- Motorola Moto G72 - a titkos favorit
- Mobil flották
- iPhone topik
- Bemutatkozott a Poco X7 és X7 Pro
- Hivatalosan is bemutatta a Google a Pixel 6a-t
- Megjelent a Poco F7, eurós ára is van már
- Fontos fejlesztéssel érkezik a Galaxy A17 5G
- Samsung Galaxy Watch (Tizen és Wear OS) ingyenes számlapok, kupon kódok
- Samsung Galaxy Watch4 és Watch4 Classic - próbawearzió
- Yettel topik
-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

stratova
veterán
válasz
 leviske
#15465
üzenetére
leviske
#15465
üzenetére
Szvsz kezdetben nem is fogják ha 2017-ig nem lesz Zen alapú APU.

Jó esetben 2016-ban piacra kerül HEDT-nek/szervernek Zen alatta pedig egy max. i3/i3T szintig skálázódó Bristol Ridge husi IGP-vel, ami jó áron egy rétegnek érdekes lehet esetleg az OEM-ek láthatnak benne fantáziát (lásd lejjebb). De Zen nélkül még kár lenne efeletti kategóriát kergetni, addig egyszerűen értelmetlen.
Tudom hogy volt már, nem tudom mennyire spekuláció vagy kacsa. De mintegy elvárt lépés, hogy AM4-be egy i5-i7 ellenfél APU is helyet kapjon:
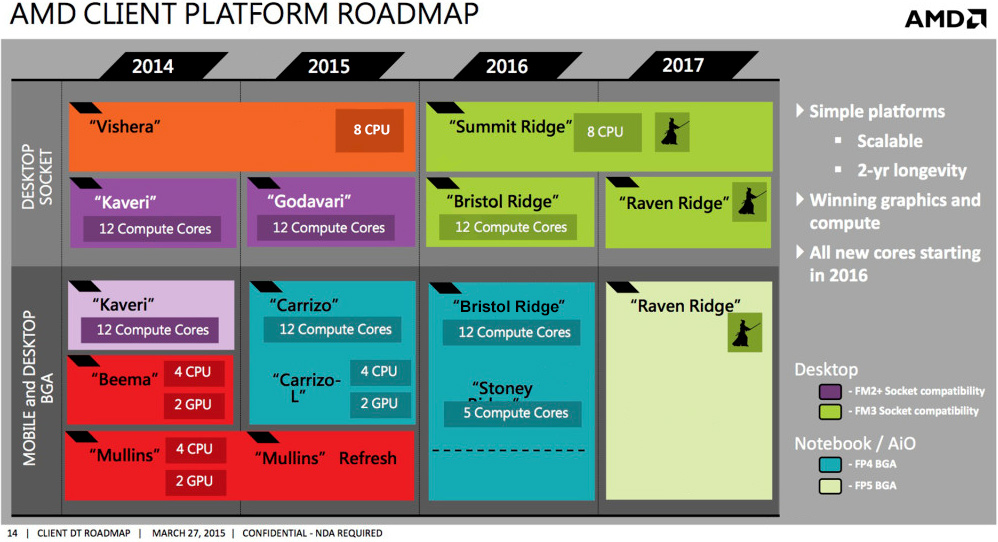
Most ugye AMD i5-i7 ár környékén FX-et ad, más kérdés hogy amilyen áron adja nem kell senkinek (meg lassan sajnos amúgy se). Te pl. vennél boltból 60-ért FX-8370-et amikor i5-4590-et is kapsz ennyiért vagy FX-8350 árban i5 4440-et a kettő között aka FX-8370E pedig i5-6400-at kapsz? FX-8320E és FX-8320 gyakorlatilag i3 árban megy FX-6300 pedig olcsóbb nála.
A jelenlegi asztali FX eladásuk nem sokban különbözik lassan attól, mintha nem is lenne az adott ategóriában procijuk.
-
stratova
veterán
válasz
leviske
#15460
üzenetére
Szvsz szinte kizárt, hogy 4.5 GHz-es lapkával tudjanak elsőre előállni 14 nm-en. Ez nem egy SHP node. Ha 3.5-3.8 GHz akár csak turbó szinten összejön (~3 GHz alap órajellel) már összetehetik a kezüket AMD-nél. Még Intel első 14 nm-es node-ja, sem tudott ilyen órajeleket, nem véletlenül kezdték ULV-vel.
Sem TSMC sem Samsung / GloFo nem skálázza olyan szintre ezt a node-ot, amilyen a 32 nm SHP és 28 nm-en sem ment elsőre 4 GHz alapórajel (épp emiatt kapott anno Kaveri, hogy visszalépés volt ebben a tekintetben Richland-hez képest).
Bár az AMD szempontjából érdekes félvezetőgyártók ügyfelei jelenleg csak alacsonyabb fogyasztású ARM lapkákhoz viszonyítanak (amit ennek megfelelően terveznek), de ilyenek az ott jellemző/várható órajelek.
TSMC:

Samsung/(GloFlo)
Snapdragont 820-at először akár 3.0 GHz-esnek rebesgették végül 2.2 GHz-en ketyegő magokkal debütált.Ha esetleg a 14 nm LPP-n el lehetne érni egy 3.0@3.7 GHz órajelet, már így is nagyon szép eredmény lenne. Utóbbi pl i7-5775C max. turbó órajele, ami 2015.06.02-án jelent meg szemben az első 14 nm-es Core M 5Y70-nel (2014.09.05). Ehhez képest ugye Skylake tovább fejlődött.
Olyan órajelet, amiről ábrándozol talán 22 nm FD-SOI mellett lehetne elérni, de AMD nem abba az irányba vitte most a tervezést, ők következő lépcsőnek valószínűleg a 10 nm-t tekintik Synopsis-szel kötött megállapodásuk alapján.
Egy Elitebook 7x5 G2/G3 most is szépen át tudja lépni a 1000$-os határt.
-

Fiery
veterán
válasz
leviske
#15455
üzenetére
Ha a jovo ev kozepen mar megjelenne a (Zen alapu) Raven Ridge APU, akkor mi ertelme lenne vacakolni a(z Excavator alapu) Bristol Ridge-dzsel? Es az AMD, amiota csak a Zenrol beszel (nekunk ill. kesobb publikusan), azota mondja, hogy elso korben a szerver es HEDT CPU-k erkeznek. Azokon a piacokon van a legnagyobb elmaradasban az AMD, es azok a piacok azok, ahol me'g manapsag is lehet penzt csinalni. A mainstream desktop/notebook szegmens egyre jobban zsugorodik, mig a szerverek tovabbra is jol huznak. A HEDT es ugy altalaban pedig az enthusiast desktop (gaming) szegmens szinten nem megy rosszul, bar az mindig is niche (azaz szuk) piac volt -- de legalabb nagy marginokkal.
GPU-k: igen, igazad van, nem fogalmaztam egyertelmuen. A legujabb GCN alapjara epitve kellene 14/16 nanon kihozni 4 db uj GPU generaciot.
-
Fiery
veterán
válasz
leviske
#15391
üzenetére
"Elvégre valamennyire a Kaveri-t is biztos viszik"
Sajnos nem. Baromira nem viszik, se desktopon, se mobil vonalon.
"hiszen más esetben már rég valahol $90-110 környékén lenne a csúcsmodell."
Akkor mar boven buknanak minden egyes eladott APU-n, annak meg mi ertelme lenne? Az ugye megvan, hogy mekkora a Kaveri die? 245 mm2, 28 nanon. Anno a (4 magos, GT2 iGPU-s) Sandy Bridge volt 216 mm2, az Ivy Bridge 160, a Haswell 177, a Skylake most 122. Nyilvan nem ugyanaz a processz, nem ugyanaz a GPU teljesitmeny, de akkor is jol lathato, hogy az Intel mar tobb generacioval ezelott is kisebb die-bol tudta kihozni a nagyobb (x86 CPU-) teljesitmenyt, megis tobb penzt tudott kerni erte, mint az AMD. A mostani Kaveri mag duplaja a Skylake-nek, ezert keptelenseg fillereket kerni, mikozben a gyartas sokkal dragabb, mint a konkurens CPU-k eseteben

-
Fiery
veterán
válasz
leviske
#15383
üzenetére
En arra gondoltam, hogy ha felvasarolja az AMD-t a Microsoft, es o nem lat fantaziat a Zenben, akkor mehet a kukaba a Zen. Erre nagyon-nagyon kicsi eselyt latok. Az AMD nem fogja nyilvan leloni a Zent, igy a projekt vegehez kozeledve. Bar, megcsinaltak ezt mar nehany projekttel, de azok nem a ceg fennmaradasanak kulcsai voltak anno.
"Az lehet, hogy az Alienware megállapodás piszlicsáré, de azért vedd figyelembe, hogy sokszor ilyen piszlicsáré üzletek befolyásolják egy gyártó megítélését"
Ja, meg a Fury Nano fiasko, a masik iranyba. Sz'al 0-0 az allas, maradjunk ennyiben

"az Alienware is csak Radeonon nyújtja a VR megoldásait, lehet hogy inkább Radennal szerelt notit vesz, még akkor is, ha nem az említett két gyártótól teszi. Ugyanúgy presztízsértékűek az ilyen piszlicsáré ügyletek, mint a zászlóshajó megoldások konkurenciához viszonyított ereje."
Ebben nem ertunk egyet, de elfogadom az erveidet. A VR megint tipikusan a jovonek epitkezes esete, ami az AMD-nel az utobbi idoben ugyanugy nem jott be, mint a jelennek valo epitkezes. Sz'al en ugy vagyok vele, hogy majd ha jon a VR, es erkeznek a jatekok es keszulekek, akkor majd meglatjuk. Csak aztan nehogy a semmibol elotunjon egy AGEIA-szeru vallalkozas, es lesoporje az AMD, Intel es nVIDIA nagy remenyu VR-es probalkozasait

"skálázva is valószínűleg elég lenne 15-20W-os TDP ahhoz, hogy indulhasson egy ITX alaplap dömping AM4 alapon."
Megint egy qrva vekony piaci szegmenst peceztel ki. PC = haldoklik. Desktop PC = plane haldoklik. Desktop PC mini-ITX = plane. Es akkor me'g vegyuk be a mixbe, hogy AMD proci, DDR4 es socketelt megoldas raadasul. Hat nemtom... Ennyi erovel, ha olyan nagy igeny lenne 15-20W-os mini-ITX megoldasra, mar most is ott a Carrizo, be lehetne vetni. Hol van az ASRock mini-ITX deszkaja vagy Vision HT miniPC-je, Carrizo alapokon? Hol vannak a Zotac Zbox-ai Carrizo alapokon? Gondolod, hogy csak azzal, hogy berakod egy AM4 socketbe a Carrizot es pakolsz melle DDR4-et (amit mar most is lehetne a Carrizo melle rakni!), es atnevezed a hangzatos Bristol Ridge-re, majd hirtelen mindenki azt akar venni? Ne vicceljunk mar...
-
Fiery
veterán
válasz
leviske
#15376
üzenetére
Amikrol beszelsz, mint strategiai megallapodasok, nos, azok borzaszto reteg termekek, nagyon szuk piacok. Egy AMD vagy epp nVIDIA nem ilyenekbol fog megelni. Az AMD most a leesett morzsakat probalja felcsipegetni, ilyen volt anno a konzol biznisz is. A tobbi gyartonak egy csomo penzt es eroforrast kellett volna beleraknia, nem erte meg nekik foglalkozni az egesszel, mert a vegen tul keves penz jott volna vissza belole. Az AMD-nek megvannak a kompetenciai, de azokbol nem ilyen vekony profittal kecsegteto piacokat kellene szerezniuk, hanem a tomegek igenyeit kellene kielegiteni. Ez pedig mar egy jo ideje nem sikerul nekik, sajnos. Az ilyen piszlicsare kis bizniszek maximum arra jok, hogy kicsit fekezzek a lejton lefele valo szaguldast.
Az Apple meg olyan mint a rossz **rva: egyszer ebbe ulok, egyszer abba. Most epp az AMD kinalt fel nekik pici penzert valami erdekes cuccot, igy most azt valasztottak. De semmi garancia nincs ra, hogy ha megjon a Pascal, nem fog azonnal valtani az Apple megint. Ugyanezt csinaljak a gyarto partnerekkel (a Samsungot es a TSMC-t egyszerre futtatjak most az A9 kapcsan), ugyanezt csinaljak a kijelzok es minden mas komponens kapcsan is. Aki epp a legjobb ajanlatot adja, oda viszik a bizniszt. Most epp az AMD adott egy jo ajanlatot, most ok kaptak meg az uzletet.
"de azt azért nem hiszem, hogy olyan projekteket állítanának le, mint a Zen"
Ki mondott ilyet? Ez fel sem merult, se az AMD-nel, se masnal.
"Emellé már csak a Bristol-t kéne megfelelő órajelekre belőni a Kaveri-nél átgondoltabb árakon"
SZVSZ ez keptelenseg. Marmint, az orajeleket nem fogjak tudni az egekbe tolni, kellene cca. 5500-6000 MHz ahhoz, hogy a Skylake elleneben labdaba tudjon rugni a desktopon a Bristol Ridge. Lefele skalazva pedig szinten kotve hiszem, hogy 10W ala be tudna nezni a Bulldozer architektura. Nagyjabol annyira lesz izgalmas es nepszeru a Bristol Ridge, mint a Richland utan a Kaveri. 10-15% itt-ott, nem szamottevoen magasabb orajelekkel, esetleg 2 plusz CU az iGPU-ban, oszt annyi. Nyilvan egy Llano vagy egy P4 utan remek valasztas, de az ilyen juzerekbol eddig sem elt meg tul jol az AMD
"Az Apple-nek több az elszórni való pénze, ha már a lehetséges lehetetlen felvásárlásokat soroljuk"
Az Apple-nek maximum a GCN miatt lenne erdekes az AMD. A GCN-nel viszont az a baj, hogy nem nagyon epult ra konkret mobiltelefonban mukodo termek, amivel lehet haknizni. Volt ugye az Amur, ami a fiokban vegezte. Ha az Amur elkeszult volna, azzal mar lehet hogy meg lehetne gyozni egy potencialis felvasarlot a GCN mobilpiaci erejerol. Mar ha tenyleg olyan franko lenne a gyakorlatban is, pl. egy androidos telefonban.
-
Fiery
veterán
válasz
leviske
#15373
üzenetére
Nem realis? Lassuk, pontonkent:
1) "Microsoft/Sony/Nintendo konzolokat építenek a termékeikre" -- ha a Microsoft veszi meg az AMD-t, akkor a Microsoftnak mar csak gyartanak tovabbra is konzol APU-t
A Sonyval es a Nintendoval meg lehet allapodni, egyszeru szerzodes modositassal, nem nagy kaland. A Samsung is gyart a konkurencia (Apple, Meizu) reszere SoC-okat, a Microsoft miert ne tehetne?2) "az Apple most váltott Radeonokra" -- es? Ki mondta, hogy a Microsoft beszunteti a Radeonok gyartasat? Ha meg gyartjak oket, miert pont az Apple-nek ne lehetne eladni oket? Vagy arra gondoltal, hogy milyen oriasi mennyisegu penz folyik be az AMD-hez evi partizezer, Mac Pro-ba szerelt FireProbol?
Tenyleg hatalmas love lehet, csak fel kell szorozni a partizezret 1000 dollarral -- annal tobbet nem keres az AMD me'g egy FirePron sem. Egy 2 milliardos market cap. cegnek lof*** semmi az a penz, ami egy ilyen reteg termekbol befolyik, az nVIDIA sem csupan a Quadrokbol el.3) "A Hynix is gyakorlatilag a jövőjét jelentő technológiával eléggé az AMD-re támaszkodott partneri szempontból." -- es? Ki mondta, hogy a HBM-et nem fogja megvasarolni a Microsoft, ha a jovoben ugyanugy keszitenek Radeon dGPU-kat? Plusz, legyen ez az adott cegek problemaja. Vagy arra gondolsz, hogy majd pont a Hynix fogja megfurni a felvasarlast? Nem valoszinu. Minden csak lepapirozas kerdese.
4) "Ráadásul a Zen-ről is folyamatosan szivárognak olyan infók, amik alapján látható, hogy végre nem a piac aktuális trendjeivel szemben indultak" -- mi koze a Zennek ahhoz, hogy 2016 vegeig mi tortenik az AMD-vel? A Zenig _semmi_ atuto bejelentesuk nem lesz. Me'g erkezo high-end dGPU-rol sem lehet hallani semmit. A Fiji mar masfel-ket evvel a megjelenese elott elkezdett szivarogni, most mit lehet hallani a Fiji utodjarol? Azon kivul hogy 14/16 nano, HBM2, ami mindketto teljesen logikus es elvarhato 2016-ban, na de azon kivul? No meg aztan elnezve a cca. 24%-rol 0 fele konvergalo AMD dGPU piaci reszesedest, azon belul pedig figyelembe veve a high-end kartyak reszaranyat, vajon mennyi baber terem az AMD-nek me'g ha ki is hoznak egy Fiji utodot mondjuk majusban? Mit szamit az a teljes ceg tulelese vagy sorsa szempontjabol?
5) "az FTC nem engedne meg olyan felvásárlást, ami egyszerre 2 gyártót tesz a saját piacán végérvényesen monopol helyzetűvé." -- bocs, de fogalmam sincs, milyen gyartokrol beszelsz. Ha az AMD egy USA-beli gyarto, a Microsoft is egy USA-beli gyarto, akkor nem tok mindegy, hogy kinek a kezeben van a 2. x86 licenc? Es egyebkent ki a 2. gyarto? Mert elsonek gondolom az Intelre gondoltal, ami nem nyert
Nyilvanvaloan az AMD-t felvasarlo ceg tovabb gyartana az x86 processzorokat es a dGPU-kat is, ez a felvasarlas nem arrol szol, hogy kinyirjak az AMD maradek kompetenciajat is. Ha ez lenne a cel, akkor eleg csak megvarni, amig a szakadekba kormanyozza magat a ceg, nem kell kidobni ilyenre az ablakon 2 milliard USD-t sem.6) "A Microsoft is csak saját magát lőné tökön, ha azt a gyártót ütné ki, akinek a technológiáira kezdett el alapozni a Windows 10 és Xbox One kapcsán" -- ennek plane nincs ertelme. Miert akarna kiutni azt a gyartot a Microsoft, akit felvasarol? Nem ertem a logikadat. Vagy arra gondolsz, hogy egy ilyen lepessel az Intelt magara haragitana a Microsoft? Ez csupan papirozas kerdese. A szinfalak mogott, az x86 licenc transzfer kapcsan boven lenne mirol megallapodni, es az Intel szamara is lehetne olyan jovobeni utitervet prezentalni, ami oket sem zavarna annyira. Pl. egy fixen 10 evig szolo x86 licenc, ami nem megujithato. Addig lenne ideje a Microsoftnak atallni ARM-ra, elvarrni a mostani szalakat (konzol APU-k), stb. De nem is kell feltetlenul ilyen radikalis tervre gondolni, van az a penz es jol megfogalmazott jogi szoveg, amivel egyutt 20-30 evig is maradhatna masodik x86 szereplo a Microsoft -- ha akar. Ha van 2 olyan ceg, ami meg tudna allapodni egy ilyen kenyes kerdesrol (mint az x86 licenc transzfer), az az Intel es a Microsoft. Hatalmas kozos multjuk van, rengeteg mindenen keresztulmentek egyutt, folyamatosan egymast nyomatjak, ok meg tudnanak allapodni egy AMD felvasarlasrol, ebben biztos vagyok. Abban mar nem annyira, hogy a Microsoft tenyleg fel akarja vasarolni az AMD-t, de 2 milliard dollarert szerintem ajandek lenne a ceg
-
Fiery
veterán
válasz
leviske
#15362
üzenetére
En nem varom jovo ev novembere/decembere elott a Zent. Nem tartom realisnak a korabbi rajtot, de nagyon orulnek neki, ha nem lenne igazam.
A tavaszi AM4 platform rajtot a desktop Carrizoval (Bristol Ridge / Stoney) en is realisnak tartom, bar tavaszon belul inkabb a tavasz vegere tenném, azaz majusra.
-

Laja333
őstag
válasz
leviske
#15339
üzenetére
Miért ilyen drágák ezek? :/ szeretnék venni egy jobb kaveri/carizzo laptopot, de ami tényleg megütné a szintet, az 300e fölött van. Egy hasonló teljesítményt megkapnék intel+nvidiával 220-230e-ért. :/
Másrészt általában Lenovo ami kaveri. Ezeket mennyire érinti ez a spyware-gate? -
Fiery
veterán
válasz
leviske
#15326
üzenetére
A 6700K hivatalos TDP-je 91 Watt tovabbra is.
"akkor miből következik az, hogy egy 2,5-3GHz-re belőtt lapka az AMD esetében feltétlenül 160W-os termékeket eredményezne 3,8GHz-en?"
6700K: 4 mag, Zen HEDT proci: 8 mag. Nagyon nem mindegy. Az Intel-fele HEDT termekek (pl. 5960X) sem 91 Wattot zabalnak.
A mobil Zen siman lehet, hogy mas eljarassal, adott esetben mas gyarto altal fog keszulni. Ergo en nem kevernem ossze a "nagy" Zennel, nincs is jelentosege a jovo evet nezve.
-
#15212
 Petykemano
veterán
leviske
#15211
Petykemano
veterán
leviske
#15211
Petykemano
veterán
válasz
leviske
#15211
üzenetére
A legózásra jó válasz, amit mondasz, elfogadom. Az, hogy az intel átállt monolitikusra szerintem inkább abból fakadhat, hogy úgy olcsóbb a gyártás, mint utólag összepakolni. Az ötlet csak onnan jött, hogy hát ha a HBM miatt úgyis kell...
Egyébként az intel eDRAM-ja nem összetokozott megoldás? Hogy oldják meg interposer nélkül mégis élhető késleltetéssel?
Szerintem a kép lehet az sAMD-é. De inkább tartom valószínűbbnek, hogy ez a kép a 2017-ben érkező HPC APU illusztrációja, vagy a Facebooknak talán készülő semi-custom apué, semminthogy tényleg egy 2020-2025-ben elkészülő szuperszámítógépé. Sematikus rajz persze lehet, de ugye akkor nem szabad a képen szereplő különböző feliratokkal ellátott dobozok számából következtetést levonni.
Az a bajom nekem ezzel a HPC APU-val, hogy egyelőre nem világos számomra ennek a piaca, ill felhasználási területe. Ha a facebook venne egy ilyet, azt értem, ők meg is csinálják hozzá a szükséges szoftvereket is (persze ha mondjuk a módosításaik a linuxba, a mysql-be, memcache-be, stb, amiket használnak és hasznot hajt, átkerülne, az tudna adni egy lökést, de akkor még mindig át kéne nyomni valahogy a szervervirtualizáción, amerre most ugye halad a világ.). A JAva 9 támogatja a HSA-t. ok. kettő.
Szerintem hogy kell-e HBM, vagy bármi, ami... az világos, hogy 512 shadert etetni a DDR3 alig-alig tudott, és a DDR4+DCC együtt talán már fogja tudni. Ezen felül valamilyen megoldás kell, 4 csatorna, HBM, vagy bármi, egyelőre úgy láttam, senki nem tudott semmilyen értelmes és megfizethető elgondolást felmutatni. De csak akkor van szükség bármilyen sávszélességnövelő megoldásra, ha továbbra is megmarad az APU IGP olcsó GPU-nak. Koprocesszorként használva, mint amilyen a HSA, vagy DX12-ben a postprocesszing , valószínűleg a sávszélesség sokkal kevésbé égető.
Szerintem az AMD magától nem menne el abba az irányba, hogy növelje a maintream apukan a shaderek számát, ez az egész olcsóGPU-s APU csak egy köntös az átmeneti eladhatóságért. Az IGP célja valójában a koprocesszorkodás. A grafikai teljesítmény növelésére egyedül az intel kényszeríthetné rá. De szerintem hiába láttunk fantasztikus IGP teljesítményt a Broadwell C-ktől, szerintem ezt nem fogja lehozni az i3 és az AMD APU-k szintjére. Pont azért, mert ha mégis bejön a GPGPU, akkor ki lenne az hülye, aki 3-4x annyiért venne 10-15-20%-kal több tflops-t?
-
#15210
Petykemano
veterán
leviske
#15209
Petykemano
veterán
válasz
leviske
#15209
üzenetére
Hát mivel eddig egy Apu 512 shader (4cpu+8gpu mag) etetéséhez szükséges memória lehetőségekről beszéltünk, hogy ehhez hbm kéne, de az meg drága az interposer miatt, ezért szerintem a fiji 4k shadere böszme nagy. Mondjuk az igaz, hogy nem csak csupán a fizikai kiterjedésére, lapkaméretre gondoltam, inkább a számítási kapacitásra is.
Úgy érzem érdemi válasz nélkül túlbeszéltük ezt az összelegózásos kérdést.
-

zoli7903
csendes tag
válasz
leviske
#15123
üzenetére
HP ENVY - 15z már van 500 dollár
HP Pavilion 17.3" Laptop - Silver elvileg ebben a hónapban
Toshiba Satellite P50D-C valamikor a 3. negyedév
-
-
Fiery
veterán
válasz
leviske
#15068
üzenetére
Az FM2+ Bristol Ridge kemeny dio, ott nem tudom, milyen orajeleket fognak tudni elerni. De velhetoen a Godavari orajeleit azert tudjak hozni, kulonben nem sok ertelme lenne az egesz procinak. AM4-be ha berakjak, ott viszont _lehet_, hogy 120-130W koruli TDP keretet fognak biztositani, abba pedig beleferne me'g nehany erdekes huzas, pl. magasabb orajel vagy tobb mag.
-

Oliverda
titán
válasz
leviske
#15068
üzenetére
"abból kiindulva, hogy a fejlesztések ellenére is csökkenteniük kellett a FX-8800P órajeleit a FX-7600P viszonylatában azonos TDP keret mellett"
GPU base frequency: 600 -> 800 (+33,33%)
Legfeljebb a CPU magok órajeleit...
"Amúgy Október/November táján már nem logikusabb volna AM4 lapokat kiszórni és a Bristolt is olyan tokozással kiadni, időt hagyva a gyártóknak, hogy felkészüljenek kész termékeken a Zen érkezésére?"
Nyilván rengetegen szaladnának értük a boltokba, hogy megvegyék mellé a drágább DDR4-es RAM-okat, amikor a Zen még legalább 1 évvel odébb van...
-
stratova
veterán
válasz
leviske
#14544
üzenetére
Szerintem ezt csak tippelni lehet
 de mi értelme lenne korlátozni a szoftvert Kaverin?
de mi értelme lenne korlátozni a szoftvert Kaverin?
Egyenlőre nem a túlkínálat jellemző az AMD APU-s termékekre...
Nézelődtem kicsit Berlinről, több cikk is lehozta, hogy teszteltek vele a Red Hat Summit alkalmával de sehol egy piaci termék (Red Hat támogatási listán pedig Opteron X2150 a legújabb AMD APU, ami Kabini alapokon nyugszik) vagy hivatalos teszteredmény.
Utóbbiról egyébként Gary Frost bejegyzése tesz említést.Ami nekem furcsa, miért kellene "szupertitkolni" pl. a Java9-es teljesítményjavulást, ha már korábban is ~5x sebességnövekedést mértek GPGPU-val.
Berlin elérhetetlenségének szvsz az lehetne még a magyarázata: ha kimondottan HSA-ra koncentrálnak, minek kezdenék meg egy régebbi (Kaveri/Berlin) korlátozottabb képességű [lásd. 30:42] szerver termék forgalmazását, amikor elvileg a végső simításokat végzik az utódon (Carrizo/Toronto). Másrészt ha esetleg "egészen véletlenül" Carrizo/Carrizo-L közös BGA foglalata egyezik a Skybridge projektben felvetettel - ahol közös foglalatot kap ARM és x86 - akkor megspóroltak egy foglalat validálást (FM2+).Ezzel mondjuk így pepitában megcsinálták ugyanazt, ami miatt az Intel szapulva volt a LGA1056>55>50 miatt.
Azért egy kicsi "engedményt" tettek. FM2+ lapba még betehetsz Trinityt is. Így cserélte le kollégám FM2 lapját garanciában FM2+ra. Ha Kaveri refresh hoz érdemi változást az első modulos APU-hoz képest (itt A10-5800K), értelmet nyernek azok a - még jó áron vett - 2133 vagy 2400-as RAM-ok.
-
stratova
veterán
válasz
leviske
#14291
üzenetére
Ebben a kivitelben aligha. Ha megnézed az ezzel párhuzamos Elitebook 8xx Intel vonal 15 W TDP-s APU-kkal operál. Ez a vékonyság ára. Bár A10 PRO-7350B eleve nem rossz kivitel.
A10 PRO-7350B ~= FX-7500 4 mag
2,1/3,3 GHz 2 x 2 MB 1600 MHz 384 (R6) 498/553 MHz 19 WA8 PRO-7150B ~= A10-7300 4 mag
1,9/3,2 GHz 2 x 2 MB 1600 MHz 384 (R5) 464/533 MHz 19 W35 W TDP-s APU-t csak a vaskosabb Probookok kaptak mindkét gyártó esetében. Ebből a legmagasabb szintű a Probook 645/655 volt, de nálunk csak A4 (talán A6) Richlanddel volt kapható. A komolyabb konfiguráció kb. USA, Ázsia területére korlátozódott. Kíváncsian várom az importőr/nagykerek mennyire tesznek keresztbe az AMD-s verziónak.
-
Fiery
veterán
válasz
leviske
#14293
üzenetére
Ja, mar latom, hogy mitol hasznalhatatlan ez a tablazat
250 watt TDP-t ir mindegyik Tahiti es Hawaii variansra Igy nem csoda, ha egy alacsony orajelen jaro, letiltott shaderes Tahiti ilyen rossz GFLOPS/W erteket kap. Az egesznek akkor lenne ertelme, ha pontosan ismernenk a max. terhelesen jaro GPU-k fogyasztasat. Igy meg maximum arra jo, hogy teves kovetkeztetest vonjon le az ember a Tahiti --> Hawaii update-rol. No offense -
Fiery
veterán
válasz
leviske
#14291
üzenetére
"Az eddigi hozzászólásaimat azzal egészíteném ki, hogy én az új architektúrát 1 évvel a Carrizo után várnám, a Skylake-el nagyjából egy termékciklusban"
Ugy legyen! Bar egy olyan vilagban, amikor mar az Intel sem tud mar evente uj core-t prezentalni, furcsa lenne, ha az AMD kepes lenne erre. Az evente alatt pedig azt ertem, hogy 12 havonta. A honapokkal mindig kicsit odebb tologatas nem eventet jelent, me'g akkor sem, ha even belulre esik, par generacion at legalabbis
"A Tonga esetében meg fontosnak tartom figyelembe venni, hogy a Tahiti-hez képest a Hawaii majdnem dupla GFLOPS/W értéket hozott"
Nem astam bele magam ebbe tulsagosan, nem is szamoltam utana, de az itt lathato tablazatok alapjan en ezt talaltam:
HD 7970 (Tahiti): 15.155 GFLOPS/W
HD 7970 GHz Edition (Tahiti): 17.2 GFLOPS/W
R9 290X (Hawaii): 19.4206 GFLOPS/WEz hol duplaja? De lehet, hogy rosszat neztem, ez esetben sorry.
"Szóval egyáltalán nem lehetetlen, hogy nem csak kisebb lapkaméretet, de kisebb fogyasztást is hoz azonos teljesítmény mellett."
A Hawaii nagyobb lapka, mint a Tahiti, de teny, hogy a teljesitmenye is nagyobb. Azt egyebkent nem ketlem, hogy az AMD meg tudja oldani, hogy a Carrizo valamivel nagyobb die-jal, alacsonyabb TDP-vel is tudja hozni a Kaveri iGPU teljesitmenyet majd (legfeljebb mashol tekeri lejjebb a procit), en csupan azzal kapcsolatban tamaskodok kicsit, hogy az iGPU teljesitmenyt marginalisnal nagyobb mertekben fogja tudni fokozni a csokkeno TDP-vel is.
-
Fiery
veterán
válasz
leviske
#14287
üzenetére
"pont az Inte-haver HP kapcsán olvastam (és korábban említettem is), hogy szeretnének az Inteltől és Redmondtól függetlenebb termékkínálatot kialakítani és ehhez kezdésnek ideális a ChromeOS"
Arra az Android is jo lenne x86 vagy ARM procival. Plusz, az Intel az, aki nyomatja az Androidot (a Windows kárára) ujabban, ergo nem az Intellel van a baja a HP-nak, hanem inkabb a Microsofttal. Es az az ellenszenv is inkabb abbol a frusztraciobol fakad, hogy a juzerek utaljak a Windows 8.x verziokat, es emiatt nehezen tudnak eladni manapsag PC-ket az OEM-ek. Kellene egy utos, vonzo Windows, amivel konnyebb dolguk lenne nekik is.
"Úgy, hogy amíg az Intel véghezviszi azt a csodát, amit vársz, addig az AMD is javíthat a legacy X86 programok futási teljesítményén."
Amit az Intel csinal, az nem csoda, hanem fokozatos fejlesztes, stabil, folyamatos fejlodessel. Nem revolucio, hanem evolucio. Az AMD-nek viszont a legacy x86 teljesitmeny jelentos javitasara nincs jelenleg lehetosege (legalabbis a Bulldozer vonalon), ezert is dolgoznak a Family 20h-n. Amig az nem erkezik meg, addig nem fognak tudni semmit csinalni az x86 teljesitmennyel, sajnos.
"Vagy ez totálisan lehetetlen, ellenben az, hogy egy vacak grafikus architektúrával és egy útja vesztett alternatívával vergődő cég egyáltalán egálba vergődése belátható időn belül, annak aztán 100% az esélye"
A mult tapasztalatai alapjan megis az tunik valoszinubbnek, hogy az Intel utoleri iGPU-ban az AMD-t, mintsem az, hogy az AMD utoleri x86 teljesitmenyben az Intelt egyhamar. Ez van, nem en tehetek rola. A Family 20h valtoztathat ezen, de az 2016 vege elott nem fog megerkezni, addigra meg mar lassan a Skylake die shrinkje is probagyartas alatt lesz
"Egyébként a döntetlen most a gondolatmenetemben általánosan a hetrogén számításokban nyújtott teljesítményre utalt. Abban azért én nem vagyok annyira biztos, hogy az Intel a Gen6 alapjain valaha be fogja érni az AMD-t. Talán nagyobb lapkaméret mellett, de akkor meg megtapsolhatja magát a cég, hogy milyen ügyes volt."
Most oszinten, nem tokmindegy, hogy milyen modon ered el a teljesitmenyt, ha egyszer adott fogyasztas mellett elered? Lehet mondani, hogy az AMD mennyivel ugyesebben, okosabban jut el ugyanaddig a vegcelig, de ha a vegcel azonos (mondjuk legyen ez az 1 TFLOPS-os iGPU 65 wattos TDP-ju CPU-ba csomagolva), akkor minek azon ragodni, hogy ki hogyan erte el a celt? Plusz, ha egy szinten vannak iGPU-ban az AMD es az Intel processzorai, akkor is -- sajnos -- ottmarad az a fajdalmas pont, hogy x86 teljesitmenyben az AMD lassabb (legalabbis a Bulldozer csalad).
A nagyobb lapkameret ugyanugy megvan mondjuk a GeForce vs. Radeon osszehasonlitasnal is, megsem fog egy adott vasarlo csak azert venni Radeont a GeForce helyett, mert a Radeonnak kisebb a lapkamerete. Ennyi erovel lehetne kizarolag shader szam vagy orajel alapjan is vasarolni, de az is ugyanekkora hulyeseg lenne
"Én abban a hitben voltam, hogy a Carrizo jövő januárban érkezik"
Nem akkor fog. Leghamarabb jovo ev tavaszan, masodik negyedev. Mindez csak akkor, ha nem lesz csuszas.
"miután a 2012-es roadmap még erre az évre ígéri, ahogy a Kaveri-t múltévre, azonos mértékű eltolódás mellett meg Január lenne a logikus"
No offense, de az AMD roadmapjei, plane ilyen regiek, semmit sem ernek. Es mielott me'g a torkomnak ugrasz: mar vagy egy eve az Intel-fele roadmapek se ernek sokat, sajnos. Az nVIDIA-rol meg aztan ne is beszeljunk
Amikor egyik kodnev helyett beugrik egy masik, eltunnek a kodnevek, eltunnek a termekek, stb. Agyrem."Vagy most már azzal számolunk, hogy a Carrizo egy letesztelt gyártástechnológián még csúszni fog pluszban "mert csak"?"
En nem mondtam, hogy csuszni fog, csak azt mondom, amit az AMD mond. Az AMD pedig azt mondja, hogy Carrizo product launch: 2015 masodik negyedev. Ez az aktualis tervuk. Nem en talaltam ki.
"Azt milyen természetfeletti erővel fogod magyarázni, ha a Tonga tényleg egy ~200mm^2-es lapka lévén hozza a ~350mm^2-es elődje teljesítményét?"
_Ha_ hozza. Varjuk meg ezzel a Tonga launchot szerintem. Plusz, onmagaban a die size mint meroszam nem er semmit, egy APU-nal a TDP az elsodleges. Lehet az 500 m2-es is (bar azt meg nehez lenne legyartani, de ez masodlagos problema), ha belefer a TDP keretbe.
"Ha ez a bravúr még csak 20% pluszt is hoz majd a Carrizo esetén azonos gyártástechnológia és lapkaméret mellett, már az előrevetít egy sorsot az Intel IGP-k számára."
A Carrizonal a +20% azonos TDP-vel termeszetesen siman benne van. Csak epp, ahogy Abu is irja, 65 watt a cel a Carrizoval, es nem 95 watt mint a Kaveri eseteben. Ergo, lenyegesen alacsonyabb TDP-bol kellene kihozni nagyobb teljesitmenyt. Ez me'g egy kis varazslattal sem konnyu feladat. Plusz, ahogy irtam is mar, legalabb 20-25% teljesitmeny fejlodes az Intelnel minden generacio valtasnal jelentkezik mar par eve, tehat a +20% a Carrizonal az abszolut minimum, amire szukseg van ahhoz, hogy az Inteltol a biztonsagos tavolsagot tartani tudjak. De, mivel az Intel 2 generaciot valt (Haswell --> Broadwell --> Skylake) mig az AMD csak egyet (Kaveri --> Carrizo), igy igazsag szerint a dupla +25% = +56% (1,25 x 1,25, mielott me'g a matematikusok nekem ugranak) lenne mondjuk a kivanatos a Kaveri --> Carrizo valtasnal, hogy tartani tudja az AMD az elonyet iGPU teljesitmenyben. Ami a csokkeno TDP-vel SZVSZ mission impossible, de ne legyen igazam.
-
stratova
veterán
válasz
leviske
#14287
üzenetére
HP eddig is az egyik legkomolyabb ügyfele volt AMD-nek. Sőt kicsit megtörni látszik a jég:
Elitebook 725 G2
Elitebook 745 G2
Elitebook 755 G2 -
Fiery
veterán
válasz
leviske
#14272
üzenetére
"egy olyan piacon, ahol az OEM-ek szakadni próbálnak az Inteltől"
Errol kerek egy linket vagy egyeb konkret infot. Az OEM-ek eddig is epithettek volna gepeket AMD APU-ra, megsem teszik meg tul sokan, es amelyek meg is teszik, azok sem kinalnak tul sokfele konfiguraciot.
"Közben a valóság az, hogy egy "döntetlen" már elindíthatna egy masszív piacátrendeződést"
Es hogyan tudna az AMD dontetlenre allni az Intellel szemben? Ird le kerlek a konkret forgatokonyvet.
"A Tonga-t és a GCN új verzióját nem érdemes feltétlen lebecsülni, mert ha az AMD a Carrizo-val azonos gyártástechnológián és azonos lapkaméret mellett bedob egy meghökkentő mértékű IGP teljesítménynövekedést"
Oke, tegyuk fel, meg tudjak lepni ezt. Hogyan? Milyen varazslatot tudnak elohuzni? Itt mar sajnos nincs meg az a lehetoseg, ami a Richland --> Kaveri valtasnal adodott, azaz hogy az elavult architekturat (VLIW) lecserelik modern architekturara (GCN). A GCN "sajnos" mar tul jo ahhoz, hogy clock-for-clock, shader-for-shader radikalisan elore lehessen lepni a kovetkezo 2-3 evben.
En maximum azt tudnam elkepzelni, hogy azonos gyartastechnologian, azonos orajelekkel, nagyobb lapkamerettel, de megis azonos TDP-vel tudnak hozni mondjuk +20%-ot. Ennyi benne lehet a GCN-ben es a mostani gyartastechnologia optimalizaciojaban, de ennel sokkal tobb ketlem, hogy hozhato lenne. Raadasul, a Carrizo az x86 core-okat is tovabb bonyolitja (AVX2), a memoriavezerlot is tovabb bonyolitja (DDR4-et is tamogatni fog a DDR3 mellett), tehat nem vilagos, hogy egy potencialisan energiaigenyesebb x86+uncore resszel hogyan tud a TDP maradni annyi mint most, vagy csokkenni (65 wattra). Plusz, az ido alatt, amig a Carrizo iGPU-ja hozni tudja ezt a 20% teljesitmeny novekedest a Kaverihoz kepest, az Intel hoz 25-30%-ot a Broadwellel, plusz ujabb mondjuk 20-25%-ot a Skylake-kel. Nehez ugy lesz ez.
"szóval ha a Skylake idején esetleg 14nm HDL-re vált a cég"
Ez nem fog megtortenni. A Skylake megjelenese idejen fog kijonni a Carrizo, ami semmikepp sem fog 14 nanon keszulni. Vagy arra gondolsz, hogy amikor a Skylake kezd kifutni (2016-2017), es epp keszul a 10 nanos shrinkje (Cannonlake?), akkor valt az AMD/GloFo 14 nanora?
Az mar megint keso lesz az udvosseghez."csak újra egy éles piaci versenyt. Erre pedig van esély."
Van, csak kell hozza szoftveres hatter (Mantle, DX12, OpenCL 2.0, HSA). Anelkul esely sincs az igazi versenyre, ami nem jo dolog
"Jó példa erre a PhysX"
Tegye fel a kezet az a jatekos, aki azert vett GeForce-ot egy gyorsabb Radeon helyett, mert a GeForce PhysX-et is tamogat.
"csak át kell hozni azt a megoldást, ami konzolon megvan"
Az a kerdes csupan, hogy ha at is hozzak, az jelent-e majd annyi kulonbseget latvanyban vagy jatszhatosagban, ami megindokolja az APU-k letjogosultsagat a jatekosok koreben.
-
Fiery
veterán
válasz
leviske
#14269
üzenetére
"Anno a Netburst-féle izomból nyomás nem tett túl jót az Intel renoméjának"
A renome teljesen mindegy, azzal a piac nem foglalkozik tul sokat. Ha a termek gyors, stabil, jo ar/ertek aranyu, akkor megveszik.
"szóval én remélem, hogy inkább szimplán okosak lesznek, mint a Conroe esetén"
Az elegge nyilvanvalo, hogy a mostani brute force megoldas, a meglevo, Gen6-bol (Sandy Bridge) eredeztetett, de folyamatosan faragott iGPU architektura csak egy koztes lepcso. Jelenleg ennyit tud az Intel, de ezzel is eleg sokat lepnek elore minden generacio valtasnal. Stabilan legalabb 25-30%-ot gyorsulnak az Intel iGPU-i az elozo generaciohoz kepest. Van hova fejlodniuk, de maga a fejlodes uteme eleg jo ahhoz, hogy folyamatosan egyre kozelebb keruljenek az AMD-fele konkurens iGPU-khoz. 5-6 eve me'g elkepzelhetetlen volt, hogy az Intel olyan iGPU-t tud letenni az asztalra, amivel majdnem utoleri a "nagyok" iGPU-it, aztan tessek... A Broadwell is ugyanigy hozni fogja a cca. 25%-os gyorsulast, a Skylake pedig ha lehet hinni a pletykaknak, szinten hozni fogja ezt a gyorsulast. Tonga meg ujgeneracios GCN ide vagy oda, a gyartastechnologiat is kellene fejleszteni, mert sima architektura faragasbol nehezen fog osszejonni egy olyan kenyelmes elony az AMD-nel, amivel tudjak tartani 2-3 ev mulva is a mostani elonyuket az Intel iGPU-ival szemben. Ha pedig az AMD teljesitmenybeli elonye eltunik, es az Intel iGPU-it is munkara lehet fogni HSA-val, egy most me'g nem ismert HSA-szeru megoldassal, OpenCL-lel, D3DCS 12-vel vagy barmi massal, akkor megint eltunik az AMD minden megmaradt vagy vélt elonye.
"A Mantle/DX12-t úgy kapcsoltam a OpenCL-hez, hogy az AMD ezek alatt meggyőzeti a játékosokat, hogy egy APU jobb választás pl: egy R9 290X mellé, mint egy FX-83"
Erre van némi esely, bar szerintem csekely. Az a baj, hogy rengeteg olyan jatekra lenne szukseg, ami egy APU+290X kombon lenyegesen jobban fut, mint mondjuk egy 4 magos Intel CPU+290X kombon. Az nem eleg ugyanis, hogy ha a Mantle/DX12 ugymond eltunteti a CPU-limitet. Amig egy jatekos jatszik 5 olyan jatekkal, ami CPU-limites es 5 olyan ujgeneraciossal, ami kevesbe CPU-limites, addig nem fogja feladni a gyorsabb Intel procit, nem fog APU-t valasztani. Az kellene, arra lenne baromi nagy szukseg, hogy egy olyan pluszt hozzanak az APU-k a jatekosoknak, amivel egyertelmu legyen az, hogy jatekra azt _kell_ valasztani, amivel egyertelmuen lenne, hogy az APU mindenben jobb (legalabb jatekra), mint egy Intel CPU. Ehhez viszont a Mantle/DX12-nek szeles korben el kellene terjednie, plusz az ujgeneracios konzolos jatekokat oly modon at kellene hozni PC-re, hogy az APU hatekonyan be tudjon segiteni a dGPU-nak, es valamilyen formaban -- pl. sokkal fejlettebb AI, sokkal szebb fizika, valamilyen mas latvanybeli fejlesztes -- uj szintre tudja emelni a PC-s jatekokat. Amig ez nem kovetkezik be, addig "biztos ami biztos" alapon a jatekosok egy 290X szintu high-end dGPU mellé tovabbra is a legerosebb Intel procikbol fognak valogatni, mondvan hogy "Az mindenhez eleg lesz". Amint megjon az elso 5-10 db jatek, ami AMD APU+AMD dGPU parossal "leesik az allad" elmenyt ad, mikozben Intel CPU-val (vagy epp FX-szel vagy Kaveri elotti APU-val) meg "semmi extra", na az a pont fogja elhozni a megvaltast az AMD-nek. Sokan hisznek abban, hogy ez a pont eljon majd, en meg azt mondom, hogy csak akkor mukodhet ez, ha nem lesz konkurens megoldas. Ha azt a funkcionalitast, amivel az AMD-fele APU-kat befogod a jatekos elmeny boostolasara meg tudod csinalni Intel CPU-n is (pl. Broadwellen vagy Skylake-en), akkor megint nem lesz miert AMD-t venni a hardcore jatekosoknak
Ez a nagyon nagy riziko van meg csupan ebben az egesz mesteri tervben -
Fiery
veterán
válasz
leviske
#14241
üzenetére
"Itt most arról van szó, hogy a GCN egy zsákutca, vagy arról, hogy az Intel még nem találta meg az útját és ezért még végtelen sok lehetősége van?"
Arra gondolok, hogy a fejlett(ebb) gyartastechnologia (foleg a 14 es majd a 10 nano, ha majd elkeszulnek egyszer) lehetoseget ad az Intelnek arra, hogy olyan trukkoket vessen be (pl. eDRAM), amivel ugymond erobol (brute force) nyomja le az AMD-fele APU-kat. Mint anno a NetBurst: nem okos architektura volt, hanem nagyon magas orajelre skalazhato. Az orajellel potoltak az architekturabol kimaradt "ravaszsagokat". Most meg majd nyers magszammal (shader) meg eDRAM-mal ellenpontozzak a GCN zsenialitasat.
A GCN egyaltalan nem zsakutca, csak epp nem latszik jelenleg az, hogy az egyre csokkeno TDP keretbe hogyan fog tudni az AMD me'g nagyobb nyers iGPU teljesitmenyt beszuszakolni, kulonosen ha maradnak me'g 1-2 evig a mostani gyartastechnologianal. Plane ugy, hogy a mobil vonalon me'g az FCH-t is integralnia kell, az is beleszamit a TDP-be -- mig jelenleg azt kulon szamitjuk. Mar a Kaverinal is problemat okoz(ott) a TDP es/vagy a kiforratlan gyartastechnologia, eleg csak megnezni az orajeleket (vs. Trinity orajelek).
"A Mantle/DX12 csapásirányán pedig már elkezdhet kialakulni egy OpenCL környezet."
No offense, de mi a frasz koze van a Mantle-nek es a DX12-nek az OpenCL-hez?
"Két év alatt pedig az AMD is összerakhat egy olyan, kiegyensúlyozottabb architektúrát, ami már nem csak a közvetlen partnerek számára meggyőző."
Igy legyen! 2 ev mindenkepp kell ehhez, addig ugyanis eleg fixnek latszik az AMD utiterve: jovo ilyenkor jon a Carrizo, utana meg nem valoszinu, hogy egy-masfel even belul erkezne az uj mag (Family 20h).
"optimális esetben 2 év múlva már a 3. HSA képes APU-nál fogunk járni."
Teljesen mindegy, hogy hanyadik generacional jar. Nem az a baj (mostanra mar), hogy nincs vas a HSA-hoz, hanem az a baj, hogy annak a vasnak (Kaveri) a PC-piaci penetracioja borzalmasan alacsony. Plusz, a HSA nincs kesz, ergo a fejlesztok amugy sem tudnak rendesen dolgozni vele. Majd ha lesz tobbfele hardver, azokbol eladnak par tizmilliot, es a HSA is stabil allapotba kerul, akkor elindulhat a szoftverek gyartasa. Ha az aztan general egy lavinat, akkor menni fog a HSA, es az AMD APU-jai is sikeresek lesznek, de ez akkor sem azon fog mulni, hanyadik generacional tart az AMD.
-

Vitamincsiga
tag
válasz
leviske
#14241
üzenetére
"A Steamroller nagy baja, hogy egyszálú teljesítményben nagyon elmarad a Haswell-től. A Kaveri X86 teljesítményén az segített volna, ha gyakorlatilag dobják az egész Bulldozer felépítést. Bulk-ra szvsz már elő kellett volna jönni egy olyan architektúrával, ami közelebb áll c2c az Intelekhez. Bár fene tudja, lehet, hogy az Excavator már ezen a téren jócskán előrelépést jelent majd."
Tavaly is azt hittük a Kaverivel kapcsolatban, amikor felkerült a netre AZ A KÉP

Ahogy most kinéz, a Carrizo is csak 28 nm-en jön ki így extra teljesítménynövekedésre kevés az esély - remélem TÉVEDEK!!Viszont a "fúzió" a végére ér és az a funkcionalitás, amit megálmodtak pár éve mind belekerül

A HSA-t kihasználó programok nagyon is versenyképesek a Kaverivel is, az utód csak jobb lehet! -

Abu85
HÁZIGAZDA
válasz
leviske
#14230
üzenetére
Teljesen mindegy, hogy milyen HSA alternatívák készülnek. Az Intelnek és az NV-nek nem ezzel van baja, mert a HSA-nál nyíltabb dolog sosem születhet meg. Azzal van a gond, hogy az ilyen koncepció minden kínai dzsunkacéget beenged a piacra. A PC gyakorlatilag háromszereplős. Egy HSA-val vagy egy ugyanilyen koncepcióval csak más néven pillanatok alatt jöhet még tíz szereplő, aztán nem sokkal később még tíz.
A Microsoft sem egy olyan aranyos cég már. Az utóbbi időben csupa rossz dolgot csináltak az Intelnek és az NV-nek, amihez pusztán a politikai látszat matt széles mosolyt kellett vágniuk. A DirectX 12-vel az MS kiszállt gyártói harcból, mostantól leszarják, ha az Intel és az NV nem tud valamit támogatni.
-
Fiery
veterán
válasz
leviske
#14225
üzenetére
"Viszont kérdés, hogy amennyiben az Intel sikeresen megszül egy versenyképes MIC-et, akkor mégis hogy fogja fenntartani a fejlődést, ha maga az első sikeres MIC is eltart x generáción keresztül?"
Ha mar van egy sikeres, stabil alap, arra mar konnyebb epitkezni, mint nullarol indulva eloszor rossz iranyba indulni (videokartya projekt), majd korrekciokkal eljutni valami hasznalhatoig. Rengeteg pelda van erre, de a lenyeg az, hogy ha van egy jo alapod, onnan mar evolucios lepesekkel konnyebb haladni.
"Alapvetően kevesebb ideje fejlesztik, mint amennyi ideje a MIC kalapács alatt van."
Nem kevesebb ideje, hanem kb. ugyanannyi ideje. Es az OpenCL "csupan" egy szoftveres layer, amihez megvolt a stabil hardveres alap (Tesla/G80, VLIW5 by ATI) mar a legelejen is; mig az Intelnek a hardver a legnagyobb nyomora, azt nem tudjak osszerakni 6 eve. Alapvetoen teljesen mas a problema. Ha lenne egy tenyleg jol mukodo x86 alapu GPGPU hardvere az Intelnek, a compilerrel sokkal konnyebben megbirkoznanak _szerintem_, nem az lenne a fejlodes akadalya, mint most az OpenCL 1.x GPU-knal, gyartotol fuggetlenul.
"Pedig, ha még esetleges hibákkal is, de működik."
Marmint melyik?
Nagyjabol egyik sem. Ha az OpenCL olyan jol mukodne az "esetleges" hibakkal egyutt, akkor sokkal jobban elterjedt volna 6 ev alatt. 6 ev rohadt hosszu ido, kb. ugyanennyi ideje volt az Androidnak is nullarol elterjedni, megis teljesen mas utat jart be, mint a MIC vagy az OpenCL."Milyen szinten kellene megnyilvánulnia, hogy az egész világ az Intel ellen van?"
Ki kellene mindenkinek hatralnia az x86-bol. Az AMD-nek, a VIA-nak (bar ok nem sok vizet zavarnak most sem, sajnos), es foleg a Microsoftnak. Ha az MS azt mondaná, hogy nincs tobb x86 Windows, mindjart mas lenne a helyzet. Ez persze utopisztikus, hiszen a Microsoft sem hulye es az AMD sem hulye, hogy elhagyja az x86-ot. Addig azonban, amig a cegek fuggenek a Windows+x86 kombotol; meg amig az emberek x86 PC-ket (asztali, mobil, ultramobil) es x86 szervereket folyamatosan tiz/szazmillios nagysagrendben vasarolnak, nem lehet azt mondani, hogy az Intel ellen van a vilag, sajnos. Nagyon is kenyelmes helyzetben vannak mind a mai napig, egyedul az ultramobil vonalon van felzarkoznivalojuk, a mikroszerver szegmensben pedig ki kell epiteniuk a hidfoallasukat, a tobbi szegmensben siman elvannak erolkodes nelkul is.
"ellenben a MIC nem lehet átütő és piacátformáló siker, amíg ezek léteznek és van esélyük használatba kerülni"
Kiveve, ha a MIC architekturas CPU/GPU/akarmivel is hozhato OpenCL-ben vagy C++AMP-ban ugyanaz a teljesitmeny, ami AMD vagy nVIDIA GPU-val. Ez majd elvalik, egyelore nyilvan sehol sincs az Intel a mostani Gen7 megoldasokkal.
"Márpedig, ha a HSA-t kivesszük a képletből, akkor az említett megoldások mögött áll többek közt az Apple/Google/Microsoft."
Az Apple? Maximum a desktopon, de nem az ultramobil eszkozokon. Vagy csak lemaradtam valamirol, es az OpenCL iOS-en is szalad?
Legutoljara amikor neztem, me'g csak OSX-re volt OpenCL implementacioja az Apple-nek.A Google pedig me'g veletlenul sem tamogatja a felsorolt technologiakat, kulonosen nem tamogatja az OpenCL-t es a C++AMP-ot. Az OpenCL-t eddig igyekezett minden erovel kiszoritani az Androidrol, kerdes, hogy ez meg fog-e valtozni a HSA-val, megbekel-e vele a Google, vagy lemasoljak benabb kiadasban (a la RenderScript vs. OpenCL), es azt tolják inkabb a HSA helyett.
A Microsoft pedig szinten nem orul az OpenCL-nek meg a HSA-nak, ok inkabb a C++AMP-ot tolnák. De legalabb nem tesznek keresztbe ezeknek az API-knak. Viszont, siman lehet, hogy a DirectX12-vel ok is kihoznak valami HSA-szeru megoldast, amit tamogathat az Intel es az nVIDIA is.
-
Fiery
veterán
válasz
leviske
#14214
üzenetére
Nekem nem remlik ilyesmi, de nem is zarom ki a lehetoseget. De ennyi erovel siman mondhatod azt is, hogy egy X benchmark hulyeseget mér, mert egy olyan x86 kiterjesztesre valo optimalizaciot hasznal (pl. AVX2 vagy XOP), amit amugy a szoftverek 99 %-a nem hasznal. Igy gondolkoztak anno az SSE megjelenesekor is sokan, es par evig igazuk is volt. Manapsag meg mar teljesen altalanos, hogy egy adott szoftver SSE nelkul el se indul
-
Fiery
veterán
válasz
leviske
#14211
üzenetére
"Konkrétan milyen formában kéne az nVidia-nak felugrani a MIC vonatra és mi célból tenné, ha ezt képest gyakorlatilag RISC alapon is kivitelezni?"
Ennyi erovel azt is kerdezhetned, hogy miert erolteti az AMD me'g mindig az x86-ot
Sosem tudhatod, mit hoz a jovo, hova fejlodik a MIC, a CUDA vagy epp a GCN es a HSA. De ha mondjuk feltetelezunk egy olyan jovot, ahol a HSA nem er el attorest, a CUDA megragad a mostani szinten, a dGPU-k relevanciajukat vesztik (a KNL-szeru megoldasok miatt), a MIC viszont befut es mindenki nativ x86-on akarja a "GPU"-t is programozni, akkor pl. szuksege lehet x86 licencre az nVIDIA-nak. Nem mondom, hogy ez fog tortenni, csak mint egy lehetseges forgatokonyvet vazoltam fel. Anno az x86-ra sem gondolta volna senki, hogy ilyen sikert fog befutni, aztan tessek... Persze ennyi erovel siman lehet, hogy a HSA lesz a kiraly, es akkor az architektura lesz erdektelen, barki barmit csinalhat, amig a HSA-ra fejlesztett kodot tudja futtatni a vas."logikusnak tűnik egyeztetni a piac egy-két reprezentatív tagjával és annak megfelelően fejleszteni."
A logika ezt diktalja, a valosag azonban az, hogy a gyartok hozzaszoktak ahhoz, hogy ok megmondjak mindenkinek, hogy mire van szukseguk. Ez vezetett aztan oda, ahol most tartunk, pl. Windows 8, AVX, stb. Kerdes, hogy ha megforditjuk a dolgot, es -- legalabbis a retorika szintjen -- a fejlesztok kezebe adjuk a jovot, akkor mi fog tortenni. Mas lenne ugyanis a helyzet, ha jonne egy zseni szoftver fejleszto, aki kitalalja, hogy mikepp nezzen ki a HSA, mikepp tud majd segiteni az o munkajaban, es utana egymaga lekodolja az osszes szukseges compilert, finalizert, szoftver stacket, drivert, stb az osszes hardver gyarto szamara. Ez nyilvan lehetetlen, senki sem ekkora zseni es egy nyilvan ra kell dobni egy csomo fejlesztot minden gyartonak, csak tudod az a szomoru ezzel az egesszel, hogy hany eve is fejleszti az OpenCL implementaciojat az ATI/AMD? Hany eve fejleszti az Intel, az nVIDIA? Es me'g mindig nem tokeletes, sot. Leginkabb f*s me'g mindig, egyedul talan az nVIDIA-e hasznalhato, hellyel-kozzel. Mi a garancia arra, hogy a HSA-val maskepp fog mukodni a dolog? Mi a garancia arra, hogy nem tart 6-7 evig, mire hasznalhato lesz a HSA a szoftver fejlesztok szamara?
"Az egy dolog, hogy az Intel egy nagyon komoly piaci erőt képvisel, de azért vannak nála nagyobb cégek is, köztük pár HSA alapítványtag."
Az Intel es az x86 mar az elmult cca. 30 evben is lenyomott par olyan piaci szereplot, akit nem gondoltunk volna, hogy le tud nyomni. Nem mondom, hogy tevedhetetlenek, de amig az egesz vilag nem all szemben az Intellel, addig nehez kiszoritani oket a piacrol. Plusz, az, hogy valaki HSA alapitvanytag, me'g nem sokat jelent. Mit csinal a VIA? Mit csinal a Samsung? Hol vannak a Samsung SoC-ok, amik HSA-ready-k? Ha a Samsung nem keszult el veluk, akkor a kisebbek mikor fognak? Miert nincs az alapitvanyban a Google, az Apple, a Microsoft es az nVIDIA? Lehet, hogy a HSA alapitvanyhoz csatlakozott nehany nagy nev, de kozben meg baromi sok nagy nev nem. Mindenki sutogeti a sajat pecsenyejet, igy pedig nehezen fog tudni elrugaszkodni a HSA pl. Androidon vagy iOS-en.
-

leviske
veterán
válasz
leviske
#14211
üzenetére
Kimaradt az Intel-féle tesztelős móka. Sajnos nem tudok példát hozni, de holnap szívesen visszakeresek olyan hozzászólásokat, ahol te is elismered, hogy az IGP eredményeket igyekszik/igyekezett a cég szépíteni több alternatív módon is. Talán rendes grafikai megoldások mellett felmerült az OpenCL is, de ebben nem vagyok már biztos.
-
Fiery
veterán
válasz
leviske
#14206
üzenetére
Ertem, hogy mit mondasz a MIC vs. Itanium parhuzamrol, de SZVSZ semmi ertelme oket parhuzamba allitani. Az Intel mar most is kvazi monopol helyzetben van a PC-s processzorok piacan, ennel jobban mar nem lehet kizarni a konkurenciat, mert me'g a vegen feldaraboljak oket is az antitroszt torvenyekre hivatkozva. Jelenleg pedig egyaltalan nem ugy tunik, hogy aka'r az AMD, aka'r az nVIDIA fel akarna szallni valaha is a MIC-vonatra. Ami nem is csoda, hiszen me'g nem latszik, mire is lesz jo ez az egesz a gyakorlatban.
"Emellett a másik közös pont pedig, hogy feltételezem az X86-64 nem egy önálló ötlet volt az AMD-től, hanem a szoftverfejlesztők igényeinek a megtestesítése"
Nem kell am azt gondolni, hogy a szoftver fejlesztok iranyitjak a vilagot
Me'g ha egy adott ceg azt is mondja, hogy a partnerek/baratok/kliensek igenyei szerint is fejlesztett valamit, ez egyaltalan nem biztos, hogy igaz. Plusz, honnan tudod, hogy ha meg is hallgattak nehany szoftver fejlesztot, valojaban hany fejlesztot hallgattak meg, es mennyi mindent valositottak meg abbol, amit ok szerettek volna? Minden fejlesztonek masok az igenyei, mindent nem lehet megvalositani, mindig vannak korlatok, mindig kell kompromisszumokat tenni.De ne erts felre, nem biralom az AMD64-et (nevezzuk inkabb igy), nagyon jo kiegeszitese a klasszikus x86-nak. Viszont, ha nincs a Microsoft, vagy a Microsoftot az intel meg tudja gyozni, akkor az AMD64 mar reg a 3DNow! sorsara jutott volna, es az Intel altal lekoppintott Intel64 lenne most az egyeduralkodo. A Microsoft volt az, aki az asztalra csapott, es nem volt hajlando egyszerre harom 64 bites architekturat tamogatni a Windowsban. Lenyegeben rakenyszeritettek az Intelt, hogy adoptaljak az AMD64-et. Persze ha anno az Intel jobban latja a jovot, akkor mar akkor eldobhattak volna az IA-64-et, es valthattak volna Intel64-re.
"Elég enyhe megfogalmazás ez.
Egy olyan piacon, ahol a gyártók maguk faragják a hardvert, az Intelnek és az AMD-nek konkrét saját termékekkel szerintem sosem lesz esélye labdába rúgni."Just wait & see
"Viszont volt már az AMD egy másik piacon hasonló helyzetben, amit aztán az követett, hogy évekig kisebb lapkákkal hozták ugyanazt a teljesítményt, mint a konkurencia."
Hidd el, en oszinten szurkolok annak, hogy ujra legyen egy K8-a az AMD-nek. Ujra rugjak s*ggbe az Intelt, hogy megint jobban igyekezzen. Mert az Intel most nagyon el van tunyulva a mainstream PC-s szegmensben, es minden erejukkel az ultramobilt toljak. Jo lenne, ha megint lenne rendes konkrenciajuk minden szegmensben.
"Nem teljesen értem, hogy az aláhúzott rész az irónia-e vagy sem"
Abszolut komolyan gondoltam. Az Intel es az nVIDIA egyutt baromi erosek lennenek. Egyedul az a gond, hogy az nVIDIA vezere tul becsvagyo, es leginkabb akkor menne bele egy egyesulesbe, ha az uj ceget is o vezethetne'. Siman lehet, hogy ragaszkodna ahhoz is, hogy nVIDIA legyen az egyesules neve. Ez pedig nyilvan nem fer bele a kékeknek...
"Én nVidia & Intel összeborulást még abban az esetben sem éreztem volna abszolút értelmesnek, ha az nV és a ViA sikerrel összeolvadt volna és ezzel Huang keze alá került volna egy X86 részleg is."
Hidd el, ez a felvasarlas felmerult. A problema csupan az, hogy az x86 licenc non-transferable. Azaz, ha a ceget, aminek jelenleg van x86 licence, felvasarolja egy masik ceg, akkor a felvasarolt ceg elvesziti az x86 licencet. Az Intel pedig anno par eve me'g olyan pozicioban volt, hogy nem hianyzott neki me'g egy x86 konkurens, plane nem egy olyan szivos, eros ceg, mint az nVIDIA. Manapsag, hogy a VIA mar szinte eltunt az x86 piacrol, es az AMD-t is konnyebb "kezelni" (ertsd: gyengebb termekeket gyart, csokkent a relevanciaja az x86 piacon), talan nem zavarna az Intelt annyira, ha belepne egy uj x86 szereplo. De kivanatosnak biztos nem gondoljak, tehat nem fogjak szorgalmazni
"Az az irány pedig több párhuzamot mutat az AMD elképzeléseivel, mint az Intelével."
Persze, csak a G80 idejeben me'g nem lehetett elore latni, hogy mikor utkozik falnak a gyartastechnologia. Ha az nVIDIA-t megszivatja a TSMC, es nem tudjak normalisan legyartani a high-end Maxwell GPU-kat, akkor nagyon hamar rohadt nagyot koppanhat az nVIDIA. Az Intel gyartastechnologiajat -- talan -- be lehetne vetni a dGPU-knal is, ergo egy gyartasi kooperacioval az nVIDIA sokat nyerhetne _elvben_. A gyakorlat azonban maskepp mukodik, sok dontest a politika mozgat, ill. az nVIDIA vezere sem egyertelmu, hogy merre akarja vinni a cégét...
"Kérdés, hogy mennyire éri meg csak az Intel miatt egy az egyben lemondani a HSA használatáról."
Miert kellene barmirol is lemondani? Megirod a kernelt OpenCL 2.0-ban, es vagy HSA path-re kuldod a vegrehajtast, vagy OpenCL-re.
"Az Intel-féle "tervezzünk hardvert a teszt alá" megoldással meg az a probléma, hogy olyan teljesítményt sugall, amit valójában ideális körülmények közt sem képes hozni a hardver."
Egy konkret peldat kérek erre.
"Én inkább arra vagyok kíváncsi, hogy az OpenCl, C++AMP, Raspberry PI, stb mennyire fogják valósan háttérbe szorítani az egyszálas X86 teljesítményt"
Ezt konnyen le tudod tesztelni magadon is akár. Hasznalj par napig egy Kabini vagy Bay Trail alapu desktop gepet. Ha folyamatosan azt erzed, hogy lassu, akkor szamodra az egyszalas teljesitmeny a donto, es a HSA/OpenCL sem fog segiteni. Ha azonban teljesen korrektnek erzed ezeket a low-power cuccokat, akkor me'g jo lehet a HSA/OpenCL is Nalad. Van 1-2 ismerosom, aki ilyen Kabinis ill. Bay Trail-es konfigot kapott tesztelesre, es köpködik oket, hogy erzesre, a mindennapi hasznalat soran milyen lassuak. Nyilvan egy Haswell i5 vagy i7, de me'g egy Kaveri utan is termeszetes ez, csak epp ez is jol mutatja azt, hogy az egyszalas teljesitmeny mennyire donto tud lenni sok PC felhasznalonal. Mert ha a tobbszalas teljesitmenyt nezzuk, akkor a Kabini es a Bay Trail is eros CPU-k, csak epp megsutheted a tobbszalas teljesitmenyt, ha nincs ami kihasznalja. Nagy kerdes, hogy a HSA/OpenCL tul tud-e lepni majd ezen a probleman.
"Arról nem is beszélve, hogy mire volt jó a Bulldozerrel való szenvedés, ha aztán a Bobcat alapjait viszik tovább."
A Bulldozer (volt) az AMD NetBurstje, ilyen egyszeru. Minden cegnek vannak zsakutcaba szorult termekei, nincs ezzel gond, ha idoben jon a korrekcio. Az AMD-nel -- szerintem -- kicsit keson jon a korrekcio, de nem tul keson me'g, szerencsere. Ha a Puma+ utoda skalazhato lesz 4 GHz-ig, akkor jo lehet a Bulldozer kivaltasara. Ha azonban megmaradnak a Puma+ szintjen orajelben es teljesitmenyben, akkor az keves lesz, HSA ide vagy oda.
-
Fiery
veterán
válasz
leviske
#14203
üzenetére
Bocs, de tenyleg nem ertem, mi koze az Itaniumnak a MIC-hez. Az egyik egy gyokeresen uj architektura, ami megbukott, sosem tudta az x86-ot lenyomni -- kiveve a piac egy nagyon szuk szegmenset. A masik meg pont egy, az x86-ra epulo compute architektura lenne, amit GPU-kent ill. GPGPU-kent is lehet(ne) hasznalni. Az Itanium egy teljesen uj architektura volt, a MIC tulajdonkeppen nem az, csak egy specialisan kialakitott x86 hardveres implementacio. Vagy azt akarod sugallni, hogy a MIC az Itaniumhoz hasonloan meg fog bukni? Ezzel szerintem varjuk meg a Knights Landing-et es a Skylake-et, majd utana raerunk ilyen konkluziot levonni
A KNL-et es a Skylake-et sikernek vagy bukasnak beallitani elore, csak mert -- velhetoen -- MIC alapuak lesznek kb. olyan lenne, mint ha az AMD Family 20h-t allitanank be ugyanigy elore sikernek vagy bukasnak."Ellenben, ha az Intel olyan formában "győzne", hogy megint egyeduralkodóvá válik a piacon"
Sajnos mar most is van nehany piaci szegmens, ahol nincs ellenfeluk. Kapasbol a mainstream desktop es mobil piac felso fele ilyen, aztan ott vannak az 1, 2 es 4 utas szerverek, a munkaallomasok, a HEDT, stb. Ahol van konkurenciajuk, az az ultramobil eszkozok (tabletek, telefonok) es az olcso desktop es mobil PC-k. Nyilvan senki sem akarja, hogy ez a helyzet me'g rosszabbra forduljon a piac szamara, de azzal, hogy ennyire eltero utat valaszt az AMD es az Intel (az nVIDIA-rol nem is beszelve), abszolut megjosolhatatlanna teszi azt, hogy vegul mi lesz a jelenlegi GPU-piaccal. Egyaltalan nem biztos, hogy az x86 barmilyen szinten utokartya lesz a jovoben, emiatt pedig a MIC lehet, hogy rossz valasztas lesz hosszutavon. Viszont, a masik oldalon meg egyaltalan nem biztos, hogy a compilerekre, driverekre es a szoftver fejlesztokre ra lehet bizni az, hogy ok oldjak meg a jelenlegi "teljesitmeny fal" problemat. Nincsenek jo OpenCL compilerei es nincsenek jo driverei sem jelenleg az AMD-nek es az Intelnek sem, ez pedig nem jo alapot ad a fejlesztoknek arra, hogy szivassak magukat az egesz OpenCL es HSA temaval. Az nVIDIA-nak -- talan -- lenne ehhez megfelelo alapja, csak ok meg nem egyertelmu, hogy milyen iranyba tartanak. Talan abban biznak, hogy az x86 hamarosan elvesziti jelentoseget, es az ARM alapu "APU"-jukkal, egy sajat, proprietary HSA-szeru megoldassal ok is utolerhetik a "nagyokat".
"Emellett az nVidia is érdekelt volna a HSA térnyerésében, mert az Intel megoldása mellett a CUDA-t is lehet kukázni, míg a HSA mellett bőven megfér."
Az nVIDIA sosem szeretett masok moge beallni, nem csodalom, hogy a HSA-t sem favorizaljak (egyelore). Velemenyem szerint -- de erre semmi bizonyitekom nincs -- egy sajat megoldason dolgoznak, ami vagy a CUDA-ra fog epulni, azt egesziti ki SVM es mas HSA-bol "ellesett" kepessegekkel, vagy egy az egyben a HSA koppintasa lesz mas neven. Kisebb eselyt adok annak, hogy osszeallnak az Intellel, bar annak egyebkent abszolut lenne ertelme.
"Egy HSA implementáció elkészítését meg szvsz én nem érzem annyira nagy bűnnek, mint egy-egy tesztprogram tesztrutinjaihoz igazítani egy hardvert, ami utána gyakorlatban nem képes hozni a teszt által sugallt eredményt"
Egyedul annyi a problema ezzel, ha a nagykozonseg az AMD altal, a sajat hardvereikre, sajat HSA szoftver stack-ukre fejlesztett megoldas teljesitmenyet probalja levetiteni a HSA-ban rejlo teljes potencialra. Kb. mint ha holnap kidobna az AMD egy sajat benchmark szoftvere altal mért eredmenyt a Carrizora, es az alapjan eldontened, hogy a Carrizo qrva eros proci lesz es megeszi reggelire a Skylake-et jovore. Lehet, hogy a HSA segitsegevel konnyu lesz a Kaveri es Carrizo iGPU-janak teljesitmenyet kiaknazni, siman lehet hogy annak segitsegevel lenyomhato lesz mondjuk a legerosebb Broadwell-K is, de hogy valojaban mire is lesz kepes a HSA, azt nem a jelenlegi HSA megoldasok alapjan dontenem el. Mas lenne a helyzet, ha mondjuk lenne mar tobbfele fajltomorito, tobbfele video enkoder, tobbfele benchmark szoftver is HSA-ra, akkor mar egy sokkal realisabb kepet kaphatnank a HSA optimalizacio _atlagos_ hozadekarol. En csupan attol felek, hogy nagyon hosszu idonek kell eltelnie ahhoz, hogy egy atlagos hw review website altal hasznalt benchmark, applikacio es jatek programok akarcsak negyede is HSA optimalizaciot kapjon.
Plane erdekes kerdes lesz, hogy ha az Intel is beepiti az OpenCL 2.0 es SVM tamogatast (Broadwell es/vagy Skylake), akkor azzal a HSA nelkuli OpenCL 2.0 implementaciok mennyire kezdenek el terjedni. Mert ugye szep dolog HSA-ra fejleszteni, csak epp jelenleg 1 (egy) darab olyan vas van a PC-s vilagban, ami ezt kepes futtatni is, es abbol raadasul baromi keveset is adnak el, tehat a teljes PC-piacra nezve nagyon alacsony a penetracioja a HSA-ready hardvernek. Szoftver fejlesztokent ha donteni kell, hogy OpenCL 2.0 vagy HSA, es mindkettot tamogatja a Kaveri, viszont az OpenCL 2.0-t az aktualis Intel mainstream desktop/mobil processzor is, akkor sok fejleszto inkabb az OpenCL 2.0-ra fog szavazni. Amiben szepen fog hasitani nyilvan a Kaveri is, viszont a Broadwell/Skylake is, noha ott mar egyaltalan nem biztos (sot), hogy az Intel megoldasa lesz gyorsabb. Erdekes lesz, ha vegre OpenCL 2.0-n is egymasnak tud majd feszulni az AMD es az Intel iGPU-ja
-
Vitamincsiga
tag
válasz
leviske
#14128
üzenetére
A 4 csatornás memóriavezérlővel kapcsolatban némileg visszakozom - ha lesz is, az csak az Intel hasonló terméke ellen fog kijönni; aranyáron.
A miért, az a Hynix-szel közös HBM memória fejlesztés. Tény és való, hogy az AMD innováció terén mérföldekkel mindenki előtt jár! Szerintem - rajtuk kívül - még most sem fogtuk fel igazán annak a döntésüknek a súlyát, ami az ATI felvásárlása jelentett. /HSA, Mantle, konzol APU-kstb.; nem tétlenkednek és jó kérdés, hogy mi van még a tarsolyukban, amiről nem tudunk semmit sem /
Biztos lesz sokkal gyorsabb memória átvitel, de mikor és a hogyan még képlékeny.Hogy mi az optimális memória sávszélesség egy adott APU-t (ki)használó programnál?
Látod, én csak a CPUGPU arány firtatásáig jutottam el, de a te felvetéseddel teljes a kérdés!!
Mi az az APU konfiguráció, ami a legjobban lefedi a rá írt programok nagyobbik részét?!
Aki - gyártó - tudja, az kaszálni fogA nagy "gémercégek" a PS4-ben is pár plusz CU-t láttak volna szívesen
Az elmúlt heti friss hír szerint az x86 és az ARM egyféleképpen történő házasítása a GNC-hez sok kérdésre egész más választ ad!
Lehet, hogy a Carizzo végállomás lesz, ami a csak a magas órajelre optimalizált magokat - modult - jelenti? /A modul elv ettől még reinkarnálódhat egy ALL-IN-ONE egységként, de az egy sokkal későbbi fejlesztés eredménye lehet./
Lehet, hogy egy kicsit magasabbról induló, jobban skálázható x86-os architektúrát akarnak? /Az ARM-os fejlesztés pedig kielégíti az alacsony fogyasztású cuccok követelményeit./ A csúcs konfigoknál pedig a látszólag kieső teljesítményt az alacsonyabb fogyasztás és a kisebb magméret miatt több maggal pótolják?A Carrizo és a Beema sínen van, a 32-28nm-en is lassacskán túljutnak; a teljesítmény pedig csak fog egyszer drasztikusan nőni már
-
Abu85
HÁZIGAZDA
válasz
leviske
#14141
üzenetére
Nem különösen lényeges már a gyártástechnológiai különbség. Egyszerűen, ahogy haladunk lejjebb annál kevesebb lesz az előrelépés. Szimplán a fizika törvényei megakadályozzák, hogy bizonyos határok alá menjünk, és nagyjából a 30-10 nm közötti szinten ezeket a határokat elértük/elérjük. A CMOS nagyjából 32 nm-nél kifújt. Innentől már csak apró fejlődés tapasztalható. A legtöbb teljesítmény és fogyasztáselőny abból jön, hogy miképp tervezik meg a fizikai dizájnt a sematikusból. Itt lehet sokat nyerni nem a nanométereken.
-
Fiery
veterán
válasz
leviske
#14135
üzenetére
A Larrabee-t nemtom, miert kell idekeverni. Ennyi erovel a Hawaii XT-t is felhozhatod peldanak, de egy CPU/APU kerdesnel a dGPU- es a HPC acceleratorok nem igazan relevansak. Egy hagyomanyos CPU foglalatba bajosan raksz bele egy 300W TDP-ju monstrumot. Vagy ha bele is rakod, otthoni desktop kornyezetben nem fogod tudni epeszu modon lehuteni. Ertelmetlen me'g elmeleti szinten is ilyenekrol beszelni egy olyan vilagban, ahol epp ellenkezo iranyba mennek a dolgok; azaz generacionkent folyamatosan csokken az alaplap+CPU+chipset osszesitett TDP-je (AMD-nel es Intelnel is).
-
Abu85
HÁZIGAZDA
válasz
leviske
#14135
üzenetére
Írtam, hogy a tranzisztor/mm2 arányt ma nagyrészt az alkalmazott "thin library" határozza meg. Nem sok köze van a nm előtti számhoz. De amúgy hiába lesznek itt tizenx nm-et az Lgate érték nem csökken majd drasztikusan. 20 nm alá egyik készülő node sem megy.
(#14136) dezz: De az AMD már bejelentette. A HSA-hoz a fejlesztők rendelhetnek egy teljes platformot. Az a Kaveri APU-t és egy ASUS alaplapot takar olyan BIOS-szal, amit ma még nem érhetsz el. Ennek a csomagnak a része egy OpenCL 2.0-s driver is az összes funkció támogatásával. Ezzel együtt jelentették be, hogy a Q4-re lesz publikus OpenCL 2.0-s driver Kaveri APU-ra és Hawaii GPU-kra. A többire még nem volt bejelentés.
Az Intel valóban nem jelentette be, de a fejlesztők rendelhetnek egy platformot hozzá. A Pipes és a C11 Atomicsen kívül mindent támogat. Illetve az aktuális driverekkel még nincs nested parallelism (ez csak le van tiltva), de SVM van.
Nagyon fontos, hogy az Intel is kínáljon valamit ma, mert ők is ugyanúgy ragaszkodnak ahhoz, hogy PC-re is legyenek portolva az új konzolos játékmenetek. Emellett nekik is marha kellemetlen, hogy a Havok tartalmaz egy rakás izgalmas, új funkciót a konzolokhoz, amit PC-n nem érhetnek el a fejlesztők. Erre lesz elsődlegesen OpenCL 2.0 támogatásuk, hogy végre ezeket a funkciókat PC-be is portolhassák. -
Fiery
veterán
válasz
leviske
#14128
üzenetére
Tahiti: 365 mm2 + Vishera: 315 mm2. Ezt nehez lenne legyartani integralva, plane ertelmes TDP mellett. Nyilvan 14 nanora lehozva valamival kisebb die lenne (bar nem eleg kicsi), de az AMD akkor sem ebbe az iranyba megy jelenleg.
A Broadwell azert "most", mert mar elkezdtek a partnereknek szallitani az ES peldanyokat. Ergo mukodik a cucc, mar most tamogatja az OpenCL 2.0-t. Mas kerdes persze, hogy mikor kerul az egyszeru foldi halandok gepebe ez a proci, de az Intel igerete szerint iden me'g mindenkepp. Ergo semmikepp sem 1-2 ev, mire megerkezik, hanem max. 7,5 honap.
-
Vitamincsiga
tag
válasz
leviske
#14122
üzenetére
Mivel még nincs még meg az A8-7600-asom
 , így a korában, az egyik hozzászólásomban feltett kérdésre nem tudom a választ. Mi lenne az optimális aránya a CPU/IGP-nek, illetve az FPU/CU-nak, az ezt kihasználni tudó programok java részében? /Bár valószínűleg, a tudományom tükrében ehhez a kérdéshez, kevés vagyok
, így a korában, az egyik hozzászólásomban feltett kérdésre nem tudom a választ. Mi lenne az optimális aránya a CPU/IGP-nek, illetve az FPU/CU-nak, az ezt kihasználni tudó programok java részében? /Bár valószínűleg, a tudományom tükrében ehhez a kérdéshez, kevés vagyok  /
/Amit Tőletek sikerült leszűrni - cikkek és hozzászólások formájában - az az, hogy van grafikus motor gyártó, aki már most 32 szálig skálázhatóra fejleszti a következő generációs termékét. A PS4 majd' 2 TFlops-ot tud, de 4k-tnem. A HSA mindenkit érdekel! Az Radeon R9 280X 250W-ból hoz ki 4TFlops-ot. A Win9 sok kicsi magot, mélyen integrált DX12-öt hoz majd. Stb...
A másik része, pedig az igények! Enyém, tiétek, bárkié. Ha 1.000$ alatt lesz egy ~50"-os, jó minőségű, 4k-s monitor(+TV), megveszed? Én tuti!
Ehhez - ha már ott van - viszont kakaó kell, ami jelenleg nem áll rendelkezésre, de a kielégítésén a gyártók és a fejlesztők gőzerővel dolgoznak. /A tegnapi HW-t, holnap nem lehet még egyszer eladni.../A 8-16 szál a - HSA! - magasabb fokú APU kihasználtságoz szerintem jól jöhet. /Az Intel készül valami 8c/16t-es erőművel!/
A 300W-os TDP osztály - AMD 5 GHz-es szörnye ~200W - még nincs, de ez is egy út. /Nekem kéne /
A 4 csatornás memóriakezelés is. Mert ez is egy szűk keresztmetszet.
/Igen ez drága lesz... A Radeon R9 280X listaára 299$, a Radeon R9 295X2 pedig 1.499$ 3x-os teljesítmény 5x-ös ár./Abban egyetértünk, hogy 14 nm-ig az AMD nem fog tudni nagyot dobni! De az, mi lesz?
-
Vitamincsiga
tag
válasz
leviske
#14105
üzenetére
Az Excavator utáni időben - ha igaz a szél szárnyán kelt hír - a CU betelepedne a modulba.
Egy modul tartalmazna min 2 ALU-t, 1 FPU-t és min 1 CU-t. Egy modult pedig min 2 szálat jelentene.
Az Exvavator már a közös vmem-el is elboldogul, a többin pedig biztos reszelnek addig. Az utáni időkben a cache kezelés a jó kérdés, de egyéb probléma biztos akadna a koncepcióban szép számmal.
A HSA szemszögéből pedig ez egy dögös OC-nak felelne meg, mert már nem csak a mem tér lenne közös, hanem a cache tér is! Rém pongyola vagyokTudom - a fanok kivételével - mindenki ki van akadva a Bull gen gyengélkedésére. De a fenti elgondolásban, viszont a legjövőbelátóbb koncepció! Ráadásul mindez illik a MS - Win9 - sok, kicsi mag koncepciójába.
Engem még mindig az aggaszt, hogy miért nem vállalja fel az AMD a power júzereket?!
~300W TDP osztályú foglalat, 8-16 mag, 4 csat mem... Lenne valakinek is ellenvetése, ha jövő ilyenkorra lenne 4 TFlops-os APU -
Abu85
HÁZIGAZDA
válasz
leviske
#14105
üzenetére
Semennyi. Az x87/MMX/SSE/AVX nem teljesen külön ISA, hanem egy utasításkészlet, ami az x86/AMD64-re építkezik. Ennek vannak követelményei a memóriamodellre vonatkozóan. Például az x86 memóriamodellje, ezen belül is az, hogy az egyik szál által kiírt adatokat a másik szálnak látnia kell a következő ciklusban hihetetlenül fos egy data parallel architektúrához. A több tízezer szálat kezelő GPU-knál nagyon kritikus, hogy a memóriaműveletek és a koherencia kezelése ne legyen ennyire merev, különben az egész rendszer nem fog működni. Minél több szál van annál nagyobb lesz az igény a trükkös megoldásokra, amelyeket egyébként minden GPU alkalmaz. Elsősorban azért is cserélik az ISA-t a GPU-knál 4-6 évente, mert minden ISA-nak van egy szálkorlátja, ami után már nem skálázódik a teljesítmény.
-
Fiery
veterán
válasz
leviske
#14107
üzenetére
Ha az ISA (utasitaskeszlet) problemat fel tudja oldani valahogy az AMD, akkor semmi sem elkepzelhetetlen. Csupan az a kerdes, hogyan lehetne ezt megoldani, es mennyire lenne ertelme. Mert ha mondjuk azt vesszuk, hogy egy 1 szalas AVX vagy AVX2 kodot az x87 FPU vagy a GCN tudna-e gyorsabban vegrehajtani, akkor mar csak az orajelbeli nem csekely kulonbseg miatt is a GCN joval lassabban vegezne. Az egesz GCN-nek akkor lenne csak ertelme, ha sok szalrol, massziv parhuzamositasrol lenne szo, de ott meg a HSA jon be a kepbe, nem a nativ x87/SSE/AVX.
-
Fiery
veterán
válasz
leviske
#14105
üzenetére
A GCN nem x86-os architektura, tehat egy x86/x87 FPU helyét nem fogja tudni atvenni. Mas kerdes lenne, ha mar a kutya nem hasznalna x87, SSE es AVX utasitasokat, de ugye ez nem egeszen igy van
Persze a Transmeta megoldasahoz hasonloan elmeletileg elkepzelheto lenne egy szoftveres reteg, ami atforditja az x87/SSE/AVX utasitasokat a GCN nativ utasitasaira, de ez nagyon hajmereszto elkepzeles, es szerintem az AMD egesz mas dolgokkal van most elfoglalva (pl. HSA).
-
Fiery
veterán
válasz
leviske
#14059
üzenetére
Az AVX-512 tobbek kozt azt jelenti, hogy 512 bites vektor adatokkal tud dolgozni az FPU. Kerdes, hogy egy adott muveletet (pl. osszeadas, szorzas, osszeadas+szorzas egyszerre, stb) milyen sebesseggel hajt vegre egy processzor. Ha mondjuk feltesszuk, hogy hasonlokepp implementaljak az AVX-512-t a Kaveriban es a Haswellben is, akkor sajnos a megosztott FPU miatt mindenkepp a Kaveri fog kikapni, eleg csunyan. Kerdes persze, hogy mire az AVX-512 bekerulhet egy AMD processzorba, addigra melyik architektura marad meg vegul az AMD-nel: a mostani Bulldozer, vagy a Kabini alapjat ado Jaguar. Ez utobbinal ugyanis nincs megosztott FPU, viszont az AVX utasitasok vegrehajtasa sem tul gyors. Nem a teljesitmenyre van a Kabini/Jaguar, hanem az alacsony fogyasztasra ugyebar.
A GPU-nak az AVX-512-hoz nem sok koze van. Hacsak nem egy x86 GPU-t (MIC) veszunk, ami AVX-512 alapokon mukodik, de azt leghamarabb 2015 kozepen (Skylake) kapjuk csak meg, ha megkapjuk egyaltalan.
-
Fiery
veterán
válasz
leviske
#14041
üzenetére
Az AVX-512 nem kulonbozik olyan sokban az SSE-tol, csak szelesebbek a regiszterek es tobbfele utasitas van, sok mindent nagyon "kenyelmesen" meg lehet vele oldani. Ha valaki veszi ra a faradsagot, akkor nagyon szep teljesitmenyu kodot lehet AVX-512-re irni. Ha mondjuk a Haswellt (4770K) vesszuk alapul, csak a CPU reszt nezzuk, es mondjuk ebbe pakolunk AVX-512-t, akkor kapasbol magasabb elmeleti lebegopontos teljesitmennyel (866 GFLOPS) gazdalkodhatunk, mint a Kaveri iGPU-janal. Arrol ne is beszeljunk, hogy ha a Skylake-nel -- tegyuk fel -- a CPU es az iGPU is megkapja az AVX-512-t, es az iGPU-t is tudod direktben programozni, akkor az aggregalt lebegopontos teljesitmeny egeszen jopofa mereteket (pl. 1.5 TFLOPS) olthet
Persze inkabb az az eselyes, hogy a Skylake utan, a Goldmont kornyeken konvergal majd csak az AVX-512-vel a CPU es az iGPU, es vegre megszabadulunk a GPU-tol -- ami eddig is csak egy kenyszer szulte nyakatekert megoldas volt. -
Fiery
veterán
válasz
leviske
#14039
üzenetére
A HSA annyibol lehet jo dolog az atjarhatosag/portolas szempontjabol, hogy ha egy adott szoftver adott reszfeladatat HSA-ra fejlesztik (es pl. konkretan OpenCL-ben vagy Javaban irjak meg), akkor az az adott resz remekul portolhato lesz barmilyen HSA-compliant rendszerre. Ez azonban me'g baromi keves, es valojaban nem sokat segit egy komplett szoftver portolasanal.
Hogy egy konkret peldat is mondjak. Pl. vegyuk az AIDA64-et. Egy bazinagy szoftver (cca. 1 millio kodsor mindennel egyutt), amit nagyon nagy melo lenne x86 Windowsrol barmi masra portolni. Ha az AIDA64 OpenCL benchmarkjait atdobod HSA-ra (nem nagy melo), akkor az OpenCL benchmarkokat szabadon tudod onnantol portolni barmilyen mas HSA-s platformra -- ami egyelore nem letezik, hiszen az x86 Windows Kaverival az egyetlen letezo HSA-s platform ugyebar
De ha lenne mondjuk HSA-s OSX vagy iOS vagy Android vagy barmi mas, akkor oda az OpenCL benchmarkokat egyszeruen lehetne portolni. A gond az, hogy magukat a benchmark metodusokat tudod csak igy portolni, minden mast is at kell vinni az uj platformra. Ha pl. csak az OpenCL benchmarkokat nezzuk (es nem az egesz AIDA64-et), akkor a GPGPU Benchmark panelt kellene mint felhasznaloi interfeszt lekodolni az uj platformon, es az ala "betolni" a HSA-s benchmark metodusokat. Nyilvan ez nem egy oriasi feladat, de egy komplett szoftvernel maga a HSA-s resz altalaban marha kicsi/rovid.Azt sem szabad elfelejteni, hogy egy komplett szoftver portolasanal altalaban a felhasznaloi felulet a legnehezebben portolhato, azzal van a legnagyobb gond, ha at kell vinni valahova. Kiveve persze az olyan specialis eseteket, mint az OSX <--> iOS, ahol kicsit konnyebb ezt megoldani. A felhasznaloi felulet ujrairasa/portolasa utan az "engine" portolasa mar altalaban kisebb melo szokott lenni, azzal sokkal konnyebb megbirkozni.
-
Fiery
veterán
válasz
leviske
#14029
üzenetére
Az ARM-mal nem az a problema, hogy hogyan torsz be, hanem az a platform ami az ARM alapu cuccokon fut (legyen szo Android, iOS vagy WP8/RT-rol), hogyan teszi lehetove a munkad penzre valtasat. Epp a napokban volt hir rola, hogy egyre kevesbe fizetnek az emberek az app-okert. 1 dollart sem, 1 eurot sem adnak ertuk. Ez a problema, nem az, hogy hogyan torsz be a piacra
A HSA-t (sot az OpenCL-t sem) pedig jelenleg egyik tabletes/mobiltelefonos platform sem tamogatja _altalanosan_. Az asztali Windows lesz az elso, ami ezt tamogatja, azon kell a fejlesztoknek eloszor megbaratkozni a HSA-val.
-
Abu85
HÁZIGAZDA
válasz
leviske
#14021
üzenetére
A HDL-t már rég használják. Már a Brazosban is bevetették. Azóta egyre több CPU-részt HDL-lel terveznek. A GPU-kat meg eleve ezzel tervezték mindig.
Az, hogy FX APU van tervben még nem jelent négy modult. Teljesen más az AMD stratégiája, amióta több mint egy tucat játékfejlesztőt maguk mellé állítottak. Tőlük garanciát kaptak, hogy kihasználják a technológiáikat, ha olyan irányba fejlesztenek, amit ők kérnek. Ennek az eredménye minden amit ma látsz. A fejlesztők megkapták, amit kértek, így most rajtuk a sor. Jelenleg 40+ játék készül, ami HSA/Mantle/TrueAudio trió valamelyikét, vagy mindegyiket használja. És nagy brandek (pl.: Star Wars). Ezért lett leállítva a sima CPU-s vonal, mert az új irányból nem profitál.
-

atti_2010
nagyúr
válasz
leviske
#14001
üzenetére
De akkor miért nem oldották meg a GDDR5 verziót hiszen az árakat biztosan tudták jóval előtte, gondolok itt a GDDR 1-2GB modulokra és a többrétegű alaplapra is, szerintem ok sem akarják egyelőre kinyírni az összes VGA-t R9-8xx alatt, mert egy olyan megoldás könnyen megtehetné és az útiterv is arról szól hogy APU+dVGA és nem arról hogy csak APU.
-
Fiery
veterán
válasz
leviske
#13982
üzenetére
Az alapveto problema az volt, hogy a HP, Lenovo, Dell, Acer kozul egyik gyarto sem vallalta volna be a GDDR5-os PC-t (legyen az alaplap, desktop, notebook, tablet, 2-in-1, 3-in-1, all-in-one, stb). Tul draga a memoria, nem bovitheto, es nem hoz eleget teljesitmenyben. Egy high-end Intel alapu cuccban talan elfert volna egy ilyen megoldas, mint ahogy a Crystal Well-re is van egy igen vekony piac. De amig az Intel reszesedese ezekben a felso regiokban mondjuk 99%, addig az AMD-e legjobb esetben is 1%. Az utobbira nem erdemes epitenie a gyartoknak. Ez van, ilyen az elet...
Mas kerdes, hogy az Asus (ami hires arrol, hogy mindent epit, amit csak el lehet kepzelni) epitett volna-e alaplapot GDDR5 memoriaval. Talan egyet csinaltak volna, ha maskepp nem, koncepcio/prototipus szinten. De egyetlen ilyen potencialis alaplap miatt az AMD-nek nem eri meg levalidalni a GDDR5 tamogatast.
-------
Carrizo leghamarabb jovo ev tavasszal erkezik, de inkabb a szeptember az eselyes. Addig nem hiszem, hogy erdemes varni, ha a Kaveri amugy szimpatikus a potencialis vasarlonak.
-
Fiery
veterán
válasz
leviske
#13975
üzenetére
No offense, de nem sokan adnanak 500 dollart egy Kaveri alaplapert...

Sokkal jobban megdobná a koltsegeket a GDDR5, mint amennyit hozna teljesitmenyben. Az sem veletlen, hogy a Crystal Well nem terjed(t) el jobban: az is sokkal dragabb egy alig lassabb Core i5/i7-hez kepest, es nem hoz annyit, nem fizetik meg a vasarlok.
-

Thrawn
félisten
válasz
leviske
#13975
üzenetére
A PS4-ben kb 88 dollárba kerülnek a RAM-ok: [link]
Nem ezzel van a baj, hanem azzal amit Fiery is írt: validálás, BIOS, stb. Ez elég sok idő ám, ha megpróbálták volna összehozni a Kaverivel, lehet csak Q4-re lett volna belőle kész termék a polcokon.szerk: egyébként ha a Carrizo tényleg ennyi minden új dolgot fog hozni, lehet érdemes átgondolni a gépfejlesztést és kihagyni a Kaveri-t.
-
Fiery
veterán
válasz
leviske
#13667
üzenetére
Ha a nyers savszelessegrol beszelunk, akkor teljesen mindegy, hogy dGPU-rol vagy iGPU-rol van szo. A CPU is mindegy. Persze megint mas kerdes, ha abbol a szemszogbol nezzuk a dolgot, hogy mikepp tudod kihasznalni a GPU szamitasi erejet: ott a Mantle es a HSA sokat segithet (majd), es reszben ellensulyozhatja is a relative szukos savszelesseget.
-
Oliverda
titán
válasz
leviske
#13638
üzenetére
Az a baj, hogy túl sok az OFF, aminek rendszeres gerjesztője illetve résztvevője vagy.
Az Intel tényleg rohadtul fog örülni, hogy a mantlés címekben majd bottal üthetik a GCN-es IGP-k nyomát. Biztos azért dolgoznak ők is saját API-n, mert azzal a konkurenciának segítenek.
A téma itt lezárva. Legközelebb az ilyeneket törlöm és akkor nem lesz belőle vita.
-
Fiery
veterán
válasz
leviske
#13589
üzenetére
A slide aljan a csillagos megjegyzest is olvasd hozza a 20%-hoz
Plusz vedd hozza, hogy jelen allas szerint kb. 10%-kal alacsonyabb orajelen startol a Kaveri, mint az A10-6800K (Richland csucsmodell). Ergo az x86 resz teljesitmenye jo esellyel nem lep elore szinte semmit, legalabbis kezdetben. -
Fiery
veterán
válasz
leviske
#13567
üzenetére
Amig az AMD reszesedese a teljes x86 piacbol 2 szamjegyu, addig az Intel nem fog ra nem-konkurenskent nezni. Amit a VIA csinal, az mas teszta, ok nem tetel az Intelnek, nyilvan, de az AMD epp most izmozik, helyezkedik egy csomo fronton (konzolok, Mantle, HSA, Jaguar), pont most kell odafigyelni ra, nem "szem elol teveszteni"
-
Abu85
HÁZIGAZDA
válasz
leviske
#13542
üzenetére
A HSA programok nyolc technika meglétét hasznosíthatják (ezek a HSA direktívák). Ha ebből egyik sincs meg, akkor a program legacy módban fut. Ha az egyik is megvan, akkor már normál módban megy. A sebességnövekedés és a futtatás hatékonysága attól függ, hogy hány direktíva van támogatva. A technológiák közül messze a hUMA a legfontosabb, ami három direktívát fogalmaz meg, és a HSA alapítványon belül eldöntötték, hogy ezekre a lapkákra írják rá a HSA támogatást. Például a hQ-t és a kapcsolódó egy direktívát támogatja a Kabini/Temash is, de ez nem olyan fontos, mint a hUMA.
Az utolsó három direktíva elsősorban a Linux miatt lesz fontos, mivel ez az OS nyitni fog a HSA felé, és ott számítani fog, hogy a IGP tud-e QoS-t, és van-e preempció a grafikára. Ez azért fontos, mert az OS feladatok egy része is a IGP-n fut, illetve meg kell oldani, hogy több felhasználós legyen az IGP használata, ahogy a CPU is az. -
Fiery
veterán
válasz
leviske
#13542
üzenetére
Magukat a HSA-ra optimalizalt szoftvereket ez nem igazan erinti. Fejlesztoi szempontbol a Kaverin is remekul lehet (majd) dolgozni. Nincs me'g teljesen kesz az SVM implementacioja a Kaverin, de azok a kisebb puzzle darabok, amik kimaradtak, a Carrizoval potlasra kerulnek. A "klasszikus" HSA evolucios slide-on jol latszik, hogy a 2014-re tervezett (Carrizo) feature-okkel egyutt lesz teljes a HSA -- de ezek mar nem olyan nagy dolgok, marmint a HSA-ra valo fejlesztest ezek nem hatraltatjak:
Meg persze az L2 cache kezeles nem teljesen optimalis a jelenlegi (Richland, Kaveri) felallasban, de az nem jelent problemat a HSA-nal.
-

Valdez
őstag
válasz
leviske
#13538
üzenetére
Hát akkor lehet kénytelen leszek intelre fejleszteni meg valami izmosabb vga-ra, mert ugyan lesz 1-2 játék amit beharangoztak, hogy mantle-s lesz és engem is érdekelne, de azért nem szopatnám magam feleslegesen nem mantle-s címek alatt ilyen "gyenge" konfiggal, mint amit egy kaveri + cape verde nyújtana.
-
Valdez
őstag
válasz
leviske
#13535
üzenetére
Bármit köthetek a kaveri mellé és akkor lesz asszimetrikus feladatmegosztás? Az a bármi az gcn kell hogy legyen és api meg mantle kell legyen nem? És ha nincs mantle? Akkor marad a 7750 meg 250-es, ami kevéske.
Ezért reméltem hogy lesz dg-ben 260x is, mert akkor legalább "gépfejlesztéskor" lenne érzékelhető grafikai teljesítménykülönbség is a mostani cuccomhoz képest nemcsak mantle alatt. -
Abu85
HÁZIGAZDA
válasz
leviske
#13407
üzenetére
A HDL egyelőre csak a TSMC-nél van és a Bobcat/Jaguar már használja. A Glo-Fo esetében kizárt, hogy 32 nm-es SHP-ra implementálnak HDL-t. Ennek nem lenne értelme.
Egyébként a HDL-t nem kell próbálni, lassan 8 éve használják a GPU-khoz. Semmi extra nincs benne, csak nehéz ilyet fejleszteni. Az AMD-nek speciel pont ezért kellett az ATI, mert megvették vele a HDL-t is. Azt visszaimplementálják procira. Egyébként HDL-féle technikát használ az NV és még az ARM/Imagination/Qualcomm trió is. A fizikai implementációkban érdekelt cégek közül egyedül az Intel nem használ ilyet. -
Fiery
veterán
válasz
leviske
#13320
üzenetére
Az, hogy kinek az elgondolasa jobb, majd az ido eldonti. Nyilvan ahol nincs AVX es/vagy FMA, ott elonyben lehet az OpenCL, meg persze az olyan APU-knal is jol jon az OpenCL/HSA, ahol az x86/x64 lebegopontos teljesitmeny me'g AVX-szel egyutt sem tul izmos (pl. Kaveri, Kabini, stb), de csereben van egy remek iGPU.
A Google nem tamogat semmit, maximum megturi a HSA-t az Androidban. Megint mas kerdes, hogy az androidos fejlesztok mennyire fognak optimalizalni barmilyen szoftvert HSA-ra. En inkabb a jatekoknal latok erre eselyt, mintsem a hetkoznapi szoftvereknel. A hetkoznapi szoftverek tulnyomo tobbsege nem performance orientalt, a fejlesztok meg amugy is el vannak lustulva kicsit (meg sok a dolguk is, 3-4 fele platformra kell portolni a telefonos/tabletes szoftvereket), az Android nem arra nevelt eddig se, hogy tul optimalis kodot keszits... En a HSA elterjedeseben elobb szamitok az x86 alapu, Windows 8.1-es tableteknel a HSA-s szoftverekre, mintsem Androidon, Windows Phone-on vagy Windows RT-n.
-
Fiery
veterán
válasz
leviske
#13318
üzenetére
Nehez kerdeseket feszegetsz
Alapvetoen a DP nem lenyeges a legtobb hetkoznapi szoftver eseteben, azok ugyse hasznalnak DP-t, vagy nem lenyeges a DP sebesseg, nem az a donto. Az meg hogy egy adott szoftver, egy adott hardver eseteben milyen optimalizacioval erheto el a legkedvezobb teljesitmeny/fogyasztasi mutato, nos, az erosen fugg az adott szoftvertol Sajnos a legtobb szoftvernel nincs lehetoseg a vegletekig kicsontozni, szénné optimalizalni a kodot, igy en amondo vagyok, amig a HSA el nem terjed (min. 1 ev mostantol, amig rendesen felepul az egesz), addig egyszerubb azt figyelni, hogy az altalanos felhasznalasu, klasszikus szoftverek -- amikben nincs se AVX optimalizacio, se OpenCL vagy HSA kod -- mikepp viselkednek egy adott vason. A HSA egyebkent nem egyhamar fog elterjedni a telefonokon es egyeb ultramobil eszkozokon, ugyanis se az Android nem szivleli az OpenCL-t, se az AMD-nek nem lesz jovore HSA-kepes ultramobil APU-ja Egyelore inkabb a desktopra es a hagyomanyos notebookokba megy majd a Kaveri, 1 utas szerverekbe a Berlin, jovore meg -- ha minden jol megy -- a Kaveri utodja (Carrizo). -
Fiery
veterán
válasz
leviske
#13311
üzenetére
Nagyban fugg ez attol, hogy mit akarsz pontosan csinalni, es milyen processzorra tervezed az applikaciot. Ha Atomra, akkor az nehez kerdes, hiszen az Atomok jelenleg nem tamogatnak AVX-et, az OpenCL teljesitmenyuk pedig csapnivaloan rossz. Ha viszont nem az Atomokrol van szo, akkor adott esetben jobb teljesitmenyt lehet elerni AVX+FMA-val, mint iGPU-val, ha mondjuk Haswellrol van szo. De a legtobb esetben forditott a helyzet, pl. az osszes AMD processzornal joval nagyobb tejlesitmenyt lehet elerni az iGPU-val, mint AVX-szel.
-
Fiery
veterán
válasz
leviske
#13264
üzenetére
A Mantle-rol az AMD csak az APU13 utan fog beszelni, addig csak azokkal targyal rola, csak azokkal osztja meg a Mantle-capable Catalystot is, aki konkretan Mantle-re fejlesztenek jatekot. Kivancsi leszek en is, hogy mire kepes a Mantle, milyen hozadeka lesz osszessegeben.
A Mantle-vel kapcsolatban azert pozitivak a varakozasaim, mert pont ilyesmit szerettem volna latni, ilyesmirol beszelgettunk az egyik topicban, a Mantle bejelentese elott par hettel -- pedig tenyleg nem tudtam, hogy jon a Mantle. Persze me'g jobb lenne, ha tenyleg direktben lehetne programozni a GPU-kat, de athidalo megoldaskent a Mantle is remek lesz. Kezdett mar tulsagosan is langyos pocsolya lenni a PC-s jatekipar es 3D megjelenites, jo dolog, hogy az AMD beledobott egy kovet az allovizbe

-
Fiery
veterán
válasz
leviske
#13243
üzenetére
Egy szoval tudnek reagalni: f***sag. A Kaveri iGPU-ja franko, annak a kozeleben sincs semmi, ami Intellel kezdodik. A tobbi meg olyan, mint a Richland, csak kicsit faragtak rajta. Semmi attores, semmi oriasi durranas. Nincs AVX2, nincs szelesebb EU, nincs tobb mag, nincs tobb modul, nincs gyorsabb vagy szelesebb memoriabusz. A Haswell (de me'g az Ivy Bridge is) biztonsagban vannak. Lehet persze talalni olyan benchmarkokat, ahol a Kaveri egy-egy fejlesztese kimutathato elonnyel jar (az AIDA64 benchmarkjai kozott is van ilyen, de nem mondom meg, melyik). Nyilvan lehet 30-40%-os gyorsulast is mérni, ha valaki kifejezetten arra megy ra, hogy ilyen szamokat tudjon produkalni. Varjuk meg az elso real-world teszteket, azok erdekes kepet fognak festeni.
-
Fiery
veterán
válasz
leviske
#13231
üzenetére
"Volt már próbálkozás saját API-ra és bukott is már bele gyártó a dologba"
A 3Dfx felvasarlasa (2000) ota melyek voltak ezek az API-k? Nem kotozkodni akarok, csak kivancsi vagyok, mert nekem nem remlik azota egy olyan API sem, ami ezt celozta volna, es megbukott volna. A '90-es evekben volt sok ilyen (Glide, Apple QuickDraw3D, S3 Metal, stb), ez teny, de a 3Dfx felvasarlasa pontot tett ennek az idoszaknak a vegere, legalabbis en igy emlekszem.
-
Fiery
veterán
válasz
leviske
#13229
üzenetére
Az AMD eleve nyitott platformnak tervezte a HSA-t, ez abszolut jo dolog, es reszben ez is kell ahhoz, hogy sikerre tudja vinni az otletet. Nekem mondjuk kicsit furcsa, hogy az Xbox1 nem HSA-s, emiatt nem mernek rola meggyozodni, hogy a Mantle a HSA-t magaval tudja "rantani" a sikerbe, de ugy legyen.
A lemasolas kapcsan csupan annyi a veszely, hogy ha kompatibilis is lesz, a masik "vonulat" adott esetben mas iranyba terelheti a fejlesztest, mas, adott esetben egyszerubben programozhato vagy gyorsabb termeket pakolhat ala, amivel megtorpedozhatja az AMD sajat HSA implementaciojat. Nyilvan ha ugyesen csinaljak a gyartok, akkor minden mindennel kompatibilis maradhat, de akkor meg az egesz elvesziti a "varázsát" (mint ahogy most sem kerdeses az, hogy mondjuk melyik GPU tamogat D3D-t vagy OpenGLt -- hiszen mindegyik, igy ez nem kerdes), es a vegen a teljesitmeny marad a donto. Amiben meg vagy tudja tartani a biztonsagos elonyet az AMD, vagy nem, majd kiderul.
Hasonlokepp, a Mantle is csak addig biztosit kenyelmes elonyt az AMD reszere, amig egy masik gyarto meg nem csinalja a sajat Mantle-jet, ami adott esetben -- reszben -- kompatibilis is lesz vele (ha ezt megteheti). A Mantle azert van nagyobb "biztonsagban", mert az nem nyilt szabvany.
A HSA kapcsan egyebkent azt tartom furcsanak, hogy szinte mindenki meg van gyozodve arrol, hogy "this is the next best idea", es hogy nincs semmi eselye, semmi ertelme, semmi lehetosege egy masik "next best idea"-nak. A Mantle-rol se gondolta volna senki (marmint komolyan), hogy ezt fogja meglepni az AMD. Az AMD konkurenseirol pedig most nem sokan gondoljak, hogy a HSA nelkul eselyuk lehet, pedig lehet hogy egyik percrol a masikra elsopri a HSA-t mondjuk egy ujabb "next best idea", amivel (még) jobban meg lehet oldani ugyanazokat a problemakat. Majd meglatjuk, elso korben fusson be a HSA, legyen mi ellen kuzdenie a 2 morcos ellenfelnek (Intel, nVIDIA)
-
Fiery
veterán
válasz
leviske
#13218
üzenetére
"Ha ők előállnak évekkel később egy megoldással "úgyis az ő megoldásuk lesz elterjedtebb", ha lemásolják, akkor is... Remélem erre még emlékszel, ugyanitt írtad."
Igen, igy van. Vagy ha visszanezel a multba, nem ezt latod? Az AMD kitalal valamit, majd az Intel megcsinalja lenyegeben ugyanazt, es elad 3-4x tobb termeket vegul. Mondtam, hogy orulok ennek? Nem. Mert nem is orulok neki, ez egy szomoru dolog, de ez van. Ha visszaolvasol, az egesznek az uzenete pont az volt, hogy az AMD-t attol _féltem_, hogy a HSA-t mas (legyen az Intel, nVIDIA vagy barki mas) lekoppintja es sikerre viszi a masolatot. De ha egeszen oszinte akarok lenni, nem szeretnem, ha ez bekovetkezne, mert inkabb azt szeretnem latni, hogy az AMD "egyedul" (tudom, hogy baromira nem egyedul csinaljak, de a PC-s fronton lenyegeben egyedul) sikerre vigye a HSA-t. En nem hiszek _annyira_ a HSA-ban, mint pl. Abu, de amint az egesz hasznalhato format ont, es elkezd terjedni, ki fog derulni, hogy a (SZVSZ tulzott) hype indokolt volt-e. En pl. ha fogadni kene, a kis penzemet inkabb a Mantle-re raknam, mint a HSA-ra. Az SZVSZ egy baromi jo irany. Es itt nagyon OFF.
-

dezz
nagyúr
válasz
leviske
#13188
üzenetére
A CPU továbbra is kis számú, de komplex programszál végrehajtására alkalmas a leginkább, a GPU pedig sok-sok egyszerűbb szál végrehajtására. (Adott esetben persze szét lehet szedni egy feladatot CPU-n és GPU-n futtatott részfeladatokra, melyek kooperálhatnak is egymással.)
Emellett ott vannak még a meglévő programok is, amiket szintén tudni kell rendesen futtatni. Kicsit körülményes lenne minden egyes FPU-s utasítás miatt a GPU-t zargatni.
Így nem hiszem, hogy rövid távon eltűnik az FPU a CPU-kból. (Az esetleg lehet, hogy a megszokott FPU helyére 1-2 GCN CU kerül majd valamikor az AMD-nél, az FP/SIMD végrehajtás egységesítése érdekében. [Feltéve, hogy megoldható az SSE/AVX->GCN utasításfordítás.])
-
dezz
nagyúr
-

lee56
őstag
válasz
leviske
#13182
üzenetére
Akár azokat is takarhatja, kéne több infó.
"Röviden, ha ez igaz, akkor a Carrizo után jöhet/jön a 8 szálas APU." - Sőt akár 16 szálas is, az is már 2 egész nextgen modulból kijönne
 A gond csak az, hogy hacsak nem zsugorítanak jelentősen a modulok helyigényén, akkor hová dugják majd az IGP-t. Ez tényleg kicsit ellentmondásnak tűnik, azzal szemben amerre az APU-kkal haladnak jelenleg. Az még mondjuk talán lehetésges magyarázat, hogy ez egy szerver processzornak (CPU/APU) lesz az alapja majd.
A gond csak az, hogy hacsak nem zsugorítanak jelentősen a modulok helyigényén, akkor hová dugják majd az IGP-t. Ez tényleg kicsit ellentmondásnak tűnik, azzal szemben amerre az APU-kkal haladnak jelenleg. Az még mondjuk talán lehetésges magyarázat, hogy ez egy szerver processzornak (CPU/APU) lesz az alapja majd."De FPU-ból a Steamrollerben is 1 lesz modulonként, nem?" - Elvileg igen, csak optimalizáltak rajta itt-ott.
-
Oliverda
titán
válasz
leviske
#13108
üzenetére
Mikor és mihez?
Fiery: Szerintem FM2-re biztosan nem lett volna meg 3 csatorna. A lapka pedig az újabb szerver platformmal együtt törlésre került.
lee56: Néha kicsit utánanézhetnél néhány adatnak mielőtt tényként leírsz (
hülyeségeket) dolgokat. Az FX-6300 nagyjából 18%-kal van az A10-6800K előtt. Akkor mégis miért kéne 50% plusz magonként, hogy a Kaveri hozza a CPU-teljesítményét?















 de mi értelme lenne korlátozni a szoftvert Kaverin?
de mi értelme lenne korlátozni a szoftvert Kaverin?




 , így a korában, az egyik hozzászólásomban feltett kérdésre nem tudom a választ. Mi lenne az optimális aránya a CPU/IGP-nek, illetve az FPU/CU-nak, az ezt kihasználni tudó programok java részében? /Bár valószínűleg, a tudományom tükrében ehhez a kérdéshez, kevés vagyok
, így a korában, az egyik hozzászólásomban feltett kérdésre nem tudom a választ. Mi lenne az optimális aránya a CPU/IGP-nek, illetve az FPU/CU-nak, az ezt kihasználni tudó programok java részében? /Bár valószínűleg, a tudományom tükrében ehhez a kérdéshez, kevés vagyok 





 A gond csak az, hogy hacsak nem zsugorítanak jelentősen a modulok helyigényén, akkor hová dugják majd az IGP-t.
A gond csak az, hogy hacsak nem zsugorítanak jelentősen a modulok helyigényén, akkor hová dugják majd az IGP-t. 

Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.


- Telefon felvásárlás!! Samsung Galaxy A70/Samsung Galaxy A71/Samsung Galaxy A72
- ÁRGARANCIA!Épített KomPhone Ryzen 5 5600X 16/32/64GB RAM RTX 4060 8GB GAMER PC termékbeszámítással
- Kingmax 2x2GB DDR3 1333 RAM eladó
- LG 27GR93U-B - 27" IPS - UHD 4K - 144Hz 1ms - NVIDIA G-Sync - FreeSync Premium - HDR 400
- LG 48GQ900-B - 48" OLED - 4K 3840x2160 - 138Hz & 0.1ms - G-Sync - FreeSync - HDMI 2.1
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest