíz-ezer $/€-król döntenek a felhasználók, hogy melyiket üzemeltetik majd tízes. százas mennyiségben, szerverparkban, és "egyebek".
-
5leteseN
senior tag
Az jutott eszembe, hogy ki kellene találni valami házi teljesítmény-összehasonlításra alkalmas promp-ot a könnyen használható (és ezért nekem elég népszerűnek tűnő)Fooocus-hoz, kíváncsiságból, ami a közelmúlt VGA kártyáitól a következő 1-2 évben várhatókig nagyjából összehasonlíthatóvá teszi ezek teljesítményét.
Szerintem összegezve bőven vagyunk annak a tudásnak a birtokában, ami ehhez a feladathoz kell!
Mi a vélemény erről?
Kb milyen feladat, promp-t(mi lehetne a magyar neve?) jó erre a célra, ebben a VGA sávban, ebben az idő(-5---+2 év) tartományban?Lehet ez kicsit speciális dolog ide, ebben az esetben be kéne ugrani Mp3Pintyo Discord-jába tovább vinni(text2image) a témát.
-
5leteseN
senior tag
válasz
 phrenetiX
#514
üzenetére
phrenetiX
#514
üzenetére
Az angolul, egyszerűen megfogalmazott kép, + a felirat kérése(ilyet még nem csináltam), de gondolom a felirat (magyarul) idézőjelben. meg is nézem majd kíváncsiságból, hogy megy-e!
Ha nem megy az angol, az sem baj(szerintem nm, nekem sem megy nagyon): magyarul megfogalmazva ugyanez egyszerű megfogalmazásban, majd fordítás(Google translate, ...)
Karácsonyi üdvözlőlap, téli kép szánnal.
Felirat felül, középen: "..."
+ => fordííítóóó -
5leteseN
senior tag
Értem, ez az output része, én az inputot is belevettem. Így kerül felhasználásra a token.
De ez minek az otthoni gépes felhasználó esetén? Ez csak akkor információ értékű, ha korlátozott tokenem van. Otthon annyit írok be, amennyit akarok.Esetleg ez a token(/mp ?) jelez(het) valami sebességét az adott AI képességere nézve?
-
5leteseN
senior tag
válasz
 sirály12
#503
üzenetére
sirály12
#503
üzenetére
Az erre a kérdésre kapott korábbi válaszokból magamnak is összerakva a választ: Jelenleg csak a nagy szereplők által összerakott, be-/megtanított LLM-ek(Large Language Modell: Nagy nyelvi bázisok(modellek)) vannak. Ezekhez a 3-7-13-sok GB-os méretű modellekhez grafikus feladatoknál vannak kiegészítők(LoRa-k), amikkel az általános tudást el lehet vinni a saját terület tudása irányába. A chat-es modelleknél nehezen elérhetők, vagy nem nagyon vannak még ilyen lehetőséget. Azt gondolom, viszont, hogy olyan iszonyúan gyors a fejlesztés, hogy hónapokon belül lesznek ilyen lehetőségek. Én is várom, de nagyon!
Gondolom, a Házigazda(Mp3Pintyo) és a többiek is hozzáteszik majd amit tudnak.
-
5leteseN
senior tag
Ezt tudom, gyakorlatilag pénzként működik, venni lehet, vagy kapni az "adataimért", hozok mást valakiket, stb...
A saját gépen futó AI/MI-knél nem értem a tokenezést Ott is van valami token, ami valahol a mélyén biztos le is van írva a sok oldalas beleegyező nyilatkozat végén(vagy másutt), a szokásos "kisbetűs" módon.
+ "Töröm" is kicsit angolt ...
-
5leteseN
senior tag
válasz
 #42308056
#465
üzenetére
#42308056
#465
üzenetére
A saját gépes Fooocus tud bemenő képet fogadni, és azzal tenni lehet a híres arcot akár a másik bemenő képre, vagy a korábbi Seed-del/maggal újra előhozott képre, amin nyilván a már elkészített mozdulat és környezet van.
Tettem fel Fooocus-os magyarítás(próbálkozást) is, bár mindent nem lehet az angol szakterület kifejezései miatt lefordítani.
Szerintem egyszerű, jól használható program, a kis magyarítással még inkább. -
5leteseN
senior tag
-
5leteseN
senior tag
Kicsit (füllentettem: nem kicsi) gondom támadt a másik gépemen tökéletesen működő whispwr-faster AI/MI-s felirat-készítővel: látja a VHA-t(GTX960) fel is van telepítve hozzá a cuDD kiegészítés, de nem használja. A VRAM igénybevétel megnő(3,5GB), de sem a GPU, sem a CPU nem nagyon dolgozik, alig változik a w-f indítása előtti igénybevétel. Valami történik, mert iszonyúan lassan készíti a feliratot: 4 óra alatt 82%-ra jut egy 12 perces videóval(az alig észrevehető GPC és-vagy CPU terhelés árán)!
-
5leteseN
senior tag
válasz
Mp3Pintyo
#456
üzenetére
 Nem tanul. Ezeket a modelleket így nem tudod tanítani jelenleg, hogy beszélgetsz velük. Finomhangolni tudnád őket de az egy sokkal bonyolultabb feladat és nem árt hozzá egy erőgép
Nem tanul. Ezeket a modelleket így nem tudod tanítani jelenleg, hogy beszélgetsz velük. Finomhangolni tudnád őket de az egy sokkal bonyolultabb feladat és nem árt hozzá egy erőgép 
Na majd két hét múlva! ... amilyen gyors a fejlesztés! Abban tudsz segíteni, hogy hogyan érted el a 13b-s llama-t hogy magyarul válaszoljon(a Szentendrés program-ajánlattal)? Nekem ellenáll!
-
5leteseN
senior tag
Az LM Studió alatt valamiért nem akar magyarra áttérni, pedig letöltöttem a 13b-s llama chat 2-t, a Q5-öset, aminek a video alapján tudnia kellene magyarul. Valakinek ment? Mit kell "mondani" neki, hogy átváltson magyarra?
Mitől fog tanulni? Iz nem nagyon hangzik el, hogy hogyan dícsérem meg a jó válaszért, hogyan tudok a rossz válaszért "jutalmazni"? Mi gafsz a tokenje, ami 1.500-zal indul, stb...
Ezektől lehet(ne) tanítani, vagyus ezt si krdezném, hátha ezeket tudja valaki. Gyorsítanám a saját tanulási folyamatom is.
ugyanez érdekes lenne Krita-nal is, mert mire megfejteheti egy átlagos felhasználó(csapatmunka nélkül), addigra jönnek az új verziók, és a régiek tudása "Husss"!
Az Mp3Pintyo Discord-ba betettem a Fooocus magyarítását kezdőknek a "text2image" témába, a fa-ék egyszerű "telepítéssel" együtt.
-
5leteseN
senior tag
válasz
 alton1978
#441
üzenetére
alton1978
#441
üzenetére
Nekem volt ilyen. A legújabb hivatalos driver kell(700+ MB, nVidia hivatalos oldaról javasolt), mert az AI/MI-s programok nagyon frissek, a legújabb CUDA utasításkészletet használnák (gondolom), és össze-vissza akadnak a régebbiekkel. Mivel őrült tempóban rohan a mostani AI-területen a program-fejlesztés, nincs is idő rendesen követni a bejelentett hibákat fejlesztői oldalról: nem is egyértelmű milyen hiba, mi megoldás, mert mire idáig eljutnának, már kijött a kettővel újabb verzió!
A lényeg: a legfrissebb drivered van fenn? Én tegnap frissítettem: 546.17-es a legfrissebb! Nálam ezek a hibák(a második kép befejezése előtt eredmény nélküli kilépés és/vagy lefagyás) az meghajtó frissítés majd újraindítás után megszűntek!
Ha nem emiatt van, akkor majd továbblépünk!
-
5leteseN
senior tag
A 700MB-os friss nVidia-driverben szerintem benne van. Mióta (pár órája) frissítettem a GTX960/IT-dinoszauruszom meghajtóját (pedig az sem volt régi, valami 545...) azóta nincsenek Fooocus leállásaim a CUDA-ra hivatkozva.
Tanulság: A Fooocus jól eldöcög régi (4GB és feletti) VGA-kon is, de kell a legújabb meghajtó program(nVidia tapasztalat)! -
5leteseN
senior tag
-
5leteseN
senior tag
Mp3Pintyo Yt csatornáján mintha lenne ilyen videó. Nézegetted már?
Online nem kell erős gép, ha otthoni gépen akarsz szépet/jót/nagyot(felbontás) csinálni, akkor jó VGA/GPU kell. Milyen van a PC-dben? Ez alapvetően meghatározza, hogy saját, vagy online úton jutsz el az eredményhez.
-
5leteseN
senior tag
Online a "sexy" és hasonló szavak teljesítése szerintem erősen limitált lesz.
Ott ahol megnézhető a rejtett +promt is, látható, hogy az ebben szinte mindig benne lévő, az itteni listában jó eséllyel szereplő elegant, romantic és hasonlók szerintem kiütik ezt a "sexy" és kategória társas kifejezéseket majd.
Talán(?/!) a topless belefér...
Teszteld őket! Nekem mindenáron arab szépségeket mutogat dzsungelben!
... ééérted: Afrika, "jungle", és önti rám az arab szépség ideált !
A realista változat! : ( -
5leteseN
senior tag
Az LM Studió GB-okat hagy több helyen is a W11 éa a Ccleaner takarítás után is! Én az AI/MI-s tesztelgetős gépen pont nem online-bankolok, de nekem gyanúsan sok szemét marad a programok után.
Egészséges bizalmatlanságot javasolok!
Képgenerálás: A kezek továbbra is gondot okoznak a Fooocus-nál is és az új kép-sprinter kedvencemnél(Krita) is: 5-6-7 ujjak(+ az 1-2 hüvelyk-uj : ), csuklótöréses kézpozíciók, és ritkán még 1-2 kéz(láb) többletbe.
Igyekeztem pedig az állandó promt-ba is beírva ezt a követelményemet, így próbálva megszüntetni, de gyakori hiba továbbra is. Valakinek van erre receptje??Azért azt is hozzáteszem, hogy ezzekkel a problémákkal együtt most percek alatt hozok össze kezdőként olyan képeket, amikbe beletört a bicsak évekkel ezelőtt a Gimp-nél, hetek után belefáradva.
Mindig fejlődne az ember: Az is felmerült bennem, hogy hogyan tudnám kiegészíteni az egyébként nagyon jó, de általános tudású képalkotók tudását speckó terület képeivel és szabályaival és ami kell, hogy ezekkel kiegészülve tudjam használni??? Főleg a Krita érdekelne.
Erről van valakink híre, olyan megoldással, ami halandó számára is megvalósítható? -
5leteseN
senior tag
A 40 szavas szövegből az 768x1280-es képet 520 mp körül csinálja meg nálam a Fooocus: 17s/it
(GTX 960, Jugger...safetensors)
A Krita 20-60 mp között a hasonló szövegest, hasonló méretűt (Vega 56)Jó lenne a Fooocus-hoz is valami gyorsító Lora, vagy végre a működő Windows-os AMD-s kiegészítés. Ebben a formában nálam semmi komolyabbra nem alkalmas.
-
5leteseN
senior tag
válasz
 5leteseN
#403
üzenetére
5leteseN
#403
üzenetére
Nem futott ismét! Be akartam tenni, hogy mi a probléma, de nem látom értelmét, mert akárhány Fooocus-os AMD problémának néztem utána a Net-en, a végén egyik sem volt sikeres.
A Fooocus-os csapat elengedte az AMD-ket?
Sok ezzel foglalkozó fórum-szál megoldás nélkül van lezárva valamelyik fórum-gazda által. Eredményre szerintem az vezetne, ha elég sokan írnának nekik(és más fórumokra is) a helyzetről és akkor a közösségi nyomás hatására: talán.
A jóval gyengébb, és fele VRAM-os GTX 960 a Fooocus-on egy képet készít sokszoros(5-6-szorosra becsülöm) idő alatt, mint a Krita egy (végleges, nem Live)képet! Szívesen összehasonlítottam volna a két programot ugyan azzal a GPU-val, de nem akar sikerülni ez az összehasonlítás.
-
5leteseN
senior tag
válasz
5leteseN
#402
üzenetére
A kis-ördög(nagy?
) nem hagyott békén, a dolgozó programmal is próbát tettem az AMD-s kiegészítésű run.bat-ot futtatva, ahol jött a szokásos hiba üzenet a végén:
" ... Fooocus\python_embeded\lib\site-packages\torchsde\_brownian\brownian_interval.py", line 234, in _randn
return _randn(size, self._top._dtype, self._top._device, seed)
File "C:\Users\Fontoska\Desktop\AMD Fooocus\python_embeded\lib\site-packages\torchsde\_brownian\brownian_interval.py", line 32, in _randn
generator = torch.Generator(device).manual_seed(int(seed))
RuntimeError: Device type privateuseone is not supported for torch.Generator() api.
Total time: 7.31 seconds "... de ezt már tudjuk( ...tudjuk?), hogy az ezen a helyen
(...Fooocus\python_embeded\lib\site-packages\torchsde\_brownian\brownian_interval.py", line 32) lévő, vastaggal szedett állomány 32. sorában kell törölni a zárójelben lévő device szót, és semmit nem tenni a helyére.
Ezek után elméletileg jó lesz(jó volt legalábbis annak, akitől idéztem ezeket Gugli barátom segítségével).Gyors teszt után megosztom a tapasztalatokat.
-
5leteseN
senior tag
válasz
5leteseN
#401
üzenetére
Számok az alábbihoz, hogy ne "nyúl-bogyóval gurigázunk":
" Fooocus>.\python_embeded\python.exe -s Fooocus\entry_with_update.py
Already up-to-date
Update succeeded.
[System ARGV] ['Fooocus\\entry_with_update.py']
Python 3.10.9 (tags/v3.10.9:1dd9be6, Dec 6 2022, 20:01:21) [MSC v.1934 64 bit (AMD64)]
Fooocus version: 2.1.824
Running on local URL: http://127.0.0.1:7865
To create a public link, set `share=True` in `launch()`.
Total VRAM 4096 MB, total RAM 65458 MB
Trying to enable lowvram mode because your GPU seems to have 4GB or less. If you don't want this use: --normalvram
Set vram state to: LOW_VRAM
Disabling smart memory management
Device: cuda:0 NVIDIA GeForce GTX 960 : native
VAE dtype: torch.float32
Using pytorch cross attention
Refiner unloaded... "Tehát az nV-s változat kapásból látja az összes VRAM-ját a GTX960-nak és rendben elindul:
" ...Fooocus V2 Expansion: Vocab with 642 words.
Fooocus Expansion engine loaded for cpu, use_fp16 = False.
Requested to load SDXLClipModel
Requested to load GPT2LMHeadModel
Loading 2 new models
App started successful. Use the app with http://127.0.0.1:7865/ or 127.0.0.1:7865 "Az idézett jó kezdet és idézett sikeres befejezés között 50-100 sor a telepítésről, nem érdekes, nem volt benne hibára utaló rész, a fontosnak tartottat raktam be csak.

-
5leteseN
senior tag
válasz
5leteseN
#400
üzenetére
Amikor másnak is támad ilyen (nálam Fooocus-nál, ezért így is kezdődik, vastaggal a lényeg: Fooocus error AssertionError: Torch not compiled with CUDA enabled) CUDA-t hiányoló gondja, akkor meg kell keresni az aktuális(éppen használt, mert több is lehet) Python könyvtárat, ott kiadnia " cmd " terminál indító parancsot(erre és sok mindenre a Total Commander javasolt), bemásolni ezt (mindig idézőjelek nélkül):
" python -m pip install --upgrade --force-reinstall --no-cache-dir --no-deps torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 "...és elméletileg egy friss telepítéssel a szükséges helyre meg is oldja a gondot a hsz időpontjában friss 1.18-as CUDA-val.
Ez egy erőltetett(... force...) telepítés. Javasolt előtte a hibával jelentkező saját AI/MI programnak azért utána nézni! A lusták vessenek magukra!
Nekem meggyógyult a beágyazott(saját magába telepített) Python-t használó Fooocus programom.

Hasonló (akár jobb
) eredményt mindenkinek... -
5leteseN
senior tag
-
5leteseN
senior tag
Valamit betölt a VRAM-ba, mert amikor elindítom a generálást, akkor az addig 0,7GB-os VRAM foglaltság felmegy 7,8-ra(8GB van), majd elszáll, ez az első hibaüzenet:
[Sampler] sigma_min = 0.0291671771556139, sigma_max = 14.614643096923828
Requested to load SDXL
Loading 1 new model
ERROR diffusion_model.output_blocks.1.0.in_layers.2.weight Could not allocate tensor with 117964800 bytes. There is not enough GPU video memory available!
ERROR diffusion_model.output_blocks.1.1.transformer_blocks.1.ff.net.0.proj.weight Could not allocate tensor with 52428800 bytes. There is not enough GPU video memory available! -
5leteseN
senior tag
"Modern-Világ"
Biztos, hogy ilyen lovat akartam?
Kiegészítettem a run_AMD.bat állományomat:
--------------------------------------
.\python_embeded\python.exe -m pip uninstall torch torchvision torchaudio torchtext functorch xformers -y
.\python_embeded\python.exe -m pip install torch-directml
.\python_embeded\python.exe -s Fooocus\entry_with_update.py --directml.\python_embeded\python.exe -s Fooocus\entry_with_update.py --normalvram --use-split-cross-attention
pause
----------------------------------------Ezt is javasolták: --use-split-cross-attention
...nyomtam az ENTER-t, és:
----------------------------------
\Fooocus>.\python_embeded\python.exe -s Fooocus\entry_with_update.py --directml
Already up-to-date
Update succeeded.
[System ARGV] ['Fooocus\\entry_with_update.py', '--directml']
Python 3.10.9 (tags/v3.10.9:1dd9be6, Dec 6 2022, 20:01:21) [MSC v.1934 64 bit (AMD64)]
Fooocus version: 2.1.824
Running on local URL: http://127.0.0.1:7865
To create a public link, set `share=True` in `launch()`.
Using directml with device:
Total VRAM 1024 MB, total RAM 65458 MB
Set vram state to: NORMAL_VRAM
Disabling smart memory management
Device: privateuseone
VAE dtype: torch.float32
Using sub quadratic optimization for cross attention, if you have memory or speed issues try using: --use-split-cross-attention
Refiner unloaded.
...
-------------------------------------- A vége mondjuk ez:
-----------------------------------
Fooocus V2 Expansion: Vocab with 642 words.
Fooocus Expansion engine loaded for cpu, use_fp16 = False.
Requested to load SDXLClipModel
Requested to load GPT2LMHeadModel
Loading 2 new models
App started successful. Use the app with http://127.0.0.1:7865/ or 127.0.0.1:7865
------------------------------------------------------Akár jó is lehet.
Nézzük a "Girl on street" klasszikust:
----------------------------
return tensor.to(device, copy=copy).to(dtype)
RuntimeError: Could not allocate tensor with 117964800 bytes. There is not enough GPU video memory available!
Total time: 45.18 seconds
-------------------------------------------------- Ehy kép generálást állítottam be és legkisebb felbontásúra tettem a képméretet:
-----------------------------------------
... \Fooocus\Fooocus\backend\headless\fcbh\model_management.py", line 532, in cast_to_device
return tensor.to(device, copy=copy).to(dtype)
RuntimeError: Could not allocate tensor with 117964800 bytes. There is not enough GPU video memory available!
Total time: 10.42 seconds
---------------------------------------------- Az sem sejtetett sok jót nekem, hogy a Firefox-os saját szerveres Fooocus oldal így nézett ki
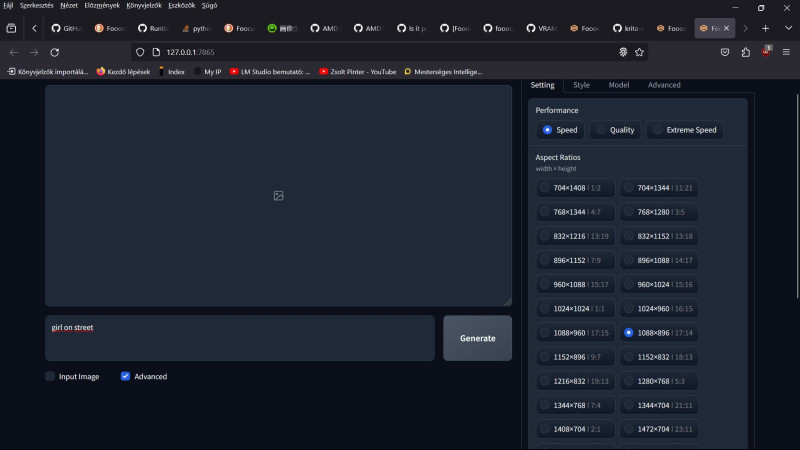
... amikor működött, közepén megjelent egy a kis állapotjelző szimbólum. Amióta nem működik a Fooocus, azóta a középen látható "hiányzó elem" szimbólum látható a helyén.
Ez csak érdekesség volt.
-
5leteseN
senior tag
A Fooocus-szal nem volt semmi gond, amíg nem váltottam az AMD-re. Csábító volt a 3-szoros teljesítmény és a dupla VRAM.
Meg is van, mióta kicseréltem, csak azóta a Fooocus nem indul
Az is jó volt pedig, jól eljátszogattam vele a Cyberpunk-stílusú képekkel ...Azon gondolkodom, hogy visszateszem az AMD-VEGA mellé a GTX 960-at is. 5W fogyasztás, amikor nem dolgozik. Remélem találok tápkábelek hozzá.
Ma kicsit elhavaztam, de nézem majd azt a --NORMALVRAM-ot.
...és .Nálad pontosan hogy néz ki a run.bat-ban a kiegészítés?
-
5leteseN
senior tag
-
5leteseN
senior tag
válasz
Mp3Pintyo
#373
üzenetére
Köszönöm!
Kicsit később nézem, mert most gép-takarítást végzek: gyanúsan kezd összeakadni a sok keresztbe-kasul telepített AI-s program és azok Python-jai és egyebei.
A pár nem tetsző és nem sikerült AI-t leszedem, és megy vissza a Fooocus, Krita, és szerintem még vmelyik Comfyui.
A Oogabooga is marad vagy újratelepül szerintem.
A Whistler hibátlanul dolgozik, bár csak részfeladata van(feliratozik), de azt nálam kiválóan végzi! Közben frissült is a Krita generatív AI-ja.
Ha maradt volna a korábbi telepítés, akkor magától frissítette volna? -
5leteseN
senior tag
válasz
Mp3Pintyo
#366
üzenetére
Igen, kösz a segítséget, emlékeztem, hogy valahol a szokásostól eltérő érték kell, csak nem jutott eszembe, hogy melyiknél, nem bírom a tempót
!Akkor ez a CFG érték a Fooocus-nál maradhat a 7-es érték, nem az okozza a gondot.
Akkor én/mi keressük tovább a megoldást erre az AMD-VGA-k problémájára...
-
-
-
-
5leteseN
senior tag
Nézem én is az Mp3Pinyo csatornán, a videókban, és a VRAM beállításra adott Gugli-eredményeket is bogarászom, de nem nagyon van másnak ilyen problémája.
Lehet, hogy ismét berakom a gépbe a házi-múzeumból a GTX 960-as nV-t, mert azzal kapásból
menteldöcögött.
Örültem volna, ha ezzel a 3-4-szeres teljesítményű és dupla VRAM-os AMD-vel is megy, de eddig ... 

![;]](http://cdn.rios.hu/dl/s/v1.gif)




 ) szerver-RAM állományomat és a hozzá passzoló CPU-imat(E5-26xxv3-akat) meglepően jól tudom hasznosítani egy 2011-3-as alaplappal, Kínából. Az ECC-s DDR3 készletem a 4-RAM-csatornás alaplap és CPU segítségével közelíti a méregdrága és finnyás DDR5-ös rendszer RAM-sebességét, egyedül CPU-ban elmaradva. Erre viszont a fórum tárgyát képező AI-MI területen nincs is nagyon szükség, hiszen a VGA-GPU-k 8-15-ször jobban, hatékonyabban, gyorsabban dolgoznak az ezen a területen szokásos AI-feldolgozásnál a processzoroknál.
) szerver-RAM állományomat és a hozzá passzoló CPU-imat(E5-26xxv3-akat) meglepően jól tudom hasznosítani egy 2011-3-as alaplappal, Kínából. Az ECC-s DDR3 készletem a 4-RAM-csatornás alaplap és CPU segítségével közelíti a méregdrága és finnyás DDR5-ös rendszer RAM-sebességét, egyedül CPU-ban elmaradva. Erre viszont a fórum tárgyát képező AI-MI területen nincs is nagyon szükség, hiszen a VGA-GPU-k 8-15-ször jobban, hatékonyabban, gyorsabban dolgoznak az ezen a területen szokásos AI-feldolgozásnál a processzoroknál.











 +
+ 

 :
:
 )a fejlesztést-fejlődést tekintve!
)a fejlesztést-fejlődést tekintve! : Kösz! Minden ilyen hír aranyat ér!
: Kösz! Minden ilyen hír aranyat ér! 












 Nem tanul. Ezeket a modelleket így nem tudod tanítani jelenleg, hogy beszélgetsz velük. Finomhangolni tudnád őket de az egy sokkal bonyolultabb feladat és nem árt hozzá egy erőgép
Nem tanul. Ezeket a modelleket így nem tudod tanítani jelenleg, hogy beszélgetsz velük. Finomhangolni tudnád őket de az egy sokkal bonyolultabb feladat és nem árt hozzá egy erőgép 









Új hozzászólás Aktív témák
Hirdetés

- Dell Latitude 7410 Strapabíró Ütésálló Profi Ultrabook Laptop 14" -80% i7-10610U 16/512 FHD IPS MATT
- Eladó Lian Li O11D MINI-X gépház
- Lenovo ThinkPad P17 Tervező Vágó Laptop -50% 17,3" i7-10750H 32/512 QUADRO T1000 4GB
- FSP DAGGER PRO ATX3.0(PCIe5.0) 850W Sfx tápegység
- Eladó PNY GeForce RTX 4070 Ti SUPER 16GB OC XLR8
- Bitcoin miner Bitmain Antminer S9 S9I 13.5 - 14 Th 1250W eladó
- AKCIÓ! ASUS PRIME Z390-P i5 8600K 16GB DDR4 512GB SSD RX 6600 8GB GDDR6 DEEPCOOL Matrexx55 630W
- BESZÁMÍTÁS! Gigabyte A620M R5 7500F 32GB DDR5 500GB SSD RX 6700XT 12GB Cooler Master CMP 520L 750W
- ÁRGARANCIA!Épített KomPhone i5 14600KF 32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- 124 - Lenovo Yoga Pro 7 (14IMH9) - Intel Core Ultra 9 185H, RTX 4060 (48 hónap garancia!) (ELKELT)
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest