Hirdetés
- iPhone topik
- Apple iPhone 17 Pro Max – fennsík
- Android szakmai topik
- Poco F8 Ultra – forrónaci
- Yettel topik
- Samsung Galaxy S20 és S20+ duplateszt
- Honor Magic8 Pro - bevált recept kölcsönvett hozzávalókkal
- Milyen okostelefont vegyek?
- One mobilszolgáltatások
- Poco X8 Pro Max - nem kell ide sem bank, sem akkubank
Új hozzászólás Aktív témák
-

prucam
tag
válasz
 dabadab
#2732
üzenetére
dabadab
#2732
üzenetére
# locale
LANG=hu_HU.UTF-8
LANGUAGE=
LC_CTYPE="hu_HU.UTF-8"
LC_NUMERIC="hu_HU.UTF-8"
LC_TIME="hu_HU.UTF-8"
LC_COLLATE="hu_HU.UTF-8"
LC_MONETARY="hu_HU.UTF-8"
LC_MESSAGES="hu_HU.UTF-8"
LC_PAPER="hu_HU.UTF-8"
LC_NAME="hu_HU.UTF-8"
LC_ADDRESS="hu_HU.UTF-8"
LC_TELEPHONE="hu_HU.UTF-8"
LC_MEASUREMENT="hu_HU.UTF-8"
LC_IDENTIFICATION="hu_HU.UTF-8"
LC_ALL= -
prucam
tag
válasz
 Jester01
#2722
üzenetére
Jester01
#2722
üzenetére
"Szerintem az a baj, hogy az awk print automatikusan rátesz egy sorvéget."
- igen ott lehet valami. Ld. később.Vagy állítsd be az ORS-t vagy használd a printf-et.
- ezeket még nem ismerem... ???Egy kicsit próbálgattam másképp. Eredmények:
itt beírtam a scriptbe a változót
1, egy szó keres
u2=Tom
grep $u2 $i
grep "$u2" $i
-mindkét grep keresés jó2, két szó keres
u2=Tom Sawyergrep $u2 $i
line 17: Sawyer: command not found
grep "$u2" $i
-olyan találatok amiben egyik megadott szó sem szerepel (szavak: Tom Sawyer)3, idézőjelek közé a változó
u2="Tom Sawyer"grep $u2 $i
(program exited with code: 2)
grep "$u2" $i
csak a megadott két szót keresi. Tökéletes!4,
u2="és a ha"
ez is szuper !!!Vissza az awk-hoz, egy szót keres:
1, utolsó oszlop
u1=`awk 'NR==1 {print $NF}' file`grep $u1 $i
(program exited with code: 1)
grep "$u1" $i
(program exited with code: 1)
A "print $NF" az utolsó oszlopnál, tényleg gond van.2, 3. oszlop
u1=`awk 'NR==1 {print $3}' file`
grep $u1 $i
ez jó eredményt ad
grep "$u1" $i
ez is3, két oszlop a 3. és a 4. (két szó: légy a)
u1=`awk 'NR==1 {print $3, $4}'grep $u1 $i
grep: a: No such file or directory
...
(program exited with code: 2)
grep "$u1" $i
(program exited with code: 1)
Egyik sem jó.megpróbáltam "cut" parancsot is:
u1=`head -1 file | cut -c9-21`
echo $u1
légy a szü
grep "$u1" $i
a grep-nél már hibát ír.Összegzés:
Ha két v. több szót keresnék az nem jó. (kivéve így: u2="Tom Sawyer")
Szerintem a váltózónál a ``-el lesz a gond.
Lehet ott is kellene a "" ? De hogyan ??? -
prucam
tag
sziasztok!
A változó megadásánál elakadtam. A file.txt első sorából az utolsó két oszlopot kellene másik file2.txt-ben keresni.változó:
u2=`awk 'NR==1 {print $(NF - 1),$NF}' file.txt`
(két szó lesz az eredmény)1, az echo-ra kiírja:
echo $u2
a motelben2, grep "$u2" file2.txt
hogyan kellene helyesen a grep-pel, az $u2-t megváltoztatni hogy jó legyen?3, próbáltam a $(u2)-es módszert ( `...` helyet ), de rossz találatokat ír.
-
prucam
tag
válasz
 bambano
#2208
üzenetére
bambano
#2208
üzenetére
x=/mnt/sdc10/home/iras/*
szerintem ez lesz a rossz. A kiterjesztés nélküli file-kre nem jó a "*". Így a mappák is (sőt még az almappák is!) benne vannak.
Hogyan kellene, azt nem tudom, írtam a linux-os topicba, valaki csak tudja.A "set-x" -es próbálgatom más scripteknél is. Nem tudtam, hogy van ilyen.

-
prucam
tag
Sziasztok,
most csinálok éppen egy egyszerű scriptet, ami hétfőnkét egy adott sort beszúr minden file-be.
#!/bin/bash
n1=`date +"%A"`
n2=hétfő
c=`date +"%V"`
n=`date +"%A"`
x=/mnt/sdc10/home/iras/*
if [ "$n1" = "$n2" ]; then
for i in $x;
do
echo "$c. $n #############################################" >> $i;
done
else
echo "Nem hétfő van!"
fi
exitMiután lefut ezt az üzit irja ki:
"./3_mi_a_neved: line 10: /mnt/sdc10/home/iras/: Is a directory"
Hogyan kellene javítani?
Az "iras" mappában csak kiterjesztés nélküli fájlok vannak.
A sok "#" karaktert hogyan lehetne rövidebben írni? (pl. 33#)
üdv
-
prucam
tag
válasz
bambano
#2195
üzenetére
"Nyilván a shell script is meg tudná számolni a sorokat. Mivel mindenhol csak első sorról beszéltél így nem tudtuk, hogy az is igény"
Az awk-nak nem kell a sort számolni!!!. Egyszerűbb ha bemásolom az adott sort egy üres file-be, azért NR==1.
1 az
2 awk
3 a
4 beolvasott
5 sort
6 a
7 mezőelválasztó
8 jeleknél
9 szavakra
10 tördeli
11 és
12 belerakja
13 a
14 $1,$2,...
15 tömbbe.
16 mire
17 van
18 még
19 szükséged?Hogy ezt csinálja az awk, mutassa a "tömböket". Másképp már nem tudom leírni.

-
prucam
tag
válasz
 Headless
#2192
üzenetére
Headless
#2192
üzenetére
Rendben. Egy kis magyarázat. Elnézést kérek.
Weblapokból, *txt-ékből, file-kből stb. szoktam az awk-val infót gyűjteni, főleg mondatkból. Néha olyan hosszúak a sorok (v. mondatok), hogy nincs kedvem "totozni" az awk-val, hogy most mezőben (mezőkben) van az info.
Ezért gondoltam arra, hátha van az awk-nak olyan funkciója, hogy mutassa meg melyik hányadik mezőben mi van.Saját egyszerű mondat pl.:
egy ketto harom negy ot
Végeredmény ez legyen:
1 egy
2 ketto
3 harom
4 negy
5 otA "read"-es megoldás jó nekem. Persze az adott sort nekem kell bemásolni a file-be. De mindig jobb mintha nekem kell számolgatni.
Az awk-nál meg van "NR==x" is, csak az adott sor számát kell "kitalálni":
Ennyi a magyarázat. Most érthetőbb?
-
prucam
tag
Jester
itt a script:
#!/bin/bash
b=abc
read -a fields $b
for((i=0;i<${#fields[*]};i+=1))
do
echo $((i+1)) ${fields}
doneaz abc file-ben:
egy ketto harom negy otMit csináltam rosszul? Nekem nem csinál semmit a script.
___________________________________________________________________
bambano
Megnyitottam az oldalt, de ez én szerény angol tudásommal nem sokra juttotam…
___________________________________________________________________Headless
nekem nem az x.mező ({print $3}), hanem az összes kell, s azt szeretném tudni hogy melyikben mi van.
Közben eszembe jutott egy másik lehetőség (ha más nem lesz akkor megpróbáljuk azt), de az "awk"-ás tetszik.
Köszi mindenkinek az eddigi segtíséget.
-
prucam
tag
válasz
dabadab
#1926
üzenetére
a sed-el lecseréltem a "."-t vesszőre a file-ben
sed -i 's/\./,/' fileFent leírtam nem egy számot, hanem több számról van szó (ami egy oszlop).
Próbálgattam, olvastam is. Ez jött össze:
awk '{ printf "%0.2f\n", $1 }' fileEz eddig szuper! Nekem kerekítés nélkül kell. Az melyik formátum?
-
prucam
tag
1.1106577778
2.3315178082
5
13.9737931034
24.7097560976
38.2903937008
60
98.7123076923
188.1471428571
320.815
709.17
1620.96
0
3525.588
0sziasztok,
kimásoltam egy táblázat-félét egy htm.-ből, s vannak egész és tizedesjegyű számok.
Hogyan lehetne ezeket a számokat, pontosan két tizedesjegyűvé alakítani?Ezt szeretném:
1.11
2.33
5.00
0.00
stb.köszi
Boldog Új Évet Kívanok!
-
prucam
tag
Sziasztok,
légyszíves segítsetek egy kicsit! Egy sort, hogyan lehet egy másik file első sorába beilleszteni?
Ezt sikerült összebarkácsolni:
w3m -dump 53.htm | grep -m1 "szoveg helye" | sed -i '1' > abc
De a "sed" csak fix szöveget illesztene be pl.:
sed -i '1itask goes here' abcNekem meg azt kelle amit "grep" -el megtalál.
Kicsit kerestem a google is, de nem igazán találtam ilyen példát. A "sed" helyett lehet hogy "ed" -et kellene használni?
Azt is néztem, ááááááááááHhhhá…üdv
-
prucam
tag
válasz
bambano
#1876
üzenetére
Sziasztok,
próbálgatom de nem igazán megy. Tudom, egyszerűbb volna ha minden file egy könyvtárban lenne.
Bambano, a könyvtár pontos elérését tudom. Nem értem a "find"-ot hogyan kapcsoljam össze:
find /mnt/mappa/mappa/mappa/tobb_mappa/ -type d | w3m -dump *.htm | awk …
v.
find …/tobb_mappa/ -name '*.htm' | w3m -dump | awk …Jester01
"De sokkal egyszerűbb a
w3m -dump /mnt/mappa/mappa/mappa/tobb_mappa/*/*.htm"Ez nekem az első két almappában dolgozik (azt tök jól!), a harmadikba már nem.
üdv
-
prucam
tag
sziasztok,
az awk-hoz kérnék most segítséget. *.htm file-kben keresek, itt a parancs:
w3m -dump /mnt/mappa/mappa/mappa/tobb_mappa/1-20/*.htm | awk '/*ty:*/ { print $0 }'
Ez jó megtalálja ami kell a "…/tobb_mappa/1-20/"-ban. De, van több almapa is.
…/tobb_mappa/1-20/
…/tobb_mappa/21-30/
…/tobb_mappa/31-40/
…/tobb_mappa/41-50/
… stb.Azt hogyan lehetne megcsinálni, hogy ne csak a "…/tobb_mappa/1-20/"-ban, hanem "…/tobb_mappa/" összes almappáiban is kerssen.
üdv
-
prucam
tag
Sziasztok,
szótördeléses megoldás lett a nyerő! Köszönöm bambano! Onnan meg már egyszerűbb, mert csak a számokkal kezdödő sorokkal viszgáljuk. Az ötletért köszönet dabadab-nak!
Utána grep-el megcsináltam a "leckét":
Hogyan lehetne kiszűrni, (pontos találatok kellenek):
1, az összes számot (egész, v. tizedes mind)
megoldás: cat abc | tr ' ' '\n' | grep "^[0-9]"
2, az egyjegyű-kétjegyű stb. számokat (egész számok)
megoldás kétjegyű: grep "^[0-9][0-9]" stb.
3, v. csak azokat amelyek tizedesjegyűek (a tizedesjegyek száma nem számít [de később kellhet, ezért azt is szeretném tudni])
megoldás tizedesjegyűek: grep "^[0-9],"Megint tanultam valamit.
üdv
-
prucam
tag
Sziasztok,
most számokkal kapcsolatban kérném segítségetek. Egy *txt fileben vannak vegyesen számok s szöveg.
Vannak:
1, egész számok: 1-1000-ig
2, tizedesjegyű számok: pl.: 1,1827000 stb.Hogyan lehetne kiszűrni, (pontos találatok kellenek):
1, az összes számot (egész, v. tizedes mind)
2, az egyjegyű-kétjegyű stb. számokat (egész számok)
3, v. csak azokat amelyek tizedesjegyűek (a tizedesjegyek száma nem számít [de később kellhet, ezért azt is szeretném tudni])Előre is köszönöm a segítséget!
üdv
-
prucam
tag
Végül is a "tr"-es megoldás lett:
cat file | tr '\n' '\t'
Egyébb:
- a "sleep" parancs mire jó, mikor használjuk?
- az awk-s parancsnál fent (#1771) beillesztettem script-be, s az lenne a kérdésem, hogy nem lehet-e azt megformázni; sor elejére igazítani (v. egy sorba az egész)?
-
prucam
tag
válasz
Jester01
#1771
üzenetére
Jester, köszi szépen az awk-s megoldást. Szuper!
Van egy file, amiben egy oszlopban vannak a számok. Valahogy így:
0.2121
1.21
3.423
1.23Nekem így kellene:
0.2121 1.21 3.423 1.23
Egy sorba, s az elválasztás köztük egy tabulátor legyen.
Azért próbálkoztam....pl.:
sed -i 's/\n/\t/' file
-
prucam
tag
Sziasztok,
ptc-zek s szeretném a reff-ek átlagát kiszámolni. Odáig eljutottam, hogy a .htm-ből megkapjam a sorokat:
Egy részlet, hogy néz ki:
....
17 [R781153008 ] 2014/05/27 at 22 days and 2014/05/ 7 1.000 [recycle] [info-r] [ ]
00:31 21:14 28
18 [R3325737139 ] 2014/05/27 at 22 days and Yesterday 7 1.000 [recycle] [info-r] [ ]
00:31 21:14
19 [R2656436594 ] 2014/05/27 at 22 days and 2014/05/ 4 0.571 [recycle] [info-r] [ ]
00:31 21:14 27
20 [R1966968045 ] 2014/05/23 at 17 days and 2014/05/ 2 0.182 [recycle] [info-r] [ ]A tizedesjegyű-számokat szeretném szűrni, de elakadtam:
grep -o [0-9].[0-9][0-9][0-9]
eredmény:
1.000
33257
37139
1.000
26564
36594
0.571
19669
68045
0.182 -
-
-
prucam
tag
-
prucam
tag
Szia,
köszi a segítséget!

Itt ülök kb. 30 perce, de nem igazán értem....

Egyszerűbben is lehetne?
Valahogy így:grep -v '[a-zA-Z0-9]' abc > abc_2
1. nem akarom törölni a karaktereket, csak tudni kellen mégis mi fordul elő a fájlban
2. nem kell, hogy hányszor fordul elő. Csak lista.üdv
-
prucam
tag
válasz
bambano
#1669
üzenetére
kipróbáltam rendezés nélkül:
# diff A_file B_file
6,7d5
< Dinnye Héja
< Kívül Zöld Belül Piros?
19c17
< Kobalt F1
---
> Kobalt F1
\ No newline at end of fileEz mit jelenthet: 6,7d5
a 6 és a 7 a sorok sorszámát. d5?
19c17: meg gondoloma file-k hany sorból állnakEgy darabig próbálgattom, de ez nekem megfelel. Majd megláttom mit szól az 5000 soros file-hez...
-
prucam
tag
Sziasztok,
lassan "farigcsálom" a sciptem, s szeretnék újra segítséget kérni tőletek.
Szitu:
- teljes soregyezést vizsgálunk
- van két file-m, egy hosszú (a_file), s egy rövidebb (b_file). Azt melyik paranccsal tudom megcsinálni, hogy "b_file" sorai közül melyik nem szerepel az "a_file-ben"?Készítettem egy képet is, hogy érthető legyen:
"a" és "b" file-k, csak a "b"-ben szerepel:
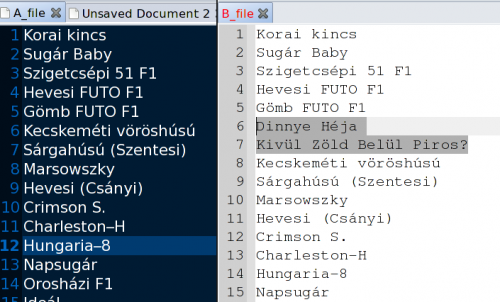
Dinnye Héja
Kívül Zöld Belül Piros?Ezeket szeretném eredményül. Légyszí segítsetek!
Köszönöm
-
prucam
tag
válasz
Jester01
#1562
üzenetére
Köszönöm.
A zárójeles az remek! Így talán egyszerűbb. Ez lett:Nick Fury - Zűrös csodaügynök 1998 DVDRiP XviD HUN-N&R
Halálos merülés 1997 CUSTOM HUN DVDRiP XviD-TOXI
Halálvadász és pokolbéli harcosok 1988 CUSTOM HUN DVDRiP XViD-TiGeR
Tüzes hó 1997 DVDRip Xvid HUN-BD
A Twister visszavág 1998 HUN DVDrip XviD-LIA
A kéz 1981 CUSTOM HUN DVDRiP DivX-TiGeRA szavak törlése helyett, azt kellene törölni mindig, ami az évszám után van. Ezt szeretném:
Nick Fury - Zűrös csodaügynök 1998
Halálos merülés 1997
Halálvadász és pokolbéli harcosok 1988
Tüzes hó 1997
A Twister visszavág 1998
A kéz 1981 -
prucam
tag
válasz
bambano
#1526
üzenetére
Igazából nincs olyan a Gnumericbe (nekem ez a verzió van 1.10.13), hogy "importálás"; csak megynyítás. Fent látható az eredmény, elég sok formázást kipróbáltam, de nem tudtam rájönni, hogy melyik a jó. Azért gondoltam a számok rövidítésére, hátha az jobban tetszik neki...
-
prucam
tag
Sziasztok,
van egy *.csv file amit szeretnék Gnumericbe importálni, valamiért nem igazán tud megbirkózni vele. Arra gondoltam egy scriptel kicsit meg kellene rövidíteni a tizedesjegyű-számokat talán sikerül.
Itt egy sor a file-ből:
"abc",4,344,2.3300000000000000,0.10174418575074364607,0.04651162777176852392,0.00961538452292899497,0.32051281640368184098,0.42857141836734718173,0.28571427891156478782,0.66666661111111574074,0.99999987500001562500,0.49999987500003124999,0.99999900000099999900,0.49999975000012499994,0.000000000000,0.000000000000,0.49999975000012499994,0.000000000000,0.000000000000,0.00000000000000000000,0.00000000000000000000,0.00000000000000000000,0.99999900000099999900,0.00000000000000000000,0.00000000000000000000,0.000000000000,0.000000000000,0.000000000000
Egyszerűen:szám,szám,szám stb.....
Minden számot két tizedesjegyűre kellene rövidíteni.
pl.:
2.3300000000000000, ezt erre 2.33, Segítene valaki?Előre is köszi!
-
prucam
tag
Sziasztok,
csináltam egy scriptet, amivel szöveget tudok majd keresni egyszere több doksiban. A "read" -del oldottam meg mit keressen, ha beírom "kilep" akkor kilép.
Ez egy keresésre OK. Azt hogyan tudom megcsinálni, hogy egymás után jelenjen meg a read sor (tehát adatot kérje be)?pl:
Keres:
vcjsd sdjbnc
sqjd ajdx ak
awq
dqwjd
Keres:
vdajhd ash
ba qwh
Keres:
xbak aha
aqwstb.
#!/bin/bash
b=kilep
c=/mappa/
echo Ugrás a mappába
cd $c
sleep 2
echo -n Keres:
read a
if [ "$a" = "$b" ]; then
exit
else
grep -h "$a" $c/doksi.txt $c/nem_doksi.txt
fi -
prucam
tag
sziasztok,
hogyan lehet a sortörést (\n) törölni? Pl.:ez van egy doksiban "1a2b3c4d"
a betűk után beszúrok egy sortörést
cat abc | sed -e 's/^.*1a2b3c4d/1a\n2b\n3c\n4d/'ez lesz:
1a
2b
3c
4dMost, hogyan tudom visszacsinálni a "1a2b3c4d"-t?
Nektek biztos uncsi, de már órák óta keresem a neten, de nem találtam a megoldást.
üdv
-
prucam
tag
Sziasztok,
próbálgatom a scriptet. Van benne egy "if", aminek az lenne a célja, hogyha van a letöltött filek között olyan, aminek a nevében "index" szerepel, akkor azt (v. azokat) törölje.
Most volt egy olyan "futása" amiben majdnem 10 is volt, s ezt az üzit kaptam:
./7_down_links: line 19: [: too many arguments
Nem törölt semmit. Mit kellene módosítani?
...
c="index*"
....
if [ -e $c ]; then
rm $c
echo "Az index.html törölve"
else
echo "Nincs index.html nevű file"
fi
....üdv
-
prucam
tag
válasz
bambano
#1463
üzenetére
grep '<title>' $d/$i | sed -e 's,^.*<title>[ ]*,,' -e 's,[ ]*-.*$,,' >> $d/title.txt
Ma próbáltam:
Bajok Harryvel
Az utolsó ítélet
Az utolsó kívánság
Bátorság próbaTökéletes! Ezt egyedül, nem találtam volna ki.
Azt elmondom, talán érdekel valakit mit is csinálok (ill. próbálok ?). Szeretnék egy olyan scriptet írni aminek lényege, hogy egy könyvtárba letölti a *html oldalakat, az infót kiszűri ami kell, másol, hozzáfűz stb. majd a végén *.rar-ba csomagol.
Sajnos, az egyszerűbb dolgokat még megoldom (v. utánézek a neten), de nem sok "lövésem" van a scriptekhez.
Amit egy hét alatt olvastam, az nem igazán elég, tudnátok-e továbbra is segíteni?üdv
-
-
prucam
tag
válasz
 MacCaine
#1451
üzenetére
MacCaine
#1451
üzenetére
alakul!
grep '<title>' $d/$i | cut -d ">" -f2 | cut -d "-" -f1 >> $d/title.txt
már csak az kellene, hogy a cím utáni részt is törölni. (kép mellékelve)
Sajnos, azt még nem tudom, hogyan kell szóköz v. sorvéget törölni (cf meg lf v. micsoda)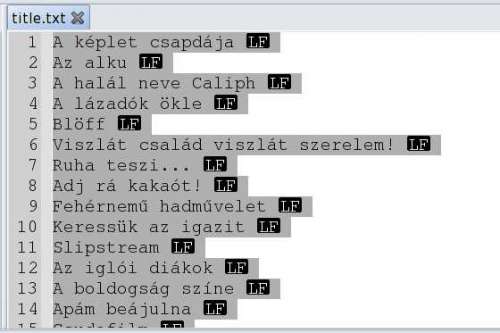
Ez legyen (egyelőre)
A képlet csapdája
Az alku
A halál neve Caliph
A lázadók ökle
Blöff
Viszlát család viszlát szerelem! -
prucam
tag
válasz
MacCaine
#1449
üzenetére
#!/bin/bash
d=/könyvtár útvonal
for i in `ls $d/`; do
grep '<title>' $d/$i >> $d/title.txt
done
exiteredmény:
<title>Gyilkos törvény - Fórum</title>
<title>Halálos érintés - Fórum</title>
<title>Motorlovagok - Fórum</title>
<title>Vízbe fojtott bűnök - Jindabyne - Fórum</title>
<title>Esküdt ellenség - Fórum</title>
<title>A bűncézár - Fórum</title>
.....Ez nekem eddig tetszik!

1, meg lehet-e adni úgy a keresést, hogy a "title.txt"-be csak a oldal címe legyen. Azaz:
Gyilkos törvény
Halálos érintés
Motorlovagok
Vízbe fojtott bűnök - Jindabyne
Esküdt ellenség
A bűncézár2, v. az elkészült "title.txt"-t kell tovább feldolgozni. Sed v. tr ??? Vagy hogyan?

-
prucam
tag
Sziasztok,
múlt héten kezdtem el foglalkozni a scriptekkel, azaz semmihez sem értek.
A fórumot azért elolvastam az elejétől!
Meg mást is olvasgatok néha.Szeretnék írni egy scriptet, ami a weblapok címét (nem URL), elmenti. Tehát az oldal html kódjában ez van:
<title>A nagy shell script topik - PROHARDVER! Hozzászólások</title>
Gondoltam:
w3m http://prohardver.hu/muvelet/hsz/uj.php?thrid=162198 | grep '<title>' >oldalcim
de ures a doksi. Sajnos nics elképzelésem, hogyan is kellene megoldani. Segítenétek?
köszi

























Új hozzászólás Aktív témák

- Kaspersky, BitDefender, Avast és egyéb vírusírtó licencek a legolcsóbban, egyenesen a gyártóktól!
- Bitdefender Total Security 3év/3eszköz! - Tökéletes védelem.
- Vírusirtó, Antivirus, VPN kulcsok GARANCIÁVAL!
- Windows 10/11 Home/Pro , Office 2024 kulcsok
- Game Pass Ultimate előfizetések 1 - 36 hónapig azonnali kézbesítéssel a LEGOLCSÓBBAN! AKCIÓ!
- LG 27GX790A - 27" OLED evo / 2K QHD / 480Hz & 0.03ms / NVIDIA G-Sync / FreeSync / DP 2.1 / 1300 Nits
- Xiaomi Redmi Note 12S 256GB, Kártyafüggetlen, 1 Év Garanciával
- AKCIÓ! Intel Core i7 4790K 4 mag 8 szál processzor garanciával hibátlan működéssel
- Motorola Edge 50 Neo 256GB,Újszerű,Dobozaval,12 hónap garanciával
- AKCIÓ! Sony PlayStation 4 PRO 1TB fekete játékkonzol garanciával hibátlan működéssel
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest