
- Megérkezett a Samsung Galaxy A37 és Galaxy A57
- Visszatérhet a csepp notch és a 90 Hz
- Samsung Galaxy S23 Ultra - non plus ultra
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- MWC 2026: Óriásakkut tuszkoltak egy szupervékony hajlíthatóba
- Vivo X300 Pro – messzebbre lát, mint ameddig bírja
- Apple iPhone 13 Pro Max - őnagysága
- Poco F8 Pro – titkos favorit lehet belőle
- Telekom mobilszolgáltatások
- Xiaomi 17 Ultra - jó az optikája
Új hozzászólás Aktív témák
-

Headless
őstag
Az eleje csak ellenőrzi, hogy létezik-e a mappa már, vagy fájl azon a néven
De igazából csak egy hibaüzenetet hagysz ki vele, amit az mkdir adna. Sok értelmét nem látom, de igen az is opció.
Amit én nem írtam, a maxdepth kapcsoló az annyit csinál, hogy maximum 1 mélységben keres fájlokat. És ebben az esetben értelmesnek láttam.
tarral kapcsolatban, most nem válaszolnék nem nagyon használok command line tar-t. De a find -exec tar így biztos nem lesz jó

-
Headless
őstag
Findnak van egy kapcsolója méghozzá a -type f így csak fájlokat fogja keresni valamint átmásolni meg akkor az exec kapcsolóval röviden
dir=/home/mentespreviousdaydir=$dir/$(date --date="yesterday")mkdir -p "$previousdaydir"find "$dir" -maxdepth 1 -mtime -1 -type f -exec mv \"{}\" \"$previousdaydir/\" \;Nem teszteltem de nagyjából ennyi, elnézést ha elírtam valamit.
-
Headless
őstag
válasz
 Fecogame
#2675
üzenetére
Fecogame
#2675
üzenetére
ha nagyon érdekel a teljesítmény shellt miért nem felejted el? pl megcsinálhatod az egészet awk-val. Még lehet egy python is gyorsabb. vagy ha tényleg számít minden us akkor c++.
annó csináltam egy tesztet:
1-1000-ig vizsgáltam a számokat, hogy prím-e és a tisztán awk megoldás töredéke volt, mint a sima shell megoldásnak. -
Headless
őstag
Szia
ehhez hasonló megoldás lehet
dir_list=$(find . -mindepth 1 -maxdepth 1 -type d -name "*" -print)dir_count=$(echo "$dir_list" |wc -l)echo "$dir_list" |while ((i++)); read pathdo.....doneÉn csak másoltam a te funkcióidat azt nem vizsgáltam, hogy megfelelő-e, vagy, hogy van-e egyszerűbb, mellesleg szerintem van kicsit fura a while ciklusod, nem is tudom hogy ez szintaktikailag helyes-e.
-
Headless
őstag
válasz
 Headless
#2657
üzenetére
Headless
#2657
üzenetére
megoldottam, mivel a fájlokban van egy másik separator, azt feltudtam hasnálni, nyilván a zárt forráskódű fejlesztők is azt használják szeparátornak...
Röviden: grep kikeresem a byteoffseteket a separatorokhoz, majd végig megyek rajtuk while ciklusban, kiszámolom a megfelelő kezdő/végoffset értékeket és azt dd-vel szépen átmásálom. A separatort átírom, hogy ne legyen kereshető, nehogy megtalálja a zárt forráskódú szoftver fejlesztő, vagy bárki más aki rákeresneAz elején van 4 byte felesleg, valamint a separator 8 byte azt hozzáadom az előző byteoffsethez
previousByteOffset=4imageCount=0grep -oba ggggggg "$imageFile" |while IFS=: read byteOffset rest;dodd if="$imageFile" of="$imageFile-$imageCount.jpg" bs=$(($byteOffset-$previousByteOffset)) count=1 skip=$previousByteOffset iflag=skip_bytespreviousByteOffset=$(($byteOffset+8))imageCount=$(($imageCount+1))done -
Headless
őstag
sziasztok!
egy megoldást keresek egy bináris fájl szétválasztására egy bizonyos hex karakter sorozat elválasztásával több részre osztani, konkrétan egy cubemap kép sorozat ami jxr (képeket, posx,posy,posz,negx,negy,negz) fájlokat tartalmaz. ezeket szeretném szétválasztani. az elválasztó lehetne a wmphoto magic numbere \x4949BC. minden wm photo kép ezzel kezdődik.
mivel bináris fájl sed meg sorokat vizsgál az nem feltétlen megfelelő, egyáltalán van-e értelme bashal szenvedni, vagy ez már inkább egyszerűbb/gyorsabb egy rendes (nem script) nyelvel?
-
Headless
őstag
szia hiba kezelést neked kell beraknod.
alapvetően ha szintaktikai hiba nincs a scriptben és semmi hiba kezelés sincs általad, akkor minden lefut.
cron logolást tudsz beállítani, de ez specifikusabb, pl systemd esetében szerintem alapból lesz, de tényleg itt attól függ milyen op rendszer/indítást használ az eszköz.
-
Headless
őstag
válasz
Fecogame
#2581
üzenetére
tömbök meg azért nem a legjobbak shellben mert nem fog minden shellben működni az shell specifikus, de ha esetleg egy beépített eszközön akarod futtatni ahol javarészt busybox és ash van ott nem fog lefutni vagy akár ha bsd alatt. ott is lesznek különbséges persze nem lenne egy elfogadott tömbbrendszer de a legközelebb hozzá azzal vagyunk mint amit bambano írt.
-
Headless
őstag
válasz
 bambano
#2577
üzenetére
bambano
#2577
üzenetére
Közben sikerült tovább lépnem.
a fő probléma a \n\r sorvégződés volt windowson kezdtem a fájlt....
azután már részletesebb hibaüzenetet kaptam.volt pár különbözőség, date -d helyett -r , find-ban a -printf hiányzott meghekkeltem -exec -el
de a feltétel sem volt jó a -gt
viszont a feltétel továbbra sem stimmel[: 243857: unexpected operator
olyan mintha hiányozna az egyik fele a feltételnek és emiatt hibát dob.de az meg egy constans
UI: megvan...
sed nem támogatja a \t \n stb jelöléseket ami azért elég szomorúegyenlőre fut rendbe.
-
Headless
őstag
sziasztok, átkéne vinnem egy scriptet bash alól zsh (freenas) alá, és errort kapok valamiért
van egy jó kis anyag, hozzá, mik az általános különbségek
pl ami valószínű gond lehet, pl ez
ls * |while read x;do...donevagy vannak feltételem
if [ number1 -gt number2 ];then...else...fivan sima bash integer összeadásom:
$((asd*asd+asd))output redirection
röviden nagyjából ezek vannak, és egy ilyen szintax erroral száll el, tehát valamelyik if -ben lehet a hiba.
Syntax error: end of file unexpected (expecting "then")
vagy a fájl kódolása lenne a hiba? utf8. -
Headless
őstag
válasz
 RedHarlow
#2550
üzenetére
RedHarlow
#2550
üzenetére
Amit bambano írt az ezzel a verzióval is kivitelezhető, ott egyedül az a gond, ha véletlenül a </User> szerepel egy CDATA-ban akkor onnantól kezdve hibás adatsorod lesz.
röviden törölsz minden újsort, pl: tr -d "\r\n" , <\User> delimiterrel szétdarabol új sorokra utána greppel már úgy szűrheted ahogy akarod.
-
Headless
őstag
nem egy szeretett megoldás ez , de ha nincs RSS forrás, akkor nincs más.
curl/wgettel letöltöd a html fájlt. utána már két megoldás használ valami xml parser-t és azzal szűröd ki a lényeget, vagy ha nem akarsz/ nincs lehetőséged ilyet telepíteni, akkor pedig marad a grep, tr,sed, stb megoldások, pipeolgatsz jobbra/balra, mig megnem kapod a szeretett formátumot...Első körben azért megnézném, nincs-e valami RSS forrás... meg egyébként telefonra elég sok alkalmazás létezik ami hasonlóakat tud, pl árfolyam értékek... sőt még értesít is ha kell...
-
Headless
őstag
Sziasztok!
Egy curl/wget kérdésem lenne.
Bővítés miatt curl-al is kompatibilissé szeretném tenni a scriptemet.
A lényeg egy login form amivel post requestel küldök információt majd egyátirányítás után megkapom a sütit az oldaltól egy fájlba.
A gond ott jön hogy curl esetében csak az átirányítás előtti cookie-t menti el, míg wget-nél rendesen az átirányítás után beállított cookie-t is.
Ez azt eredményezi, hogy első betöltéskor amikor elküldöm a requestet átirányít beléptet, viszont a cookie-t nem menti el (a headerben látom a set-cookie paramétereket amik hiányoznak), vagyis a következő oldalbetöltés már nyilván nem megy.
WGET-el nincs problémám eddig is tökéletesen működött, most is megy.
a próbált parancs:
curl -L -k -X POST -d "user=data1&pwd=data2" -b /tmp/cookie.txt "$URL"WGET megfelelő
wget-ssl -q --no-check-certificate -O /dev/null --keep-session-cookies --save-cookies /tmp/cookie.txt --post-data="$post_data" "$URL"Remélem nem írtam el semmit
de ebből jön ki.
case "$binary" in
"curl")
q="-s"
cert="-kL"
post="-X POST -d "
h="-H "
ConE=""
std=""
cload="-c "
csave="-b "
out="-o "
;;
"wget-ssl")
q="-q"
cert="--no-check-certificate"
post="--post-data="
h="--header="
ConE="--content-on-error"
std="-O -"
cload="--load-cookies "
csave="--keep-session-cookies --save-cookies "
out="-O "
;;
esac
$binary $cert $out/dev/null $q $csave$cookie $post"$login_data" "$login_url" -
Headless
őstag
válasz
 anorche1
#2299
üzenetére
anorche1
#2299
üzenetére
kiiratod egy text fájlba és megnyitod valamivel? Amúgy lehet tekerni asszem shift+PageUP/down párossal.
kiiratni a kimentet fájlba pedig.
dpkg-query -W -f '${binary:Package}: ${Depends}\n' >"/Path/to/File"utána akár consolos szövegszerkesztővel is meg tudod nézni pli nano/vi, stb, de akár Windowsról is meg tudod nyitni...
-
Headless
őstag
válasz
 bucihost
#2258
üzenetére
bucihost
#2258
üzenetére
Szia, én csinálnék egy scriptet ehhez hasonló tartalommal, majd azt futtatnám indításkor, vagy init.d-vel nem részletezném viszonylag bonyolult. /etc/rc.local fájlból, vagy cronból @reboot eventel.
while [ 1 = 1 ];do
#111-999 random szám
rand=$(cat /dev/urandom 2>/dev/null |tr -dc '1-9' 2>/dev/null | head -c 3)
#kb 720-1800 (12-30 perc)
sleep_time=$(($rand*12/10+600))
#1-9 random szám a proxy kiválasztásához ha nagyobb a lista akkor számolj magadnak más tartományt.
rand_proxy=$(($rand/100))
#get the proxy with curl
proxy_list=$(curl ... )
current_proxy=$(echo "$proxy_list" |head -n $rand_proxy |tail -n1)
#csatlakozz a proxyhoz.
#várjunk a következő futásra.
sleep $sleep_time
#ez kilép a végtelen ciklusból, csak tesztelésre.
#break
done -
Headless
őstag
Szia Én valami ilyesmit gondolnék
dir="/teszt"
archive_dir="/archive"
[ -d "$archive_dir" ]||mkdir -p "$archive_dir"
ls "$dir" |sed "s/\(.*\)_[0-9]\+$/\1/" |sort|uniq |while read subdir;do
find "$dir" -maxdepth 1 -type d -iname "${subdir}_*" |sort -n|head -n-2 |while read path;do
echo "$path"
#mozgassuk át az archív mappánkba, vagy töröljük a fájlokat
mv "$path" "$archive_dir"
done
doneLehet van ennél jobb megoldás mint nested while ciklussal.
-
Headless
őstag
válasz
 Mr Dini
#2245
üzenetére
Mr Dini
#2245
üzenetére
Ez az a pont amikor vagy váltasz valami erre használatos nyelvre (lua,php,stb). Vagy a form enctype-ját átállítod multipartra. Viszont így a változó beállítások sokszor nehezebbek lesznek, és pl az sem fog működni, amit írtam pü-ben tegnap.
<form action=… method=post enctype='multipart/form-data'>Így rendesen szeparált listát kapsz a változókról, nem csak egy urlenkódolt listát, vagyis nem & lesz a szeparátorod.
-
Headless
őstag
Szia nem egészen értem mit akarsz.
find az ígyis úgyis recursive ha csak nem beállítod a -maxdepth -mindepth kapcsolókat. Másrészt miért a xarg? ha ott van a beépített delete funkció?
find "$LogDir" -name "*.bak*" -type f -deleteahh most leeesett tehet a *.bak* mappán balüli *.bak* fájlokat szeretnéd törölni?
ehhez viszont nagy kérdés hogy csak a *.bak/*.bak-et akarod törölni vagy *.bak/akarmi/*.bak-et is
amúgy én a -path szűrőt használnám... először delete nélkül futtasd, nehogy törölj valamit ami kell..
find "$LogDir" -path "*.bak/*.bak" -type f -deleteez az utóbbi verzió ami a *.bak/akármi/*.bak-ot is törli.
-
Headless
őstag
Hát vagy find-al keresed meg és futtatod amit kell
find $x -type f -exec ....vagy
a meglévő for ciklusba teszel egy ellenörzést hogy fájl-e...
valahogy ígyif [ -f "$file" ];then
echo "file"
fiha van printf parancsod, akkor megfelelő számú szóközt tudsz csinálni valahogy így. azt meg kicserélheted #-re de szerintem nem éri meg, lehet van jobb megoldás is.
printf "%33s" |sed "/ /#/g" -
Headless
őstag
-
Headless
őstag
Szimplán $0 helyett $1,$2,$3 stb-ket használsz, persze a field separator nem mindegy, hogy ; szóköz vagy mi. Pl
Fájl:
11;12;13;14
21;22;23;24awk -F";" '{print $3}' path
13
23Persze a field separatort magában az awk-ban is tudod változtatni az FS változóként ahogy a kimeneti elválasztót is az OFS-t.
-
#2146
Headless
őstag
beloadjoker
#2143
Headless
őstag
válasz
 beloadjoker
#2143
üzenetére
beloadjoker
#2143
üzenetére
Hát ez egy összetetteb ha így mindenre gondolni kell...
Első körben vegyük azokat amik a sor közepén helyezkednek el, 4 szám egymás után, előtte utána bármi ami nem szám, az már évszám
sed "s/\([^0-9]\)\(19\)\([0-9]\{2\}[^0-9]\)/\120\3/g" /evszam.txt
Előtte nincs semmi (sorkezdés) utána van bármi ami nem szám.
sed "s/^\(19\)\([0-9]\{2\}[^0-9]\)/20\2/" /evszam.txt
Előtte bármi ami nem szám, utána semmi (sorvég).
sed "s/\([^0-9]\)\(19\)\([0-9]\{2\}\)$/\120\3/" /evszam.txt
előtte utána semmi (csak az évszám van).
sed "s/^\(19\)\([0-9]\{2\}\)$/20\2/" /evszam.txt
Persze ezt besűrítheted egy nagy átláthatatlan parancsba.
sed "s/^\(19\)\([0-9]\{2\}\)$/20\2/;s/\([^0-9]\)\(19\)\([0-9]\{2\}\)$/\120\3/;s/^\(19\)\([0-9]\{2\}[^0-9]\)/20\2/;s/\([^0-9]\)\(19\)\([0-9]\{2\}[^0-9]\)/\120\3/g" /evszam.txt
Minden eshetőségre könnyebbet nem találtam. Persze a szövegelválasztókat cserélheted bármi másra. [^0-9] hogy ne ugorjon bármire, ami nem szám. pl nem szám és nem betű. [^0-9a-zA-Z] vagy csak szóköz és vessző [ ,]
Az &&-el óvatosan, ha mindenképp le kell futni, mert ha így adod ki, akkor csak akkor fog lefutni, ha az első parancs lefutott és a return értéke 0.
vagyis ha mondjuk grep nem talál semmit akkor nem fog végrehajtódni a && után jövő parancs. Ha már 1 sorba kell tömöríteni használjuk a ";"-et parancsok elválasztásához.
-
#2141
Headless
őstag
beloadjoker
#2139
Headless
őstag
válasz
beloadjoker
#2139
üzenetére
Ez attól függ mi a környezet, az évszámok utáni részt is rakd be a \2-be. szóköz, end line, field separator, stb az 19 elé meg szintén berakhatod ezeket.
Viszont én a te megoldásodon annyit javítanék, hogy a 19 után nem engedném hogy 0-9 legyen mert akkor az 1993-at is át fogja írni, ami valószínű nem elírás... Ezért én maximum [0-1][0-9]-et engednék meg. Még ígyis 2019-ig fogja változtatni
Szerk: azért elég furcsa egy adatbázis ez... Semmi rendszeresség...
-
#2137
Headless
őstag
beloadjoker
#2136
Headless
őstag
válasz
beloadjoker
#2136
üzenetére
jah most nézem akkora ellentmondás van a field numberes szűrésemben...

nagyobb 2-nél és kisebb 3-nál...
mindegy a lényeget gondolom értetted. -
#2135
Headless
őstag
beloadjoker
#2134
Headless
őstag
válasz
beloadjoker
#2134
üzenetére
awk '/^[A-Z][a-z]+ [A-Z][a-z]+/{print "Sorszám: "NR" szavak száma: "NF" "$2" "$1}'
Persze az még mindig kérdéses mi van a 3 nevűekkel. ott a 3.-kat elveszted vagy simán kiprinteled, a 3.-kat is.
Idézőjel azért kell, hogy a print tudja hogy nem változót akarsz használni, hanem egyszerű stringet.
ahogy látszik a mintában vannak beépített változók awk-ban, azokat használhatod
googleben hamar megtalálhatod őket.[link]Vagy esetleg még a filed numberre is szűrhetsz
awk 'NF>2&&NF<3&&/^[A-Z]/{print ....}'
mondjuk persze mindig lehet finomítani.
-
-
Headless
őstag
válasz
 Jester01
#2090
üzenetére
Jester01
#2090
üzenetére
Egy ilyesmi esetleg?
#csinálj amit akarsz
while [ ! "$size" ] || [ $size -lt 40894464 -o $size -gt 45088768 ];do
#Letöltés
size=$(stat -c \%s foo)
[ $size -lt 40894464 -o $size -gt 45088768 ] && sleep 10m
done
#csinálj amit akarszÍgy az első esetben amíg nincs definiálva a size értéke, akkor belép a ciklusba utána pedig mindig a második feltétel lesz az érvényes, mert az első hamis lesz.
-
#2070
Headless
őstag
RoyalFlush
#2069
Headless
őstag
válasz
 RoyalFlush
#2069
üzenetére
RoyalFlush
#2069
üzenetére
Azért te is utána járhatsz a dolgoknak
stackoverflowon sok minden van , csak hasonló típusú dolgot kell keresned.Ám Férfi 10. hónap, szűrhetsz évre és napra is ebből mennie kell már.
awk -F, '$4~/[0-9]{1,4}\.10\.[0-9]{1,2}/&&$3!~/h.lgy/{split(ugyfel[$5],a,",");if($6>a[6])ugyfel[$5]=$0}END{for(i in ugyfel)print ugyfel[i]}' /test/fizetes
-
#2068
Headless
őstag
RoyalFlush
#2067
Headless
őstag
válasz
RoyalFlush
#2067
üzenetére
Szia!
awk -F, '{split(ugyfel[$5],a,",");if($6>a[6])ugyfel[$5]=$0}END{for(i in ugyfel)print ugyfel[i]}' /test/fizetesMost hogy az urak, azt a legegyszerűbben egy pipe grep-el tenném a végére hátha kell a nőké is valamikor...
de végülis ez is egy megoldás. Így még gyorsabb is mert kihagyja a nőket.
Férfiak:
awk -F, '$3!~/h.lgy/{split(ugyfel[$5],a,",");if($6>a[6])ugyfel[$5]=$0}END{for(i in ugyfel)print ugyfel[i]}' /test/fizetesNők:
awk -F, '$3~/h.lgy/{split(ugyfel[$5],a,",");if($6>a[6])ugyfel[$5]=$0}END{for(i in ugyfel)print ugyfel[i]}' /test/fizetes -
-
Headless
őstag
Sziasztok!
Egy újabb nap, újabb script, újabb gond amit nem tudok megoldani.
URL decodolni szeretnék változóKAT. ehhez az uhttpd beépített dekódolóját használom azzal nincs baj működik jó is,
A script bemenetén a változóneveket kapja meg.#!/bin/sh
for i in "$@"
do
eval ev=\$"$i"
dv=\'`uhttpd -d "$ev" | tr -d '\r'`\'
eval "$i=$dv"
echo "$i=$dv" >>/tmp/decoder
doneEz egészen addig működik is, amíg nincsen egy idézőjel. Azután nem jól definiálja a változót, hogy lehetne megoldani, szépen és kevés karakterből. Jelenleg manuálisan van kiírva minden dekódolni kívánt változó de jobb lenne így ciklussal.
-
Headless
őstag
válasz
Jester01
#1997
üzenetére
Szia valóban nem írtam, de nem #!/bin/bash hanem #!/bin/sh
Nah meg pont hogy a ciklusokat akartam mellőzni mert azt lassan dolgozza fel. Habár nem az a leglasabb az egészben Hanem a wifi scannelés. Szóval szerintem maradok a saját verziómnál, abban csak 1 for ciklus van, meg az már mész és működik is. Igazából ezt kell létrehoznom abból az adatsorból, amit megadtam.
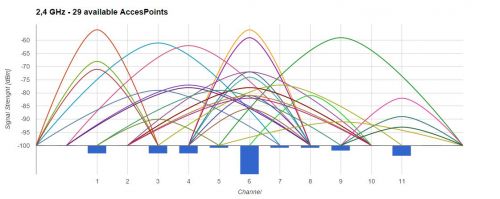
Csak hogy teljes legyen a kép:
Ez a kiindulási alap:
1. oszlop jelerősség [dBm] 2. oszlop SSID, 3. oszlop bal oldali nulla jelerősséghez tartozó channel 4. maximum jelerősséghez tartozó channel, 5. oszlop jobb oldali minimum jelerősség.
-58;3770d6;-1;1;3
-59;DONI;-1;1;3
-61;DIGI-385317;4;6;8
-62;TP-LINK-Pinter;0;4;8
-62;Ne_probalkozz;5;9;13
-62;Belkin_N_Wireless_EE0F25;-1;3;7
-67;Kimi;0;4;8
-68;DIRECT-zF-BRAVIA;-1;1;3
-71;37f9bc;-1;1;3
-72;BUBU;2;4;6
-73;alfonz;4;6;8
-76;Apae;2;6;10
-77;UncleOwen_AuntBeru;3;7;11
-77;TP-LINK_Dikan;2;6;10
-78;TP-LINK_BB;-1;3;7
-78;Sonkaharcos;-1;3;7
-78;SWL;0;2;4
-79;Tech_D0059092;-1;1;3
-79;Tauri;4;6;8
-79;OtthoniWifi;2;6;10
-80;TP-LINK_6E20EC;2;6;10
-80;Balaton;9;11;13
-80;12345;4;6;8
-81;Wasowski;1;5;9
-82;Huszti;9;11;13
-84;Csordi;0;4;8
-86;mohamed;4;6;8
-87;deed35;-1;1;3
-87;D-N;6;8;10
-89;herko;7;9;11
-89;ASUS-EF8C;-1;3;7
-93;Bundi8;4;6;8És ennek a táblázatnak kell lennie belőle. 1. oszlop x tengely, 2. oszlop a channelenkénti telítettség(oszlop diagram alul) a többi sor pedig értelem szerűen ábrázolja, hogy milyen csatornán milyen jelerősség van.
['Channel','APs','3770d6','DONI','DIGI-385317','TP-LINK-Pinter','Ne_probalkozz','Belkin_N_Wireless_EE0F25','Kimi','DIRECT-zF-BRAVIA','37f9bc','BUBU','alfonz','Apae','UncleOwen_AuntBeru','TP-LINK_Dikan','TP-LINK_BB','Sonkaharcos','SWL','Tech_D0059092','Tauri','OtthoniWifi','TP-LINK_6E20EC','Balaton','12345','Wasowski','Huszti','Csordi','mohamed','deed35','D-N','herko','ASUS-EF8C','Bundi8'],
[-1,-100,-100,-100,null,null,null,-100,null,-100,-100,null,null,null,null,null,-100,-100,null,-100,null,null,null,null,null,null,null,null,null,-100,null,null,-100,null],
[0,-100,null,null,null,-100,null,null,-100,null,null,null,null,null,null,null,null,null,-100,null,null,null,null,null,null,null,null,-100,null,null,null,null,null,null],
[1,-106,-58,-59,null,null,null,null,null,-68,-71,null,null,null,null,null,null,null,null,-79,null,null,null,null,null,-100,null,null,null,-87,null,null,null,null],
[2,-101,null,null,null,null,null,null,null,null,null,-100,null,-100,null,-100,null,null,-78,null,null,-100,-100,null,null,null,null,null,null,null,null,null,null,null],
[3,-104,-100,-100,null,null,null,-62,null,-100,-100,null,null,null,-100,null,-78,-78,null,-100,null,null,null,null,null,null,null,null,null,-100,null,null,-89,null],
[4,-104,null,null,-100,-62,null,null,-67,null,null,-72,-100,null,null,null,null,null,-100,null,-100,null,null,null,-100,null,null,-84,-100,null,null,null,null,-100],
[5,-101,null,null,null,null,-100,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-81,null,null,null,null,null,null,null,null],
[6,-110,null,null,-61,null,null,null,null,null,null,-100,-73,-76,null,-77,null,null,null,null,-79,-79,-80,null,-80,null,null,null,-86,null,-100,null,null,-93],
[7,-101,null,null,null,null,null,-100,null,null,null,null,null,null,-77,null,-100,-100,null,null,null,null,null,null,null,null,null,null,null,null,null,-100,-100,null],
[8,-101,null,null,-100,-100,null,null,-100,null,null,null,-100,null,null,null,null,null,null,null,-100,null,null,null,-100,null,null,-100,-100,null,-87,null,null,-100],
[9,-102,null,null,null,null,-62,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-100,null,-100,-100,null,null,null,null,-89,null,null],
[10,-100,null,null,null,null,null,null,null,null,null,null,null,-100,null,-100,null,null,null,null,null,-100,-100,null,null,null,null,null,null,null,-100,null,null,null],
[11,-102,null,null,null,null,null,null,null,null,null,null,null,null,-100,null,null,null,null,null,null,null,null,-80,null,null,-82,null,null,null,null,-100,null,null],
[12,-100,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null],
[13,-100,null,null,null,null,-100,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,-100,null,null,-100,null,null,null,null,null,null,null]Én ehhez két for ciklust használtam, ha van egyszerűbb, akkor szivesen várom az ötleteket még, de szerintem ez nem igazán oldható meg for/while ciklus nélkül.
És ezt már tudom ábrázolni google chart-al. ami így néz ki.
-
Headless
őstag
válasz
bambano
#1995
üzenetére
Hát azért ez még nagyon messze van a kívánt output-tól, és nembiztos, hogy előrébb lennék vele így első ránézésre. De azért köszi ma is tanultam valamit.
Esetleg ha olyat tudna a uniq vagy valami gyors utómunkálat, hogy egy sorozaton mennyen végig, és ha nincs olyan elem, akkor írjon nullát. -
Headless
őstag
Sziasztok van egy újabb kérdésem van rá egy megoldásom de hátha van egyszerűbb, kevésbé erőforrás igényesebb megoldás.(Router nem egy erős vas)
Szóval van egy ilyen adatsorom
-54;Ne_probalkozz;5;9;13
-62;Belkin_N_Wireless_EE0F25;-1;3;7
-64;3770d6;-1;1;3
-67;DONI;-1;1;3
-68;TP-LINK-Pinter;0;4;8
-69;DIGI-385317;4;6;8
-71;alfonz;4;6;8
-72;37f9bc;-1;1;3
-73;DIGI-685606;4;6;8
-74;BUBU;2;4;6
-74;12345;4;6;8
-75;Csordi;0;4;8
-75;Bundi8;4;6;8
-79;TP-LINK_BB;-1;3;7
-80;BORG_APU;-1;1;3
-81;Tauri;4;6;8
-81;Balaton;9;11;13
-83;Huszti;9;11;13
-86;746e56;9;11;134. elemét kell vizsgálnunk elválasztó ; össze kéne számolni hány darab 1-es 2-es 3-as stb van ebben az oszlopban.Mármint egyesével, tehát tudjam, hogy miből hány db van. Én csak for ciklussal tudtam megoldani.(és -100 ból ki kell vonna az értéket)
data="$channel"
for j in $channel
do
ch_center=`echo "$aps" | cut -d';' -f4 | grep "^$j\$" | wc -l`
ch_center=$((-100-$ch_center))
data=`echo "$data" | sed "s/^$j\$/&,$ch_center/"`
doneés a célnak ilyennek kell lennie
[-1,-100
[0,-100
[1,-107
[2,-100
[3,-104
[4,-105
[5,-101
[6,-111
[7,-102
[8,-103
[9,-101
[10,-100
[11,-105
[12,-100
[13,-100 -
Headless
őstag
válasz
bambano
#1987
üzenetére
Most hogy jobban beleástam magam, a head tail-el próbálkoztam. de nem megfelelőt ad vissza, erre gondoltam.(a vizsgált könytárban csak az a file van
)data=`cat ./*.mp4 |head -c 65536`
data=`echo "$data$(cat ./*.mp4 |tail -c65536)"`
echo "$data" | md5sum
nekem ezt adja ki a dexteres filra.
f754106989f7ce718e03a3f1feaadb11
De az echo nem megfelelő md5sumot köp ki. a dexter.mp4-et próbáltam.Rosszul értelmeztem a leírást? meg is kell fordítani a végét nem elég csak az utolsó 64 kb-ot kiolvasni?
openWRT-re kéne ahol kissé korlátozottabbak az elérhető parancsok így maradnék a head tail megoldásnál -
Headless
őstag
Sziasztok
Nem tudom kivitelezhető-e de egy phyton scriptet átkéne írni shell-ben futtathatóvá ez egy nyilvános API. felirat letöltéshez.[link]A legnagyobb gondom a lényeg, vagyis a data változó definiálása, amit ha jól értek. tehát az első 64*1024 és utolsó 64*1024 byte. nah meg hogy utána mi történik ezzel a változóval az sem teljesen tiszta. Ha valaki tudna segíteni megköszönném
-
Headless
őstag
Sziasztok egy újabb problémám lenne.
Globális változót szeretnék létrehozni, de nem megy.
Ha simán parancssorból meghívom ezt
export wd24=$(iw dev | tr '\n' ';' | sed "s/Interface /\n/g" | grep -ve 'sta\|-' | egrep "2[0-9]{3}" | sed "s/;.*//")Rendesen beállítja a globális változót, de ha ezt egy scriptben hívom meg(lásd lent) nem jön létre a változó.
#!/bin/sh
export wd24=$(iw dev | tr '\n' ';' | sed "s/Interface /\n/g" | grep -ve 'sta\|-' | egrep "2[0-9]{3}" | sed "s/;.*//")Van futtatási joga a scriptnek. -n debugoló opció hibát nem ír. (magyarul a script lefut.)
-x es debuggoló opció ezt írja
+ export wd24=wlan0mi lehet a hiba?
-
Headless
őstag
Sziasztok van egy olyan problémám, hogy
van egy fájlom amiiből beolvasok adatokat de némelyik "-" (kötőjel)-el kezdődik. És szeretnék keresni közöttük. És amikor olyanra keresek amiben van kötőjel,akkor azt hiszi hogy funkciót hívok meg. A nehezítés ott jön a képbe hogy amire keresnék az is változó. tehát az nem működik, hogy rakok egy \ jelet a kötőjel elé tehát nagyjából egy nézne ki.Azt hogy hogyan definiálom a var-t az már lényegtelen szerintem a probléma szempontjából, lényeg hogy van olyan hogy -jellel kezdődik.
var="-valami"
cat file | grep "$var"nekem az jutott eszembe, hogy megspékelhetném, hogy törölje ki a szó eleji - jelt, de hátha van egyszerűbb módszer.pl
cat file | grep "$(echo $var | sed 's/^-//)"





















 kipróbálom.
kipróbálom.Új hozzászólás Aktív témák
- Multimédiás / PC-s hangfalszettek (2.0, 2.1, 5.1)
- Megérkezett a Samsung Galaxy A37 és Galaxy A57
- Visszatérhet a csepp notch és a 90 Hz
- Kerékpárosok, bringások ide!
- BestBuy topik
- Kormányok / autós szimulátorok topikja
- Renault, Dacia topik
- Luck Dragon: Asszociációs játék. :)
- sziku69: Fűzzük össze a szavakat :)
- Autós kamerák
- További aktív témák...

- Apple iPhone 12 Pro Max 128GB Graphite használt, szép állapot 97% akku 6 hónap garancia
- ÁRGARANCIA!Épített KomPhone i7 14700KF 32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- A Legújabb! Dobozos Új DELL XPS 13 9340/ULTRA 7-155H/32 GB Ram/1TB SSD/AI BOOST+INTEL ARC
- Licencek + laptopok + dokkolók
- AKCIÓ! Gigabyte B650M R7 8700F 64GB DDR5 1TB SSD RX 7800 XT 16GB LianLi VectorV100R RGB TG 750W
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest