Hirdetés
- iPhone topik
- Milyen okostelefont vegyek?
- Google Pixel topik
- Samsung Galaxy Z Fold7 - ezt vártuk, de…
- Karácsonyi telefonajánló 2025
- Apple Watch
- One mobilszolgáltatások
- Papírvékony a jövő a Samsungnál: íme, a Galaxy TriFold!
- Nem semmi: két Nothing kapott egy nagy frissítést
- Szemtelenül olcsó lett a Nubia Fold
Új hozzászólás Aktív témák
-
#8841
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
5600X3D
$229
2023 július 7
Micro Center Only
[link] -
#8838
Petykemano
veterán
Petykemano
veterán
PHX2 (Little Phoenix): 137mm2
[link]Elvileg ez hybrid
-
#8835
Petykemano
veterán
Petykemano
veterán
Nő már az uborka...
Azon gondolkodtam el, hogy vajon.... mármint én azt érzékelem, hogy a Milanhoz képest a Genoa sokkal lassabban terjed.
Vajon ennek az lehet az oka, hogy volt valami hiba? Vagy ilyen szinten ment rá mindenki szerverkapacitások bővítése és/vagy energiahatékonnyá tétele helyett az AI-ra? Vagy a nagyobb szolgáltatók valójában a Bergamora vártak/várnak? -
#8833
Petykemano
veterán
Petykemano
veterán
Egyelőre csak érdekességképp osztom meg. Relevanciája abban lehet, hogy nemrégiben felröppent hír, hogy az AMD puhatolózott a Samsung irányába.
"Samsung develops embedded MRAM technology compatible with 14nm FinFET logic" [link]
"He reported that the development level is close to the mass production level by prototyping a 128Mbit large capacity MRAM macro, and showed that the developed eMRAM technology can be applied to even finer 8nm generation FinFET logic."
"The cell area of the prototype eMRAM macro is 0.0242 square μm, which is the smallest eMRAM so far."
"The write pulse width is 200 ns (temperature 160° C.), and the read pulse width is 15 ns (shortest 11 ns, temperature 160° C.)."
"Photo of silicon die of prototype 16Mbit eMRAM macro. The die dimensions have not been announced (assuming the memory density is 18.1Mbit/square mm, which is the same as the 128Mbit macro, the die area is 0.88 square mm)"
Vagyis valamilyen Samsung 14nm-es eljáráson 2.27MB/mm2.
Ez 8nm-en a sűrűség/egységnyi területre vetített kapacitás ennek akár másfélszerese is lehet majd [link]
(Persze azt nem tudjuk, hogy az eMRAM skálázódása is megáll-e valamilyen eljárásnál)TSMC N7-en gyártva a Navi21 esetén az SRAM cellákból álló infinity cache esetén 64MB 40mm2 [link]
Ez 1.6MB/mm2Ezen valamit javít a Zen processzorokhoz alkalmazott 3D V-cache, ami szintén TSMC N7-en 64MB ~36mm2, vagyis ~1.8MB/mm2 (ebbe persze benne van a TSV is, tehát valamivel jobb)
Az MRAM további előnyei azon kívül, hogy kisebb cellaméret szükséges hozzá elvileg az, hogy nem volatilis, nem szivárog, nem fogyaszt sokat, és azért elég gyors is.
Persze az MRAM (STT_MRAM) már készülődik a hatalomátvételre legalább vagy 5-10 éve. Most, hogy a 3D stacking realitássá vált és láthatólag új lendületet vett a számolóegységek cache-sel való kitömése, és 5nm-nél már valószínűleg tényleg elég kicsi lehet az SRAM cellák méretének skálázódása (vagyis nem lesz kisebb a cache kiterjedésének mérete) kiváncsi vagyok, hogy valaki hozzányúl-e.
-
#8832
Petykemano
veterán
Petykemano
veterán
Bergamo spec test
[link]
Meglep, hogy a SpecPower érték az Ampere termékhez képest is milyen jó. -
#8829
Petykemano
veterán
Petykemano
veterán
Az ott elvileg balra egy Bergamo lapka.
A kisebb csomagok azonosítását én meg sem kísérlem. -
#8828
Petykemano
veterán
S_x96x_S
#8826
Petykemano
veterán
válasz
 S_x96x_S
#8826
üzenetére
S_x96x_S
#8826
üzenetére
Én is olvastam az elemzés nyilvános részét.
Ezt idézném:
"All variants of MI300 start with the same base building block known as the AID, active interposer die. This is a chiplet called Elk Range and is ~370mm2 in size manufactured on TSMC’s N6 process technology. The chip houses 2 HBM memory controllers, 64MB of Memory Attached Last Level (MALL) Infinity Cache, 3 of the latest generation video decode engines, 36 lanes of xGMI/PCIe/CXL, as well as AMD’s network on chip (NOC). In a 4 tile configuration, that is 256MB of MALL Cache vs H100’s 50MB."Számomra meglepő volt, hogy egy ilyen meglehetősen nagynak mondható - 370mm2-es - lapkán a 2HBM vezérlő és az IO mellett csupán 64MB cache fér bele. Elképzelhető, hogy mindezen IO mellett ez a 64MB nem csupán ~35-40mm2, hanem annál több helyet foglal. Mindenesetre egy ekkora lapkában én szeletenként 256MB-ra számítottam.
Mindenesetre végre látjuk akció közben az active interposer-t, amit már régóta vártunk.
Ahhoz képest, hogy milyen kevés az AID-be rejtet cache és mégis milyen nagy a bázislapka, maguk a compute chipletek egészen törpék. A 370mm2-re csupán 210-230mm2-nyi compute lapka kerül.
Kiváncsi vagyok, hogy akár GPU-k terén, akár CPU-k terén ezt a technológiát bevetik-e következő generációk valamelyikében
Ez a CPU-k terén ugye azt jelentené, hogy az IOD bekerül alulra. Kicsit talán növelni kell a méretén, de jelenleg úgysem tartalmaz cache-t. Ha tartalmazna, akkor túl azon, hogy a 2pJ/bit adatátviteli energiahatékonyságon tudnának jelentősen javítani, hanem a chipletek közötti kommunikáció/adatmegosztás meg megoldódna.Ez a megközelítés egyedül a skálázhatóságot rontaná. jelenleg nyugodtan kihagyható egy-egy chiplet, viszont 3D stackelve a hiányzó chipleteket valamilyen strukturális szilíciummal kellene pótolni.
Természetesen én is azt gondolom, hogy anyagköltségben a Mi300 nagyon drága, viszont nem biztos, hogy a 3D stackelés önmagában annyira költséges már, ha beleférhet egy $200-os 5600X3D.
A szóbeszéd szerint azért mégis a konzumer piacon valószínűbb valamilyen infinity fan-out bridge szerű technológia használata. -
#8817
Petykemano
veterán
Petykemano
veterán
Nocsak, talán mégis lesz 5600X3D?
[link] -
#8816
Petykemano
veterán
Petykemano
veterán
Zen4 Threadripper listed [link]
-
#8811
Petykemano
veterán
S_x96x_S
#8810
Petykemano
veterán
válasz
S_x96x_S
#8810
üzenetére
lelkesítő, de sajnos szerintem valószínűbb, hogy a doboz jobb szélén levő [PROD] feliratnál van a tényleges megjelenés.
Jó lenne tudni, hogy pontosan mit jelképeznek a dobozok. Ha tippelnem kéne, akkor szerintem ez nem az aktív gyártás időszaka, nyilvánvalóan nem is fejlesztésé, hanem inkább valamilyen piacravezetési időszak.
Ne felejtsük el, hogy ez egy DC roadmap, az asztali Raphael nem szerepel rajta, csak sejthető, hogy amikortól tömegtermelésbe kerül a Genoa, akkortól van selejt a Raphael-hez.
Mindazonáltal én azt érzékelem, hogy a Genoa, Genoa-X és Bergamo terjedése is lényegesen lassabban megy végbe, mint a Milané.Viszont ha igazam van, akkor a Zen5 DC termékek 2024Q2-Q3-ban érkeznek. És ha ezek selejtje kerül desktopra, akkor az miért kerülne a boltokba hamarább? Viszont az sem gyakori, hogy 1-1.5 évvel korábban jelenne meg ES bench leak.
-
#8809
Petykemano
veterán
Petykemano
#8806
Petykemano
veterán
válasz
 Petykemano
#8806
üzenetére
Petykemano
#8806
üzenetére
Zen5 első bench leak ES engineering sample
Szokásom visszanézni, hogy mikor volt az előző esetben az első leak és ahhoz képest mennyi idő telt el a megjelenésig.
Úgy láttam, hogy a Zen4-ről 2022 májusban érkeztek az első kiszivárgó mérések.
Ehhez képest szeptember végén jelent meg. Az mindössze 4 hónap.Persze azt tudjuk, hogy a Zen4 szándékosan késleltetett design volt, tehát elképzelhető, hogy több felkészülési idő volt és így gyorsabban tudták intézni.
Mindenesetre ez akkor is előrevetíthet akár egy idén év végi Zen5 rajtot.
Persze elképzelhető, hogy tévedek és már május előtt lehetett látni Zen4 ES-t.
A 2024Q1 akkor is reális. -
#8806
Petykemano
veterán
Petykemano
veterán
Zen5 spotted? [link]
-
#8784
Petykemano
veterán
S_x96x_S
#8778
Petykemano
veterán
válasz
S_x96x_S
#8778
üzenetére
> de az extrém nagy MT -re mi lesz az AMD válasza?
Ez költői kérdés, ugye?
Természetesen a ZenXc magok jelentik a választ.Az Arrow Lake-et MLiD 2024Q4-re tette.
Azt tudni véljük, hogy a Zen5 2024Q1-ben is kiadásra kerülhet. Ha valóban csupán egy új core design N4-en, akkor ennek nem hiszem, hogy különösebb akadálya lenne.
2024Q4-re simán megjelenhet desktopon egy 8P + 16E magos Zen5+Zen5c változat.
Ha ez esetleg nem elég, akkor az a kérdés merül föl, hogy vajon a Zen5-re vagy Zen5c chipletre helyezzék-e fel a v-cache-t, amit az dönt el, hogy a Zen5c kap-e TSV-t és/vagy hogy a Zen5c design a magasabb sűrűség miatt nagyobb frekvencia/feszültség regressziót szenved-e el, mint amennyit az eddigi tapasztalatok szerint a V-cache használata megkövetel. Ha ugyanúgy 500-700Mhz-ről kell csak lemondani, akkor elég egyértelmű. -
#8779
Petykemano
veterán
Busterftw
#8777
Petykemano
veterán
válasz
 Busterftw
#8777
üzenetére
Busterftw
#8777
üzenetére
Szerintem az AMD tervei ebből a szempontból jobb helyzetbe hozzák néhány éves távlatban.
a P és E magok együttes használatában kulcstényező, hogy milyen cache köti össze őket. Jelenleg az AMD-nél a chipleteket nem köti össze semmi, memórián keresztül tudnak adatot cserélni. Az Intelnél az E és P magok osztoznak a L3$ ring buszán, de kétlem, hogy ezt 8 cluster esetén is még megtehetik, viszont a Meteor lake elvileg egy nagy cache bázislapkával készül. Gondolom az szolgál majd adatmegosztási célokat. Ez amúgy jól hangzik.
Viszont az AMD-nél elvileg az a terv, hogy a létra topológiával megoldják, hogy 16 P mag kerüljön egy lapkára.Pontosítok: Ha ez így lesz, hogy létra topológiával 16 P mag is kerül egy chipletre (L3$ kiemelve, default 3D stacked) akkor az kedvezőbb helyzetbe hozza szerintem az AMD-t, mintha 8 magos maradna a chiplet 8 / 16 magos P/E chipleteket valami cache bázislapka (L4$) kötné össze. Mindazonáltal az is hasznos lenne, a kettő nem feltétlenül zárja ki egymást.
-
#8773
Petykemano
veterán
Petykemano
veterán
AdoredTV-nek volt a napokban egy videója a a Mi300-ról, pontosabban azok variánsairól.
Természetesen csak erős idegzetűek nézzék meg. Akik képtelenek feldolgozni egy még meg nem jelent termékről szóló műsorban található pontatlanságokat, az inkább tartózkódjon ettől és várja meg a hivatalos termékbejelentéstA köztudatban eddig 1-2 Mi300 variánsról tudtunk.
- volt egy, ami 6db GPU és 3db CPU chipletet tartalmaz
- ez alapján feltételezhető volt, hogy létezhet olyan verzió is, amiben nincs CPU, csak 8db GPU chiplet.Nem meglepő módon AdoredTV videójában felvillant az a lehetőség is, hogy 9db CPU chiplet és 2db GPU kerüljön összetokozásra.
De miért ne lehetne 12db CPU chiplet összetokozva - GPU nélkül? Tulajdonképpen a megrendelő eldöntheti, hogy milyen célre milyen kombinációt szeretne összerakatni.Mindenesetre az elég kemény lenne.
V-cache a CPU chipleten, alatta a bázis lapkákon található infinity cache, amit miért ne használhatna a CPU is (L4$?), és ezt veszi körül a HBM3.Ez persze nyilván nem jelentene minden szoftver számára azonnal gyorsulást, de komoly kihívója lehet a HBM-mel szerelt Sapphire Rapids-nak és a Fugakunak vagy hozzá hasonlóknak.
-
#8771
Petykemano
veterán
Petykemano
#8761
Petykemano
veterán
válasz
Petykemano
#8761
üzenetére
Érdekes elemzés az AmpereOne A192-ről [link]
Kritizálja a teljesítmény mutatókat
Pl hogy a core/rack, amiben 3x értéket mutatnak fel, semmit nem mond a tejesítményről.
És a stable diffusiom teszt konfigurációja is sajátos. -
#8767
Petykemano
veterán
Petykemano
veterán
"According to several sources, Intel could buy Ampere Computing. At the moment, however, the price of the young company seems to be too high."
[link] -
#8765
Petykemano
veterán
Alogonomus
#8762
Petykemano
veterán
válasz
 Alogonomus
#8762
üzenetére
Alogonomus
#8762
üzenetére
Érdekes. Én épp fordítva látom.
Én nem tartom magam Arm drukkernek. Szerintem az ARM energiahatékonyságbeli előnye nem magától értetődő. Nem mondom, hogy negligálható, de szerintem tervezési okokra visszavezethető: úgy vélem, hogy az a megközelítés, amit az AMD és az Intel használ a 5-6GHz-ek elérése érdekében mind a lapkaméretre, mind pedig a 3-4Ghz-es amúgy hatékony sávbeli fogyasztásra is negatív hatással lehet.
Az bizonyos, hogy ARM alapon is lehet versenyképes processzort tervezni. Talán kijelenthető, hogy az épp vezető (Intel vagy AMD) X86 megoldáshoz képest teljesítményben általában egy generációnyira le van maradva, ugyanakkor - fentieknek megfelelően - általában nincs lemaradva gyártástechnológiában, részben ennélfogva kisebb lapkából készül és nagyonis versenyképes fogyasztással. Nyers számok alapján a bemutatott termékek számomra versenyképesnek tűnnek.
Ahogy mondod, az AMD 4 generáció óta ostromolja, küszködik a szerverpiacon való nagyob piaci részesedés elérésével. Eközben többször is volt már több szempontból jobb, de legalábbis nagyon versenyképes és kompatiblis termékük, mint a piacvezető Intelnek és idénre jósolják azt, hogy elérheti a 20%-os piaci részesedést . Mindeközben az ARM az események (az Intellelassulása) farvizén evezve olyan termékekkel, amelyekért az AMD-t kiröhögte és lesajnálta (volna) a közönség (sok, de gyengébb mag, energiahatékonyabb socket), mondhatnám különösebb megerőltetés, küszködés nélkül, szélárnyékban értek el az AMD-éhez képest 2/5-ös részesedést, miközben a megoldás használatához ahogy mondtad is, túl kell lépni a kompatibilitási kérdéseken is.
Ebben természetesen nyilván benne vannak nem csak az Ampere termékei, hanem az Amazon Gravitonm, Nvidia és esetleg más in-house fejlesztések is.
Nem állítom, hogy a kompatibilitási kérdés ne okozhatna valahol egy üvegplafont az ARM terjedésének. Elképzelhető, hogy van egy bizonyos százalék, ameddig tartanak a vállalkozókedvű, agilis cégek, és a nagy tömeg, amelyik még ma is intelt vesz, egyszerűen annyira mamut, hogy csak rendkívül nehezen állna át.
De az, hogy ennyire észrevétlenül növekszik engem nem annyira magabiztosággal (x86-biztossággal) tölt el, hanem inkább aggaszt.
Különösen akkor van ok (az x86-osoknak) aggódni, ha igaz az, hogy minden fejlesztő olyan szerveres környezetet preferál, amin fejleszt és ha a fejlesztők körében terjed az Apple M1-M2. Többek között ezért is fontos, hogy ne totojázzon az AMD a Zen5-tel. Ugyanis az Apple hamarosan előállhat az N3-on készülő új megoldásával M3-mal és a pletykák szerint az Apple is készül szerverlapkákkal, amit lehet, hogy eleinte belső használatra készítenek, de ha a cloud az új nagy piac, akkor miért ne haraphatnának bele a szerver/cloud piacba saját gyártású hardverrel, hovatovább szerverrel (hardver+szoftver)?
-
#8761
Petykemano
veterán
Petykemano
veterán
Megjelent egy video az Ampere One-ról, amin egy lapkát mutogattak [link]
1 központi Compute Die - 192 maggal, N5-ön
2db IO Die.Mivel a szerverpiacon a 4GHz feletti frekvencia, amit az asztali cpuk elérnek, gxakorlatilag nem létezik, így a ST teljesítmény, a fogyasztás és a magszám elég versenyképes lehet.
Talán kicsit kezd szorítani az idő a zen4c kihozatalára.(És hogy idén év végén mozgolódni kezdjenek a zen5-tel)
Az idő talán ott is kezd szorítani, hogy már ez is chiplet. Persze nem pont olyan, mint az AMD megoldása, ami első ránézésre lényeges előnyben van a skálázhatóság tekintetében, de az chipletezés lassan előnyből iparági standarddé olvad.
-
#8756
Petykemano
veterán
Petykemano
veterán
Kijött egy új video MLiD-től.
Új info az eddigiek felett talán nem is jelent meg az architektúráról.
Az került megerősítésre, hogy az IPC növekedést elsősorban nem cache méretek növelésével érik el, hanem architekturális változtatásokkal. Ennek megfelelően csak az L1$ mérete változik. Feltehetőleg szélesedik az architektúra. Ez alapján talán nem a valóságtól elrugaszkodott a következő szerepleosztást felfételezni, hogy minek miben van szerepe, mire van nagyobb hatással:L1$ => az architektúra szélességével függ leginkább össze - az Instruction Level parallelism (ILP)-re lehet hatással, pontosabban egy szélessebb architektúra kiszolgálásához értelemszerűen nagyobb cache szükséges. Azonos architektúra szélességet feltételezve a mérete sokkal kevésbé lehet hatással az IPC-re, mint a késleltetés.
L2$ => Feltételezve azt, hogy egy meghatározott architektúra szélesség esetén egy programszál meghatározó adataianak fontos része az L1$-ben, meghatározó része pedig a már 1MB-os L2$-ben elfér, az L2$ további növelése csak a - az SMT miatt - a multithreading teljesíményre lehet hatással.
Azonban az architektúra szélesedése nyomást gyakorolhat az L2$-re is. Szélesedő architektúra mellett változatlan L2$ méret esetleg csökkentheti a - az SMT-vel nyújtott - multithreading teljesítménytL3$ => ez már egyértelműen a magok között megosztható adatokról szól. Bizonyos méret felett már szinte semmilyen hatást nem tud gyakorolni a ST teljesítményre (különösen nem victim viselkedésű cache esetén) És össze nem függő MT programszálak esetén is valószínűleg kicsi a jelentősége. Értelemszerűen összefüggő, adatokat egymás között megosztó, közösen használó programszálak esetén is érvényes a csökkenő határhatékonyság elve.
Mindezzel együtt számomra a legmeglepőbb mégis az, hogy nem szerepelt a roadmap-en az elkövetkező szerverplatform-X esetén a 3D stackelt L3$ rétegek számának emelése.
(Egyébként az is érdekes, hogy lehet, hogy a Zen5c szerver N3-on előbb fog debütálni, mint a Zen5 szerver N4-en.)
-
#8752
Petykemano
veterán
Petykemano
veterán
Állítólag a MSFT partnerségbe lépett / segít / rendelt semi custom AI chip tervezést az AMD-től/vel
[link] -
#8747
Petykemano
veterán
awexco
#8745
Petykemano
veterán
A számok első ránézésre nem tűnnek olyan rossznak.
De valójában a visszaesés az AMD-nél is érezhető.
Nem tudom pontosan melyik hónaptól írják az AMD-hez jóvá a Xilinx bevételeit, gyanítom, hogy kb 2022Q1-től indulhatott.
Mindenesetre ha a 2023Q1-ből azt kivonod, akkor válik láthatóvá, hogy ahhoz az időszakhoz képest mekkora visszaesés van a Client computing divíziónál.
A grafikai divíziónál is a PS5-re való nagy kereslet fedi el a GPU-k iránti kereslet-visszaesést.Persze hát végső soron ezek mind a vállalat részei.
-
#8730
Petykemano
veterán
S_x96x_S
#8728
Petykemano
veterán
válasz
S_x96x_S
#8728
üzenetére
Wow
Vajon mi készül majd ott?
Kis monolitikus GPU? APU? Base die? Cache die? Zen5c?A Samsung gyártástechnológia híres arról, hogy az energiahatékonysága magasabb frekvenciákon és az Fmax is rosszabb. Elméletileg ahhoz lehet alkalmas, ahol legfontosabb szempont a sűrűség és nem szempont a magas frekvencia és nem olyan részegység, ahol nagy fogyasztás történne.
-
#8716
Petykemano
veterán
Petykemano
veterán
AdoredTV - Zen5 [link]
újdonságként ható információk:
- kétirányú gyűrű helyett létra topológia a magok közötti kommunikáciban.
- 2MB valamint 3MB L2$-sel rendelkező ES példányok. (Ennek jelentősége persze csak MT workload alatt van) -
#8692
Petykemano
veterán
Petykemano
veterán
MLiD infoi szerint Strix Halo néven jön a mega APU (40CU)
Sajnos nem budget gaming, hanem prémium mobile. 16 mag. Chiplet. Szerintem a 16 mag sok, de Végülis ha csak az IOD nagyobb, akkor lehet ilyen is, olyan is. -
#8690
Petykemano
veterán
Petykemano
veterán
AMD Zen 2 (7nm) – Valhalla
AMD Zen 3 (7nm) – Cerberus
AMD Zen 4 (5nm) – Persephone
AMD Zen 5 (3nm) – Nirvana
AMD Zen 6 (2nm) - Morpehus
[link]Különös, hogy ennyire egyértelmű nm jelzéseket köt a magokhoz.
Számomra nem egyértelmű, hogy vajon a CCD-n levő Zen4 mag, a mobil Zen4 mag és a Zen4c mag neve is egységesen Persephone-e annak ellenére, hogy sűrűségben, L3$ méretben egyébként egy más implementációt jelent és egyébként más és más gyártástechnológián készül. -
#8689
Petykemano
veterán
Petykemano
#8688
Petykemano
veterán
válasz
Petykemano
#8688
üzenetére
VCZ: [link]
-
#8688
Petykemano
veterán
Petykemano
veterán
MLID leak a Zen5 (Zen 5) Cinebench IPC témában [link]
Egy 2x64 magos Zen5 rendszer teszteredménye került ki. 123xxx multi score-ral, ami jelentékeny növekmény az eddigi Genoa eredményekhez képest, amiket a magasabb magszám ellenére korlátoz az, hogy a cB csak 256 szálig skálázódik.
A számok MLID szerint igazolják a 20+%-os várható IPC növekedést.
Érdekes, hogy a Windows által visszajelzett adatok.szerint az L2$ és L3$ mérete nem változott, míg az L1 (összesen) 64KB-ról 80KB-ra növekedett.
Ami egészen meglepő számomra, merthogy én az architektúra szélesedése nyomán az Apple által mutatott irányba való eltolódásra számítottam. Ez arra utal, hogy olyan nagy mértékben nem változtat az AMD a design megközelítésein. Ez a növekmény meglehetősen szerény. Ami persze abból a szempontból jó, hogy a magok továbbra is kicsik maradnak és teljesítménynövekmény is elég tisztességes.
A másik érdekesség, hogy MLID szerint a Zen5c, ami N3-on készül, 16 magos Lesz és a 16 mag egységesített L3$-hez fog kapcsolódni.
Ez azt jelenti, hogy tényleg elkészült ez a fejlesztés. Csupán döntés kérdése, hogy lássunk-e egy 16 magos zen5 CCD-t. Bár valószínű ez a feature inkább Zen6 formájában fog megjelenni.
A 16 magos Zen6X3D nagyon ütős lesz. -
#8687
Petykemano
veterán
S_x96x_S
#8686
Petykemano
veterán
válasz
S_x96x_S
#8686
üzenetére
Akkor csak "educated guess"
Állítólag egyébként sok CPU tervezőt csábított át az AMD-től a Tenstorrent, abből fakadóan - állítólag - közeli képük lehet, hogy mit fog tudni.
Eddig minden valós generációváltás kb 30% körüli teljesítménynövekedést hozott. Ebből változó, hogy mekkora volt az IPC és a frekvencianövekedés hatása. De mindenesetre ez a 30% nem valós mérés, hanem csak várakozás.
-
#8684
Petykemano
veterán
Petykemano
veterán
Zen5 (Zen 5) specint, spec2K17int
Tenstorrent előadásban egy charton megjelenítették a Zen5-öt

Persze a fene tudja, hogy ez valós-e, véletlenül kiszivárogtatták, vagy Jim Keller (az előadó) tudja, vagy becslés, és ha becslés, akkor mi alapján.
A valóságosságra utaló jel, hogy a Grace esetén jelezték, hogy csak becslés.
Viszont a 8.84 és 6.8 különbözete túlságosan pontos, kerek +30%. Ez meg inkább utal arra, hogy csak saccoltak.Ha az ábrán levő számok valóságosak, akkor elég szép ugrás a Zen4 és Zen5 között.
Lehet, hogy az MLiD és RGT által híresztelt 25% körüli IPC növekedés nem túlzás. -
#8683
Petykemano
veterán
b.
#8682
Petykemano
veterán
De valószínűleg ez lehet a magyarázat.
Azért érdekes info ez számomra, mert a v-cache lapkák N7-en történő gyártásával kapcsolatban felmerült az a kérdés, hogy vajon mi lehet a magyarázata, hogy ha már úgyis áttervezték, akkor miért nem N6-on készül, amikor több szempontból is előnyösebbnek kéne lennie az N6-nak (az EUV miatt még kisebb hibaarány, kevesebb maszk miatt gyorsabb megmunkálás miatt magasabb throughput, névlegesen 15%-kal nagyobb tranzisztorsűrűség, N6 valójában N7 gyártósorrol kerül átalakításra)
És voltak akik csipőből azt válaszolták, hogy az N7 gyártása biztos olcsóbb, mert az N6 újabb.
Miközben az nagyonis lehetséges, hogy 15% tr sűrűség növekedés csak "logic" típusú áramkörökre érvényes és az SRAM-ből álló a v-cache lapka esetén ebből már nem lehet előnyt szakítani, egy nagyobb SoC esetén a lapka egységnyi előállítási költségének csökkenésével jár(hat).
Az AMD mondjuk emiatt nem fog hozzányúlni a jóárasított Zen3-hoz, vagy zen3 apukhoz. De iránymutató lehet arra nézve is, hogy pl a navi33 a boltokba kerülhet-e azon az áron, ahogy most a navi23 kapható
-
#8680
Petykemano
veterán
Petykemano
veterán
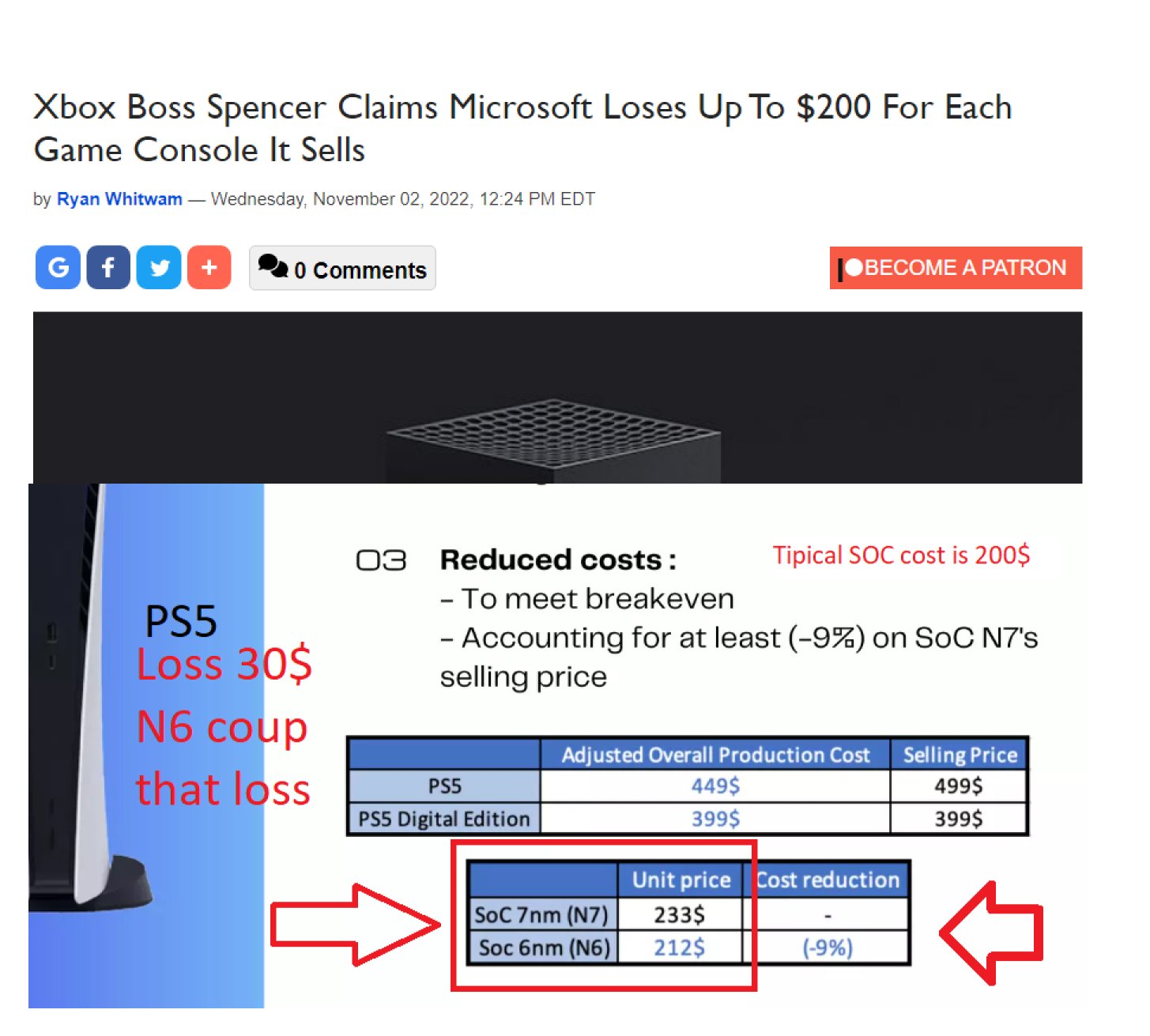
Ez egy érdekes info
Az PS5 N7-en gyártva $233 N6-on gyártva 9%-kal alacsonyabb, csak $212.
Gondolom ez az az összeg, amit a Sony fizet az AMD-nek.
Amennyiben ez így van, akkor persze nem biztos, hogy ebben a 9%-ban kizárólag az olcsóbb gyártás van benne, hiszen az AMD árszabása (marzsa) is lehet más.
Mindenesetre irányszámnak alkalmas lehet. -
#8675
Petykemano
veterán
Petykemano
veterán
Zen5 (Zen 5) IPC & others
MLID jelentetett meg egy videót, amiben egy meglehetősen konzervatív jövőképet festett fel a Zen5-ről:- elmesélte, hogy többféle Zen5 verzió is készült tesztelési és biztonsági céllal, ezek között volt olyan, ami desktopra N3-on készült és kiemelték volna belőle a L3$-t, hogy csak 3D stacked legyen - feltehetően 16 maggal -, de végül a frekvencia-regresszió és a N3 gyártástechnológia körüli bizonytalanság miatt párhuzamosan fejlesztett N4X-re épülő konzervatívabb (az előzőekhez hasonló 8 magos, embededded L3$) CCD jött ki győztesen.
- nem beszélt arról, hogy a 3D cache rétegzettségi száma esetleg növekedne
- 15-26% IPC növekedés (nyilván az IPC növekedés megfogalmazása elég tág lehet, mert valaki egy saját maga által látott szoftverbeli IPC növekményt mondhat, valaki egy átlagot, stb)
- 2-9% frekvencia emelkedés (szintén nincs részletezve, hogy mi vonatkozik ST-re és mi MT-re)
- Desktopon nem lesz mag szám emelkedés. De megjelenhet a Zen5c (32mag). Hybrid (8+16) desktop verziót az AMD szerinte nem tervez.A 128/192 magos EPYC verziókat megerősítette.
És ejtett még pár szót arról, hogy ehhez képest az Intel mennyire versenyképes palettát lesz képes felvonultatni.Nagyjából hasonlókat mondogat a RedGamingTech is. Ő is viszakozott az egységesített L2$ irányából.
Tehát összesséégben a Zen5 valószínűleg valóban egy teljesen új mag design lesz, de a magok szervezése, nem fog drámaian megváltozni. Várható a nagyobb L1$, esetleg nagyobb L2$. Ezek növekedésével a helytakarékosság érdekében én elképzelhetőnek tartom, hogy csökkentik az L3$ méretét és ráhagyják a kérdést az X3D-re, amivel komoly mennyiséget tudnak rápakolni azokra a szegmensekre célozva, ahol az számít.
(Nem szabad szem elől téveszteni, hogy az AMD fókusza még mindig a szerver.)AI, vagy FPGA, vagy más gyorsítókról volt szó, de mondjuk olyan dolgokról, hogy IOD-ra szerelhető L4$ vagy hogy a Turin Mockup-on 2x2 / 4-es szigetekbe szervezett CCD-ket valamilyen alul levő base cache die kötné össze, vagy hogy változna az eddig megszokott organikus szubsztráton keresztüli IFOP/SerDes összeköttetés (lásd Navi31) nem esett szó.
-
#8674
Petykemano
veterán
S_x96x_S
#8673
-
#8671
Petykemano
veterán
Busterftw
#8670
Petykemano
veterán
válasz
Busterftw
#8670
üzenetére
Azért nem tartom valószínűnek, hogy a legyártott mennyiség lett volna a legmeghatározóbb tényező a metszésnak, mert szerintem az Intel az Alder Lake előtt is el tudta önteni a piacot az előző generációs termékkel és az csak 30%-ra volt elég - legalábbis a Pugetnél.
A teljes piacra vonatkozó részesedésekre nézve lehet benne igazság, mert abban emlékeim szerint nem volt ilyen nagy mozgás. -
#8669
Petykemano
veterán
S_x96x_S
#8668
Petykemano
veterán
válasz
S_x96x_S
#8668
üzenetére
Az Alder Lake tetszett a népnek.
Különös, hogy nem sikerült az AMD-nek visszakorrigálnia 2022-ben, pedig végül milyen olcsóvá váltak a Zen3-ak.
(Bár lehet, hogy épp azért vált a DIY zen3 annyira olcsóvá, mert az Alder Lake miatt kiszorult az olyan prebuilt/OEM piacokról, mint amilyen a Puget Systems is)Az nem annyira meglepő, hogy a Zen4 vs RPL nem fordított.
Egyrészt érdekes lesz majd látni, hogy a Workstation számokat hogy mozgatja meg a SPR workstation érkezése
Másrészt a client részesedés és hogy a Zen4 (vs RPL) nem fordított lehet, hogy elég motiváció lehet a Zen5 pár hónappal történő előrehozatalára, ha annak technikai feltételei egyébként adottak. a 70/30 arány visszaszerzéséhez az AMD-nek előnyben kell lennie. A 70/30-hoz az Intelnek elég nagyjából egálra kihozni. -
#8667
Petykemano
veterán
ShiTmano
#8666
Petykemano
veterán
válasz
 ShiTmano
#8666
üzenetére
ShiTmano
#8666
üzenetére
Ez a gigabyte pletyka annyira zavaros, mint ha szándékosan kifejezetten zavarkeltés lett volna a célja.
Van ott minden szervertől desktopig.Nekem három tippem van:
- Ryzen néven érkezik főképp (entry level) szerver célokra AM5 platform alapon a bergamo, amit persze majd lehet frissíteni
- összeollóztak előző verziókat és ellenőrizetlenül kiengedték.
- chatGPT írta (ami ebből a szempontból ugyanaz, mint az előző, csak fancybben hangzik)Az én becslésem asszem 2024 március volt az alapján, hogy beismerték, hogy a zen4 6 hónapot csúszott a CXL miatt. Ha azt is figyelembe vesszük, hogy nincs túlkereslet az N4/N5 gyártásttechnilóguára (jelenleg a zen5@N4 a valószínű forgatókönyv) akkor lőtávolba kerülhet egy ilyen előrehozatal. És az is igaz lehet az "ugyan minek sietne?" Kérdésre, hogy az AMD értékelheti úgy a client revenue beesése miatt, hogy a zen4 nem elég csábító a platformköltség miatt, ezért nem fogy eléggé.
Ezzel együtt ez a gigabyteos szöveg annyira zavaros számomra, hogy nem mernék ebből ilyen irányú következtetést levonni.
-
#8662
Petykemano
veterán
S_x96x_S
#8661
Petykemano
veterán
válasz
S_x96x_S
#8661
üzenetére
> az i/o die-t nehezebb skálázni ..
> ( vagyis az az egyik cél, hogy az Infinity fabric ne legyen túlterhelve. )
Túlterhelve milyen értelemben?
Szerintem ha 16 mag van egy CCD-ben 8 helyett, attól a 16 magra vetített infinity fabric kommunikáció nem csökken. Amit lehet nyerni az az, hogy ha 16 magot építesz egy CCD-be, akkor azt le lehet tudni 1 IF lane-nel, míg ha egy CCD 8 magos, akkor ott mindenképpen 2 lane kell 16 maghoz.Fontos megjegyzés, hogy az 1 lane / CCD-t el lehet érni úgy is, hogy a 16 magos CCD-ben 2db 8 magos CCX van. Erről a lehetőségről egyébként én sem ejtettem szót.
> Amúgy az is lehet, hogy már a következő konzol APU-t is próbálják összerakni/demózni.
> és az két chipletes felépítésű lesz.
> - 16 magos CCX
> - RDNA4Szóval szerinted a következő konzol APU-ban nem lesznek hybrid magok?
(Jelenleg ismert variánsok: Zen4, Zen4X3D, Zen4c) -
#8660
Petykemano
veterán
Petykemano
veterán
#zen5 #zen 5 #magszám
Roppant érdekes.
Más fórumokon még élénken vitatják, hogy vajon a Zen5 hoz-e magszám emelkedést - elsősorban a CCX-en belül értve. Nemhogy 16, de még a 12 magos CCX is felmerül, amit a Mi300-ban elérhető 24 magból deriválnak.Legutóbbi videójában AdoredTV is megállapította, hogy a 16 magos CCX jelenleg valószínűtlen. Valójában ezen kívül kevés megállapítás hangzott el.
Vajon mi értelme/célja lenne a CCX-en belüli magszám emelkedésnek? A CCX-en belüli magok L3$-en keresztül tudnak egymással adatot megosztani, egymás közötti késleltetésük alacsony. Tehát 8-ról 12 vagy 16-ra növelni az egy L3$-hez kapcsolt vagy CCX-en belüli magok számát - ennek értelme akkor és ott lenne, amikor olyan alkalmazás fut, ahol a szálak kommuninálnak, adatot osztanak meg egymással és egy ilyen alkalmazás 8 magon túl terjeszkedik, vagy legalábbis több erőforrást használna.
Világos, ha jelenleg egy ilyen élénk szálközi kommunikációval működő program túlterjeszkedne a 8 magon, akkor abból olyan bedadogás (lassulás) keletkezne, mint amit a 4 magos CCX-szel rendelkező Zen processzorok esetén láttunk.
12 vagy 16 magos CCX esetén a program máris terjeszkedhetne 8 magon túl anélkül, hogy a megnövekedő késleltetés miatti teljesítményvesztést el kéne szenvednie.De ennek a célnek az eléréséhez vajon valóban a CCX-en belüli magok, vagyis az L3$-hez kapcsolt magok számának növelése az egyetlen és leghatékonyabb útja?
Leginkább amiatt vetődik fel bennem ez a kérdés, mert szerintem míg a játékok terén ennek hosszútávon - ha a programok is úgy akarják és az Intel is felkészült - lehet, hogy lehet valamilyen pozitív hatása, addig szerintem a szervereknél szinte semmi. Miért tenné meg akkor az AMD?
Mielőtt válaszolni probálnék a kérdésre, elmondanám az alternatívát:
Tehát szerintem szerverek esetén nem sok haszna volna a 8 helyett 16 magos CCX használatának (most itt a lapkaméretet még hagyjuk)
Ha viszont desktopon - vagy a ThreadRippernél - a minimum 2 CCD-s összeállításoknál szempont a CCD-közi késleltetés csökkentése, akkor azt egy IOD-hoz kapcsolt (3D) SLC-vel is meg lehetne oldani, ami kicsit ahhoz hasonlóan működhetne, ahogy a Navi31 esetén is az MCD-be épített infinity cache tulajdonképpen a MEmóriavezérlő előtti bufferként fogható fel. Ezt használhatnák a CCD-k, vagy CCD helyett egy GCD is, vagy az IOD-ba épített IGP.Egy ilyen megoldás enyhítené a CCD-CCD kommunikáció késleltetését és tudná tompítani a másik CCD-re való szál-átugrás problematikáját. Megkockáztatom, hogy az AMD hybrid architektúrájának jelenleg kritizált problémáit (a 3DCCD-ről szál kiszorulása vagy rossz ütemezése miatti dadogást) enyhítené. Persze az IOD-ra helyezett SLC-nek akkor tényleg méretesnek kellene lennie.
Viszont ha ennek ugyanúgy nincs haszna a szerverpiacon, akkor miért csinálná ezt az AMD? Hiszen soha semmit nem csinálna kizárólaga desktop piacra.
Erre a kérdésre a válasz az lehetne, hogy a CCD-CCD kommunikáció késleltetésének csökkentése inkább mellékterméke lehetne az elsősorban a mobil piacra gyártott chiplet APU-knak, amelynél a GCD külön van gyártva, és egy szincén külön gyártott MCD-hez, vagy más esetben IOD-hoz kapcsolódik, amely valamilyen módon tartalmazza a komolyabb GCD a korlátozott memóriasávszélességgel rendelkező környezetben való működéséhéz szükséges infinity-cache-t.Mi viheti rá mégis az AMD-t arra, hogy 12 vagy 16 magos CCX-ez készítsen?
A lapkaméret, vagy költséghatékonyság.Sajnos ugye számokat egyik elképzelés mellé sem tudok rendelni. Bár azt gondolnám, hogy a 3D tokozás a következő 1-2 évben csupán 1-2 dolláros többletköltséggé fog redukálódni és elég sokat lehet majd nyerni azon is, hogy nem a legfejlettebb gyártástechnológiát használod. Azt sem tudom, hogy vajon 16 mag egy L3$-hez rendelésének milyen többletköltsége van: szükséges-e a méret kétszeresre növelése úgy is, hogy előzőleg duplázták az L2$-t? Kell-e növelni az asszociativitást? Mennyivel nagyobb tag szekcióra van szükség, stb És ugyanúgy nem tudom, hogy ha ugyanezt az L4$ esetén kell megvalósítani, akkor az mit jelent.
De egy olyat el tudnék képzelni, hogy ha az AMD lecsökketi a bázis L3$ méretét a Zen5-ben - adabszurdum 0-ra - akkor annyira kicsi lenne már a CCD, hogy azért muszáj emelni a magszámot, mert különben túl nagy lenne rá a 35mm2-es v-cache. (már amennyiben azt továbbra is N7-en gyártják)
Azon sem lepődnék meg, hogy ha a következő 1 évben több különböző Zen5 lapkamérettel és L3$ konfigurációval találkoznánk a szivárgásokban.
-
#8659
Petykemano
veterán
Petykemano
veterán
Állítólagos Hybrid Phoenix 2
-
#8656
Petykemano
veterán
S_x96x_S
#8654
Petykemano
veterán
válasz
S_x96x_S
#8654
üzenetére
Én meg úgy értettem, hogy ha jön a Meteor lake (mobil), akkor arra lehet, hogy kénytelen lesz az AMD nem csak egy 8, hanem egy 6 magos mobil, v-cache-sel szerelt dragon range-t is kiadni. (7645HX3D)
Ennek esetleg lehet leeső morzsája egy egy asztali 7600X3D is.A kérdés csak az, hogy egy 7845HX3D, vagyis 8c+3D mellett miért akarna vagy lenne kénytelen egy 6 magosat is kiadni, amikor a meteor lake eleve csak 6 magos lesz? Nyilván nem muszáj. A meteor lakeből biztos lehet majd 6+16, 6+8, 6+0. Az első ellen a 8c+3D valószínűleg multiban elvérzik (ami nem biztos, hogy baj), a második ellen versenyképes, utolsó ellen viszont túl erős. Utóbbi ellen be lehet dobni valami gyengébbet (8c Dragon vagy Phoenix), de az meg gaming terén nem tudná tartani a lépést.
Egyik sem olyan, amire azt mondanám, hogy na most itt már komoly lépéskényszer áll fenn, csak hogy nyílik egy ajtó.
-
#8653
Petykemano
veterán
b.
#8652
Petykemano
veterán
Én kétlem, hogy lenne 7700X3D
De persze nyilván attól függ, milyen minőségből mennyi keletkezik. Ha esetleg van hibás v-cache (olyan mennyiségben), ami csak 32-48MB-ig jó, abból lehet.
7600X3D-t viszont rebesgetnek. De gondolom persze ezt se szándékosan, hanem gubizva:
7800X3d, ami túlmelegszik
7900X3d, aminek a sima ccdje hibás.A 7600X3D szerintem akkor kerülne piacra, ha a meteor lake megérkezik. Az elvileg eleve 6P magos csak. Tehát kellhet olyan 6 magos Dragon range, ami konkurenciát állít.
-
#8650
Petykemano
veterán
Petykemano
veterán
Állítólagos hivatalos 7800X3D
-
#8647
Petykemano
veterán
Petykemano
veterán
Volt egy kis AMD ismertettő a második generációs V-cache-ről
- N7-en készül
bár sikerült tovább növelni a tranzisztorsűrűséget, így bennem felmerült a kérdés, nem N6-e valójában és ha nem, akkor miért nem?- 36mm2
ami a Zen4 L3$-hez képest jelentősen nagyobb, mivel az csupán ~25mm2Emiatt rálóg a v-cache az L2$-re. amit ki kellett egészíteni ún power TSV-kkel.
Ez kissé sajnálatos. Talán izgalmasabb lett volna, ha 2nd gen V-cache esetén az L2$ bővítése is lehetséges. Máskülönben viszont azt is jelenti, hogy ha a következő generáció úgy készül, hogy az L3$-t kiemelik a CCD-ből, és 3D stackelve építik rá, akkor valójában ebben nem jelent gondot/akadályt az se, hogy ha a v-cache az L2$-t fedi.
-
#8642
Petykemano
veterán
S_x96x_S
#8641
Petykemano
veterán
válasz
S_x96x_S
#8641
üzenetére
Nem vagyok róla meggyőződve 100%-ig, hogy technológiai/gazdaságossági kérdés áll a háttérben.
Bár az igaz, hogy ha két hőtermelő pont van, azt könnyebb lehet hűteni, de egyben design szempontjából drágább is.
De szerintem ennek nem hűthetőségi tech szempontból van jelíntősége. Az tudható, hogy az AMD design winek a notebook piacon valójában szinte mind eredetileg intelhez (+nvidia?) tervezett kialakítások, amelyekből azért kap az AMD is egy vonalat, mert az AMD "kompatibilis" (itt persze nem socket kompatibilitásra kell gondolni, hanem fizikai kéret, magasság, meg ilyenek) chipeket tervez. Nem vagy nagyon kevés design készül elsődlegesen AMD hardver köré.Vagyis szerintem azért nem készül big apu, mert az OEM gyártóknak nincs olyan notebook designja, ami egy pontról lenne képes nagyobb hőt elvezetni és csak az AMD kedvéért nem is fognak ilyet tervezni. Ez nekik gazdaságossági kérdés persze, de semmi köze a kupak alatti dolgokhoz.
Egy másik ehhez kapcsolódó szempont lehet, hogy az oemek esetleg Szeretnék megtartani maguknak azt a lehetőséget (versenyeztetési lehetőséget) hogy ők válasszanak gput.
Egyébként MLID valami olyasmit mondott, hogy 4050-ig bezárólag jöhet AMD apu.
Az kis jóindulattal 3060, vagy rx 6600. Nagyjából erre a szintre érkezik a 200mm2-es navi33. Ha ez idén megérkezne, az szerintem kielégítő volna. Csak akkor tűnik "kevésnek", ha ezek 2025-ös tervcélok. -
#8639
Petykemano
veterán
S_x96x_S
#8638
Petykemano
veterán
válasz
S_x96x_S
#8638
üzenetére
Az nem annyira meglepő, hogy a Phoenix nem támogatja. Nincs' benne elég igp kakaó ahhoz, hogy érdemben befolyásolja, komolyabb dgpu mellé pedig valószínűleg úgyis a dragon range-t szánják (8 maggal)
Ami a videoban sokkal érdekesebb az az, hogy MLID szerint az AMD talán próbálgatja, de komolyan nem tervezi olyan nagyobb gpu erővel rendelkező apu piacra vitelét, amely számára indokolt lenne a 3d stacked.infinity cache a korlátozott rendszermemória sávszélesség kompenzálására és amellyel megtámadhatná a belépőszintű dgpuk piacát.
-
#8633
Petykemano
veterán
HSM
#8632
Petykemano
veterán
Lehet, hogy az ilyen nagyfogyasztású kártyák relatíve ritkák, ugyanakkor talán az elmondható, hogy ahhoz, hogy a 13900K, 7950X, 7950X3D magasságú processzorok játékok terén az ilyen nagyfogyasztású GPU-k mellett tudják igazán megcsillogtatni a tudásukat. Nem?
Viszont ettől függetlenül van más, ennél talán sokkal fontosabb aspektusa a dolognak: a 7800X3D, pontosabban annak mobil változata elképesztően versenyképes gaming teljesítményt biztosíthat elképesztően hatékonyan/energiatakarékosan.
-
#8631
Petykemano
veterán
S_x96x_S
#8630
Petykemano
veterán
válasz
S_x96x_S
#8630
üzenetére
A teljesítmény valóban megvan az Intel részéről de a fogyasztásbeli különbség nagyon durva:
[link]
A dolgot még csak az sem árnyalja, hogy az Intel esetén ez a fogyasztás csak amiatt áll elő, mert az utolsó párszáz mhz már durván meredek fogyasztási görbén lenne. Az intel gyártástechnológiájára ez a meredekség ugyanis kevésbé jellemző, ezért tudott mindig is - persze növekvő fogyasztás mellett - jól skálázódni.
(Persze az is világos, hogy nem ez az 50-60W lesz a meghatározó a 400-500W-os videokártyák mellett.)
-
#8626
Petykemano
veterán
paprobert
#8624
Petykemano
veterán
válasz
 paprobert
#8624
üzenetére
paprobert
#8624
üzenetére
> Az Intel gyártástechnológiai hátránya leginkább abban mutatkozik meg,
> hogy maximum terhelésen irdatlan magas a fogyasztás.Igen, de ez döntően a maximális MT terhelés folyamán mutatkozik meg. Játékokban tudtommal normálisnak mondható a fogyasztás.
Azt gondolom, hogy ezt az Intel több kis mag hozzáadásával tudná megfelelően kezelni. +2 atom cluster biztosan kellően nagy mértékben emelné a MT teljesítményt és lehetne csökkenteni az órajelet 3-500MHz-cel.
Bocsánat, nem szétoffolni akarom a topikot. Csak azért említettem meg, mert szerintem az Inteltől ebben a vonatkozásban ugyanazt a megoldást fogjuk látni, mint amit az AMD is csinál (ZenX+ZenXc) hogy külön lapkán fogja hozzácsatolni a 8 nagy maghoz a 2-4-8 (majd kiderül) atom clustert. Már csak azért is, mert az L3$-hez csatolt magok/clusterek száma nehezen skálázható tovább.
Ha tippelnem kéne, akkor azt jósolnám, hogy az Intel hamarabb fog egy tile-on L4$-t adni a 8 nagy mag és a kismagok összekötésére.> Ennél sokkal jobbat chipletezéssel már nagyon nehéz elérni.
Szerintem valamikor a közeljövőben el kell / el fogják engedni a SerDes-t és áttérnek horizontális csatolásra (SoIC_H) vagy hasonlóra (lásd Navi31)
> A kérdés, hogy hogyan fog tudni szélesíteni az AMD a jövőben, hogy ne essen visssza a latency Zen1 szintre?
Ha nem akarnak elindulni az M1 irányába, akkor én a megoldást a 3D packaging-ben látom.
Azt gondolom, hogy ha az L3$-t sikerült 3x-os méretre emelni 5%-os késleltetés emelkedés mellett, akkor ugyanezt meg lehetne tenni az L1$ és L2$ esetében is. Persze elég valószínű, hogy ez nem lehet opcionális, mint most a v-cache.#8625 HSM
Ez így van, de azért az Intel is küzd már pár éve a Foveros-szal és az EMIB-bel. Szerintem ott szúrták el, hogy azt gondolták, hogy ez egy egyszerű gyártástechnológiai trükk, és mindent is akartak egyszerre. De azért lassan csak meg kéne már érkezni! -
#8620
Petykemano
veterán
Petykemano
#8618
Petykemano
veterán
válasz
Petykemano
#8618
üzenetére
Az jár a fejemben, hogy azért az Intel akkor valamit mégiscsak jól csinál...
az N5 azért valamivel mégiscsak fejlettebb gyártástechnológia, mint az Intel 7. Tranzisztorsűrűségben mindenképp és talán fogyasztásban is.
70-80mm2-es N5 lapka + ~120mm2-es N6 lapka. Utóbbiban döntően olyan részegységek vannak, amelyek N5-ön sem lennének sokkal kisebbek. Tehát az egész nyugodtan tekinthető egy kb 200mm2-es lapkának. Persze az AMD gyártási költség vonatkozásában talán sokat nyer azon, hogy a lapka nagyobb része mégse a drágább gyártástechnológán készül, de valamit meg veszít (latency) azáltal, hogy a chipleteket össze kell kötni.Ha pontos akarok lenni, akkora 2CCD-s változathoz két ~80mm-es lapka kell, ami már nem is 200 akkor, hanem 280. És ahhoz, hogy ez elérje azt a játék teljesítményt, amit az Intel lapkája tud, rá kellett még pakolni legalább egy kb ~40mm-es cache lapkát. Ez alsó hangon 240, felső hangon 320mm2 lapkát jelent. Nem is beszélve a 3D packaging költségéről, hibalehetőségeiről.
(Persze az is világos, hogy az AMD nem a legjobb asztali CPU teljesítmény elérése érdekében csinálja így, hanem pont a skálázhatóságért.)
Tulajdonképpen az AMD használ most több szilíciumot, komplexebb a gyártástechnológiája. Persze cserébe lényegesen jobban skálázható, szűkös waferkapacitások esetén talán előnyösebb allokációs lehetőséggel.
az Intel core design-ja szerintem valamivel jobb, de valószínűleg lényegesen nagyobb, ami sokat ront a skálázhatóságon. A MT teljesítményt kismagokkal érik el, ami az asztali környezetben jól mutat, de az elvileg jobb core design szerverkönyezetben való költséghatékony újrahasznosítását nem segíti. (feltéve, hogy az Intel nem akar ott is hybrid designnal megjelenni) Ha az AMD core design-ja egyszerűbb és kisebb is, viszont az AMD több packaging trükköt kellett felhasználnia. Tehát míg az Intel előtt még mindig nyitva van az a 3D packaging / v-cache lehetősége a teljesítmény további növelésére, addig ezt a lapot az AMD már lehívta. Az AMD chipletezik, lehívta az ebből fakadó költség és volumen előnyöket, addig az Intel előtt ez az út még mindig nyitott.Én azt látom, hogy az AMD lehívta az előtte álló core design-on kívüli low-hanging fruits-ok lehetőségeit és következő lépés mindenképpen a core design komoly átalakítása. Erre egyébként elő is készítették a terepet a Zen4c bevezetésével. Megengedhetik maguknak azt, hogy hízlalják a magot, ha annak lesz karcsúsított változata is párhuzamosan.
És lassan az Intel is talán megérkezik a saját packaging technológiáival, chipleteivel.
-
#8618
Petykemano
veterán
Petykemano
veterán
Azt írják, átlagban 5-6%-kal gyorsabb,. mint az 13900K
Ezzel a táblázattal kiegészítve: [link] mondom, hogy a különböző mérésekből az derül ki, hogy a 13900K 10%-kal általában gyorsabb, mint a 7950X.
Ez azt jelenti, hogy a 7950X3D kb 15%-kal lehet gyorsabb átlagosan, mint a 7950X
(Mint ahogy a fenti kép is mutatja, elképzelhető, hogy bizonyos játékokban ennél nagyobb gyorsulás is mérhető, másokban meg egyáltalán nem.) -
#8615
Petykemano
veterán
Petykemano
veterán
Zen4X3D tesztek: február 27-én [link]
-
#8607
Petykemano
veterán
hokuszpk
#8606
Petykemano
veterán
válasz
 hokuszpk
#8606
üzenetére
hokuszpk
#8606
üzenetére
> az L3 ha jóltévedek victim cache. azaz az előtte lévő szintekből kicsorgó adatokat tárolja.
> Szvsz dupla méretú L1 -ből kevesebb adat csorog le.
Igen, de ez magonként csak +0.5MB, egy CCX-ben összesen 4MB többlet. Ez magonként 0.5MB-nyi adat gyorsabb hozzáférését teszi lehetővé, mivel az a 0.5MB nem az L3$-ben, hanem az L2$-ben van.De a Zen architektúra achilles sarka nem ez, hanem a chiplet felépítés miatt magasabb késleltetésű memóriaelérés. (Nem tudom esetleg a sávszélesség jelenthet-e bármilyen limitációt, mindenesetre itt van olyan Genoa konfiguráció felvázolva, ahol 2 GMI linken kereszül csatlakozik egy CCD) Az, hogy a memóriavezérlő elérése nem valamilyen belső buszon közelre történik, hanem szubsztráton keresztül, biztosan limitáló tényező.
A lényeg, hogy a 32MB helyett 96MB L3$ viszont nem 4MB valamiyel gyorsabb elérését teszi lehetővé, hanem 64MB-ét pont azon a ponton, ahol a legérzékenyebb.
Persze nyilván az L3$ cache méretére igaz a csökkenő határhasznosság elve.
> Zen5 -re volt valami hír, hogy összevonják az L2 -t ;
> ha igaz a hír megkockáztatom, hogy bazi nagy közös L2 mellett akár el is tűnhet az L3.Szerintem 8 mag számára közös L2$-t csinálni megfelelő gyorsaságban és hogy akkor is kielégítő teljesítményt nyújtson, amikor a magok nem valami közös problémán dolgoznak, nehéz lehet.
A szóbeszéd szerint a szerverek szeretik a gyors privát L2$-t.Az L3$ eltűnhet, de valószínűbbnek tartom, hogy 3D stackelik.
Az még esetleg lehetséges út, hogy elengedik a szubsztráton keresztüli kapcsolatot (SerDes) és az IOD és a CCD között a NAvi31-nél látott módon (MCD-GCD) teremtenek szélessávú kapcsolatot. Ebben az esetben a stacked L3$ már mehetne az IOD-ra is és akkor az minden CCD-t ki tudna szolgálni. Ez abból a szempontból is, jó volna, hogy a CCD helyett az IOD-nak lehet kliense egy GCD is, vagyis egy IGP és akkor máris sikerült megoldani az APU-k 3D stackelt v-cache/infinity cache kérdését is.Azt persze nem tudom, hogy ez tényleg jó irány-e. L3$ nélkül azért az egész félkarú óriás. EGy ilyen bonyolult packaging drága is lehet, meg növelheti a hibaarányt is, meg volumenkorlátos is lehet ahhoz képest, ha van egy közepesen jó, de minden extrát nélkülöző alap lapkád, amit végtelen mennyiségben, hibátlanul, olcsón tudsz kipumpálni és szükséges esetén, kisebb volumenben ezzel-azzal dekorálni.
Az AMD eddig megfigyelt kockázatvállalási hajlandósága mellett azt gondolnám, hogy inkább valószínűtlen a kizárólag egzotikus kialakításra, 3D packagingre építő megközelítés nagy volumenben, olcsón gyártható jó mainstream bázislapka nélkül. (És szerintem L3$ nélkül nem lenne jó)
-
#8604
Petykemano
veterán
hokuszpk
#8603
Petykemano
veterán
válasz
hokuszpk
#8603
üzenetére
Fene tudja
Azt biztos, hogy a frekvencia-regresszióval kapcsolatos gyermekbetegségek javítására vonatkozó előzetes hírek félreértésnek bizonyultak.
Az AMD saját bevallása szerint 1% IPC növekedést tulajdonít önmagában a L2$ duplázott méretének. Ami laikusoknak egyrészt meglepő, másrészt viszont mindenhonnan azt hallani, hogy cache méretének egyszerű növelésétől ritkán változik a teljesítmény nagymértékben, hanem a megnövelt cache mérete köré kell tervezni a processzor többi aspektusát is és úgy aknázható ki a nagyobb cache nyújtotta előny (most azt a részét, hogy a cache méretének növelése késleltetés növekedésével is együtt jár és azt a trade-off-ot is figyelembe kell venni, hagyjuk)Az a gyanúm, hogy a 3D V-cache haszna is félig-meddig úgymond "véletlen". Nem emlékszem olyan programra, ahol egyszálas teljesítmény nőtt volna annak hatására. A kellemes hatását ott fejti ki, ahol a magok között adatmegosztás zajlik és a megnövelt v-cache már kellően nagy ahhoz, hogy durván sokminden beleférjen.
Mivel nem hallottunk arról, hogy a V-cache-t bármi módon tweakelték volna, ezért az én várakozásom az, hogy pontosan ugyanúgy fog működni, és ugyanakkorát fog dobni a teljesítményen is, mint az 5800X3D.
HA jól megy a hybrid mód a 12 és 16 magos példányok esetén, akkor el tudok képzelni egy olyan szituációt, hogy ha a független programszálakat a v-cache nélküli CCD-n az adatmegosztókat pedig a v-cache-sel szerelt magokon futtatja, akkor nagyobb is lehet az előny. -
#8602
Petykemano
veterán
Petykemano
veterán
Egy 7950X-szel összehasonlítva nem mutatkozik meg GB5-ben a megnövelt L3$-ben rejlő potenciál.
-
#8599
Petykemano
veterán
Petykemano
veterán
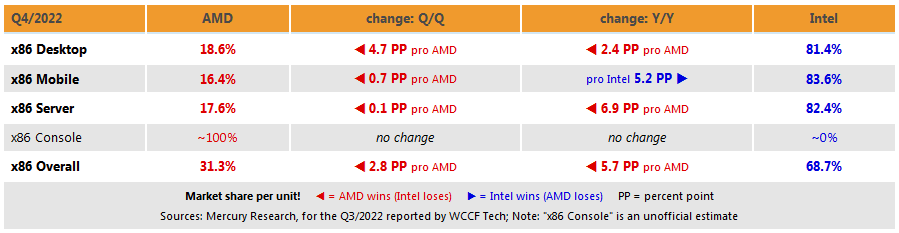
2022Q4 cpu részesedés
-
#8598
Petykemano
veterán
Petykemano
veterán
Zen5 (Zen 5) pletykák. [link] (RedGamingTech)
- 22-30% megcélzott IPC növekedés
- 8 magos CCX
- nagy L1$
- egységesített L2$ a CCX-ben
- az L3$-re vonatkozó rész elég zavaros. De megemlítésre kerül egy L4$, amit az IOD kaphat?Ha azt vesszük alapul, hogy a Zen5-tel szélesíteni szerették volna az architektúrát, és ennek része a nagy L1$, nem látom irreálisnak a 22-30%-ot.
Az elmondottak eléggé az Apple M1-re hajaznak.Viszont ezt a CCX-re nézve egységesített L2$-t nehezen hiszem. Tudomásom szerint a relatív gyors privát L2$-t szeretik a szerverek és az egyszálas programok.
Én inkább azt tartanám valószínűnek, hogy 2, esetleg 4 magra nézve vonják össze az L2$-t. Nagy és gyors privát L1$ és néhány mag között megoszott L2$ - az Apple M1 is így csinálja.
2 mag közötti L2$ megosztás nem biztos, hogy olyan hasznos, túl kevésnek tűnik, 8 viszont túl sok. 4 ideálisnak tűnik.
És persze az L3$ a továbbiakban 3D stackelve lesz.
Talán az, hogy eltérő infók jönnek azért van, mert CPU-k esetén a 3D stackelt v-cache L3$ lesz ami CCD-ben található CCX-ek számára, APU esetén viszont System Level Cache, amit a CPU és az IGP is használ. -
#8584
Petykemano
veterán
S_x96x_S
#8583
Petykemano
veterán
válasz
S_x96x_S
#8583
üzenetére
> De a teljes zen5-ös termékskálát nem hiszem, hogy ki fogják hozni idén ..
Én se. még a Zen4 leszármazott termékek se rajtoltak el.
Az tűnik valószínűnek, hogy a CES-en demóznak valamit. Onnan 1-2-3 hónapig lehet váratni a termékeket.> ha jól látom, a végleges gyártósor még lebegtetve van .
.
Én arra tippelnék, hogy ahogy a Zen4 CCD N5 volt és a Zen4 apu N4 és feltehetőleg a Zen4c is N4, ennek megfelelően a Zen5 N4 lesz, és az akár fél évet késő Zen5 apu és a Zen5c lesz valamilyen N3 változat. -
#8582
Petykemano
veterán
S_x96x_S
#8581
Petykemano
veterán
válasz
S_x96x_S
#8581
üzenetére
Igen.
Csak nekem volt itt 2022 júniusban egy írásom, amiben amellett tettem le a voksom, hogy a Zen4 késett. Akkor persze még a szóbeszéd a covidot emlegette, Norrod döntése később derült ki. A lényeg, hogy jó megérzés volt, hogy a Zen4 megjelenési dátumáig eltelt idő az általa elhozott fejlődéshez képest aránytalanul nagy volt.Ezzel együtt azért szerintem hozzá kell tenni, hogy nekem nem tűnt úgy, hogy az Am5 platform már nyár elején készen várta volna. Tehát valószínűleg olyan csúsztatás lehetett, amiről a partnereket is időben értesítették.
Augusztusban volt egy erre alapozott tippem a Zen5 megjelenési dátumára is. (=> 2024-03)
Viszont ha a Zen4 későbbi megjelenése úgy történt, hogy a feature lock - esetleg a CXL kivételével - rendes időben történt, tehát nem volt Zen5-től lehozott fejlesztés, mint a Zen2 esetében, akkor azt azt is jelentheti, hogy Zen5 ~18 hónapját nem biztos, hogy a Zen4 tényleges megjelenési dátumához kell viszonyítani, hanem ahhoz, hogy akár 2022Q2-höz képest, amikor akár meg is jelenhetett volna. Erre alapozódhattak azok a pletykák - MLID - amelyek nagyon hamar, 2023Q4-re tették a Zen5 rajtját.Legalábbis a tudatos és szándékos halasztás egy strigula abba az irányba, hogy akár lehetséges lehet. Persze nyilván vannak más szempontok is. Többek között hogy lesz-e akkor már elérhető gyártósor, amin a Zen5 készülne, valamint hogy az AMD-t a versenyhelyzet rákényszeri-e arra, hogy kiadja (Intel, Meteor Lake, Intel4, stb) vagy inkább pihenteti a fiókban, ha megteheti.
-
#8580
Petykemano
veterán
Petykemano
veterán
Zen 4 patches started appearing at the end of 2021.
Zen 1 and Zen 2 developed by first team
Zen 3 and Zen 4 developed by second team
AMD's newish cadence should be around 18 months and Zen 4 should have launched earlier, but Norrod postponed it by 2Q to add CXL.
I would say early 2Q24 should be the launch window considering the team developing Zen 5 is working in parallel.
Which makes it 18 Months after Zen 4 (if you add the additional 2Qs of Zen 4 push back that makes it two years from the supposed original Zen 4 planned launch, from Forrest Norrod's statement)
So, I would not be surprised if they launch Zen 5 at CES24
[link]Ez persze nem hivatalos, de két érdekes információmorzsa:
- a Zen4 2 negyedéved csúszott a CXL integráció céljából.
- A Zen4 szokatlan késését figyelmen kívül hagyva, a szokásos 18 hónapos fejlesztési idővel számolva a Zen5 2024Q2-ben érkezhet CES24-es bejelentéssel. -
#8575
Petykemano
veterán
aquark
#8566
Petykemano
veterán
Jelenlegi pletykák szerint:
Lehet olyan kisméretű apu, ami 2 teljes értékű Zen4 maggal és 4 Zen4c maggal fog rendelkezni.
Efölött a normál 6-8 magos apu, 6-8-12-16 magos CPU
És nem kizárt, hogy a Bergamo.megjelenését követően lehet olyan CPU, ami 1 zen4 CCD-t és 1 zen4c CCD-t fog tartalmazni.Az IGP tarolására vonatkozó jóslatokat óvatosan kezelném azokután, hogy az RDNA3 egyelőre nem hozza az elvárásokat.
-
#8565
Petykemano
veterán
ShiTmano
#8563
Petykemano
veterán
válasz
ShiTmano
#8563
üzenetére
"Szerintetek milyen hatással lesz az árakra a PC piac gyengélkedése?"
Szerintem lassú árcsökkenésre lehet számítani.
Egyrészt az Intel a veszteség ellenére kifizeti az osztalékot. Van, ami sérthetetlen.Másrészt a cégeknek nyilván vannak költségeik. Részben munkerő. A fizetések ritkán csökkennek, inkább elbocsátani szoktak. Ez egyébként elég sok tech cégnél meg is történt már. Tízezrével. Részben gyártási költség, anyagköltség. Valószínű, hogy a visszaeső kereslet miatt persze ezeknek az ára is lassan csökkeni kezd majd. Először ott is a margó kárára, meg leépítés és persze az ottani beszerzési árak lenyomására tett kísérlet.
Míg a hirtelen megugró keresletre nagyon gyorsan áremeléssel reagálhat egy termelési lánc, a visszeső kereslet miatti ármérséklődés a láncolaton nagyon lassan fog szerintem majd végbemenni.Harmadrészt nyilván a termelési lánc minden szintjén vannak készletek az elmúlt 1-2 évből, amelyeket drágán álítottak elő vagy drágán szereztek be. Gondolhatunk itt mindenféle anyagköltségre, mint réz, alumínium, stb (itt persze nyilván nem csak az Intelre, vagy a chiptervező cégekre, hanem a teljes termelési láncra kell gondolni) vagy akár a TSMC-től drágán megvásárolt termelőkapacitáson legyártott chipen át egészen drágán vásárolt energiára (ilyenekkel küzd valószínűleg a magyar gázelosztó is, de sok magyar cég is, amely ősszel kötött éves szerződést.)
És amíg a drágán megvásárolt készletek ki nem pörögnek, addig nehéz árat csökkenteni.Persze nem zárható ki a CPU piacon sem egy összehangolásra épülő árfixációs tevékenység. Legalábbis bizonyos piacokon. Bár ez azért talán nehezebb dió, mint a GPU-k területe. A Szerver piacon nehéz ügy, mert számos ARM alapú versenyzővel is össze kellene kacsintani. A desktop piacon lehetséges. Ott az egyetlen komolyan vehető versenytárs az Apple, ami így is drága. Ennek ellenére viszont jobb annyival a megítélése, hogy piacot tudjon szerezni.
Ezzel együtt azért egy árazási összezárás nem zárható ki.A Mai MLID rész témába vágó: [link]
-
#8560
Petykemano
veterán
Petykemano
veterán
Zen5
"Not sure if this is widely known, Zen 5 is family 26/1Ah. Kernel patches are landing now."
[link]
Nem tudom, hol kellene nézni. -
#8555
Petykemano
veterán
Petykemano
veterán
“We like the looks of the MI300 and the MI400 and the roadmap, but the software ecosystem is still a problem,” said Tease. [link]
-
#8537
Petykemano
veterán
Petykemano
veterán
TSMC N3, N3E, N3P, N3X, N3S stb [link]
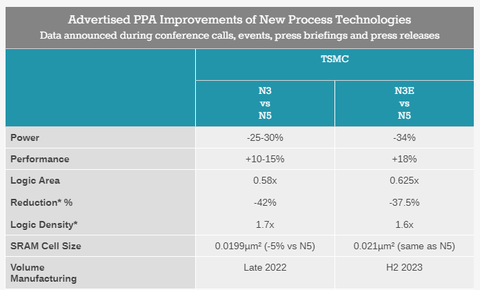
Van némi 20nm-es érzésem az N3-mal kapcsolatban. a 20nm is a planar tranzisztor fejlődési ciklusának a vége volt. Ott mondjuk pont fordítottja volt, hogy a sűrűséget (tranzisztorméretet) sikerült ugyan növelni, de a tranzisztor fogyasztását már nem, ezért a sűrűbb tranzisztorok hőtermelése nem csökkent és így túlságosan megnőtt a hősűrűség. Emiatt pedig valójában a sűrűségből fakadó előnyöket nem is lehetett kihasználni, ezért érdemesebb volt inkább 28nm-en maradni.
Persze annyiból is más a helyzet, hogy az AMD már majd megteheti, hogy a GCD-ben nem növeli, vagy egyenesen csökkenti az SRAM mennyiségét, cserébe valami régebbi gyártástechnológán gyártva mellé vagy fölé stackeli. (megkockáztatom akár az L2$-t is - szerintem az Nvidiánál ez fog történni)
(Hozzá kell tenni, hogy ez csak a TSMC N3-as node-jára érvényes, ami finfet. a Samsung GAAFET node esetén elvileg újra van sűrűségbeli skálázódás.)
És az nagyon kemény, hogy a TSMC-től a szintén GAAFET N2 csak 2026-ban fog felfutni.
Na de lássuk csak?
N5-ön az Apple gyártatott már 2021-ben. Ugyanez 2022 vége felé vált elérhetővé az AMD és az Nvidia részére.
Az Apple N3-on (vagy valamelyik variánsán) 2023 második felében kezd el gyártani. Akkor ez várhatóan 2024 végén-2025 elején válik majd elérhetővé a többieknek.
És akkor várhatóan 2026-ban - a szokásos 2 éves ciklustól elcsúszva- válhat az apple számára elérhetővé az N2.Itt lehet, hogy ebben a 3 évben nyílik egy ablak a Samsung számára.
Viszont másrészről meg nyilván áthelyeződik a hangsúly a 3D packagingre, és a tervezésre. -
#8524
Petykemano
veterán
Armagedown
#8522
Petykemano
veterán
válasz
 Armagedown
#8522
üzenetére
Armagedown
#8522
üzenetére
Elnézést, valóban.
Mentségemre szóljon, hogy ne a TSMC pénzügyi eredményei voltak a célkeresztemben, hanem hogy abból milyen következtetést lehet levonni az AMD wafer ellátottságára és annak jövőbeli árazására vonatkozólag. -
#8521
Petykemano
veterán
Petykemano
veterán
TSMC 2022Q4 pénzügyi adatok
- 2022Q4-ben a TSMC még nyerőben volt. De már 6.8%-kal kevesebb wafermegmunkálást szállított le, mint Q3-ban
- az N5 határozottan átvette a fő bevételi forrás szerepét
- a high performance computing átvette az elsődleges bevételi forrás szerepét az okostelefonoktól
- N3 2023 második felétől lesz számottevő. Vagyis talán szeptemberben várható egy új Apple lapkával szerelt készülék.Ez nem a beszámoló része, de iparági híresztelések szerint
- az N5 gyártókapacitás kihasználtsága 2023Q1-ben 70%-ra esik [link]
- az N7/N6 kihasználtsága pedig 40-50% alá [link] [link]Utóbbi tulajdonképpen megmagyarázza, miért érkezik relatív hamar a relatíve új gyártástechnológiának számító N4-en gyártott Phoenix Point. Azt is, hogy miért lehetett relatív hamar akciózni a Zen4 CPU-kat és miért jön szintén relatív hamar a mégolcsóbb non-X verzió.
Kiváncsi vagyok ebből mi csorog le. Egyrészt most aztán nem kéne volumenkorlátnak problémának lennie atekintetben, hogy az AMD különböző termékekkel piacot tudjon szerezni - ide értve az OEMeket és a GPU-kat is. Másrészt, hogy a wafer árak fognak-e csökkenni és az le fog-e csorogni a termékek áraiba.
-
#8520
Petykemano
veterán
Petykemano
veterán
Ez nagyon jó:
Memory Latency Data - CPU&GPU -
#8519
Petykemano
veterán
hokuszpk
#8518
Petykemano
veterán
válasz
hokuszpk
#8518
üzenetére
There are three modes the chips can run in. One will be that there can be HBM Only, where no DIMM slots are populated. That limits memory capacity to 64GB per CPU but saves the power and cost of DDR5 as an offset. The HBM Flat mode treats HBM seperate from DDR memory giving a fast and a slower tier of memory. Finally, there is HBM Caching mode where data is cached in the HBM memory and that is transparent to the host. [link]
-
#8517
Petykemano
veterán
Petykemano
veterán
7000X3D rajt: Február 14
[link] -
#8516
Petykemano
veterán
Petykemano
veterán
Megjelent a Sapphire Rapids.
Szép előrelépés az Ice Lake procikhoz képest.
Ha időben megérkezik, akkor a Milannál jobb lett volna, de a Genoa-t - a ML funckiókon kívül - nem tudta megelőzni. A HBM-es változat persze nyilván specifikus, mint a V-cache. -
#8515
Petykemano
veterán
Petykemano
veterán
Megjelentek a nemX-es procik tesztjei.
Tök jók.
Persze az X-es procik jelenlegi áraihoz képest nem ütnek akkorát.Továbbra is úgy vélem, egy 7600X3D lenne a legütősebb cucc.
-
#8514
Petykemano
veterán
Petykemano
veterán
AMD EPYC 9754 128C Bergamo (Zen 4c)
L2 1MB Per Core
L3 256 MB
[link] -
#8513
Petykemano
veterán
paprobert
#8509
Petykemano
veterán
válasz
paprobert
#8509
üzenetére
Ha igaz, amiket mond Abu az N6-ról, higy milyen olcsó már, akkor nem hiszem, hogy lenne értelme GPU-t gyártani 14nm-en, hiszen a kártya árának legnagyobb része profit, meg vram és egyebek.
Ráadásul a Samsung nem annyira jó frekvenciában.
Ami miatt érdemes lehet a samsunghoz menni, az a 3GAA, mert azzal újra csökken az SRAM sűrűség.
v-cache chipleteket gyártani jó lehet.Persze 14nm-ről volt szó.
-
#8508
Petykemano
veterán
Petykemano
veterán
Mi300

[link]Én eddig azt hittem, hogy a HBM3-ak közötti apró négyzet alakú lapkák a CPU lapkák. Tévedtem.
A cikk szerint 9db 5nm-es és 4db 6nm-es lapkából áll
Ebben nyilván nincs benne a HBM3A cikk szerint a képről az olvasható le, hogy 6db egyforma gpu chipletből áll (balra és fönt), valamint 2db CCD-ből és egy 5nm-es IOD-ból (jobbra lent)
Az az IOD jó nagy, nem tudom, mi a célja.A képen én csak 4x4 CPU magnak látszó dolgot látok. Csak az lehet, hogy ez valójában zen4c. Vagy hogy rossz a blokk diagram.
Az a fura, hogy a 6db GCD és a 2CCd + IOD elvákasztásai sehol sem látszanak a tényleges terméken.
Ez arra utal, higy a 4db N6-os lapka van felül. És mi.mást tartalmazhatna, mint gagantikus mennyiségű v-cache-t és esetleg a memóriavezérlőt?
-
#8505
Petykemano
veterán
Petykemano
veterán
"AMD Reportedly Eyes Samsung Chip Fab Deal in Dual-Source Strategy
AMD orders 14nm chips from Samsung Foundry."Ez fura. Miért most?
Azt hittem, a Mendocino vált minden korábbi lowend chipet. Az se kifejezetten új technológia - zen2. Tényleg van még igény 14nm-es zen1 + Vega lapkákra akkora mennyiségben, hogy a samsungot is be kell vonni?
Nemáá...Vajon mi lehet?
Még több IOD a ma már olcsónak számító AM4 zen3-hoz?
14nm-es (aktív) interposer?
Vagy nem is a 14nm-es node érdekli az AmD-t?
Csak a szokásos kacsa, ami évente kétszer előkerül? -
#8502
Petykemano
veterán
Petykemano
veterán
Ryan Smith információ szerint a Phoenix 178mm2 [link]
25 milliárd tranyó 178mm2 = 145Mtr/mm2
Az egész jó.
nekem szemre nagyobbnak tűnt.Ez olyan 250-300 jó példány lehet / wafer. Az mondjuk Abu $35000-os N5 költségével számolva $120 / lapka
Ha csak a felével számolunk, akkor $60 -
#8494
Petykemano
veterán
Csokissütis
#8493
Petykemano
veterán
válasz
 Csokissütis
#8493
üzenetére
Csokissütis
#8493
üzenetére
X3D.t talán nem.
De a nagyteljesítményű Dragon Range-re a gamer notebookok felől a Phoenixre a tucattermékek irányából lehet nagy a kereslet. A mobil szépen felzárkózott.Ezzel együtt a volumennel szerintem is lehet probléma.
-
#8490
Petykemano
veterán
Petykemano
veterán
Mi300
-
#8488
Petykemano
veterán
Petykemano
veterán
-
#8483
Petykemano
veterán
HSM
#8482
Petykemano
veterán
> Óriási ziccer kihagyva a papíron jobban mutató specifikációk kedvéért.
Nem biztos, hogy ezt a kérdést a két CCD fölött ülve hozták meg.
Arra gondolok, hogy valószínűleg a v-cache-sel szerelt CCD a Genoa-X-hez készülő sorozatok selejtje - fogyasztás alapján. Nagy szivárgással rendelkező a legmagasabb frekvenciát elérni képes CCD-k a közelébe se kerülnek a V-cache-nek. Ez lehet a magyarázata annak, hogy miért csak 1 CCD kap v-cache-t: mert valószínűleg nem 5.3Ghz lenne a turbó, hanem ugyanúgy 5Ghz (esetleg 5.1Ghz), mint az 7800X3D esetén.
2db ilyen max 5Ghz-es CCD azokban az esetekben, amikor a többlet cache nem hasznosul, viszont jelentős teljesítménycsökkenést eredményez. Persze legalább egységes, nem valami Thread director jóságától függ. -
#8479
Petykemano
veterán
HSM
#8477
Petykemano
veterán
"AMD is working with Microsoft on Windows optimizations that will work in tandem with a new AMD chipset driver to identify games that prefer the increased L3 cache capacity and pin them into the CCD with the stacked cache. Other games that prefer higher frequencies more than increased L3 cache will be pinned into the bare CCD. AMD says that the bare chiplet can access the stacked L3 cache in the adjacent chiplet, but this isn’t optimal and will be rare. Yes, the chip with the extra L3 cache will run games at a slower speed, but most games don’t operate at peak clock rates, so you should still get a huge performance benefit."
[link] -
#8478
Petykemano
veterán
HSM
#8477
Petykemano
veterán
"Ellenben, szerintem ez egy jó megoldása lehet a "hybrid" CPU-nak, ha az erősebb mag kapja a nagyobb L3-at. Így van 6-8 igen erős mag sok L3-al, és van mellé 6-8 nem sokkal gyengébb, adott esetben alacsonyabb órajelen járatott, energiatakarékosabbra hangolt."
Ezt nem vitatom. Szerintem is jobb lenne.
De akkor mivel magyarázod, hogy a 2 CCD-s példányok nem szenvednek frekvencia regressziót, míg az 7800X3D a 7700X-hez képest igen? -
#8473
Petykemano
veterán
Petykemano
veterán
Ez egy jó kedélyű, de azért kissé szűkszavú előadés volt.
Mármint én hiányoltam egy kicsit hosszasabb ismertést a termékekről, teljesítményről.Mindenesetre pár dolog kiderült
- a Phoenix úgy tűnik, valóban monolitikus. És ha jól láttam, annyira nem is kicsi. Nagyjából annyival lesz jobb az IGP, amennyit hozzáad az RDNA3 az RDNA2-höz képest (vs Rembrandt) és amennyivel magasabb frekvenciát biztosít a N4 vs N6
- a Dragon Range ránézésre sajnos semmilyen egzotikus kapcsolódást nem használ. Ugyanaz, mint a desktop. Az az elképzelésem, hogy a mobil zen4 egy külön lapka infinity intinity.chiplet link kapcsolódéssal téves volt.
- az X3D cpuk esetén minden sku csak egy CCD-re kap.bővítményt. a.cache méret így jön ki. És megmaradt a frekvencia regresszió is.
Az 5800X3D esetében ez egyértelműen látható a specifikációból. A 2 CCD-vel rendelkező példényok azért nem, mert a másik CCD nem kap v-cache-t és az továbbra is az eredeti frekvencián pörög. Valószínűleg a v-cache eleve az alacsonyabb frekvenciás CCD-re kerül.
Ez egy elég érdekes "hybrid" eredményt ad.
Ami persze logikus. Aminek hasznos a cache,.az fusson azon a CCD-n, Aminek meg nem, az meg fusson a magas frekvenciás magokon.
De hát ezt mi fogja majd megállapítani?A Mi300 elég jól hangzik.
-
#8451
Petykemano
veterán
S_x96x_S
#8450
Petykemano
veterán
válasz
S_x96x_S
#8450
üzenetére
> 05: 7950X3D ~ $999 ??
Gondolkodom.
Nekem az az érzésem, hogy a $999 túl sok. Értem, hogy a $999 az a prémiumság felára. Akkor lehet szerintem ennyi, ha az AMD valójában nem akarja eladni ezen a piacon. Tehát nem zárom ki teljes mértékben, de értelmes termékhez ez az ár túl magas.
A 7950X már közel $500-ért megkapható.
Ahhoz képest a frekvencia regresszió nélküli 7950X3D kb 20%-os többletet nyújthat a játékokban. Ez arra elég, hogy meggyőzően maga mögé utasítsa az 13900K-t - úgy, hogy nem kell hozzá szupergyors (szuperdrága) DDR5 ram. Ez szerintem kb $699-799 árat indokolna.Persze lehetnek módosító tényezők:
- a 16 magos változat esetleg használható bizonyos számítási feladatok jelentős gyorsítására is, mint azt láttuk az előző generációs Milan-X esetében is. De ez azért az az eset, amikor az AMD nem kifejezetten gamereknek szánja a portékát, tehát nem csak azt kell nézni, hogy ott mit hoz. Ezzel valahol érthető lenne, de csalódást keltene a közönségben.
- Ha mondjuk nem 20%-ot hoz, hanem 30%-ot, mert valamit javítottak a működésén az órajel regresszión kívül. (Pl ilyen fejlesztés lehet valamilyen prefetcher victim jelleg helyett, vagy ha CCD-nként már két szintes lenne, ami egyébként talán épp 5-8%-ot tenne hozzá) Az már egy generációs különbség lenne az Intellel szemben és nevetségessé tenné a 13900KS-t09: bergamo - 350W -ot eszik a 128mag ??
Én azt hallottam, hogy a Bergamo Zen4 magok esetén még alacsonyabb lesz a frekvencia. -
#8449
Petykemano
veterán
Petykemano
veterán
"Xillinx FPGA with >500MB off package SRAM at 9ns write latency!"
Ez meglepő, még csak nem is 2.5d,3d
-
#8448
Petykemano
veterán
Yutani
#8447
Petykemano
veterán
Igen...
Ha csak úgy szűkülne a piac, logikusan hangozna az áremelés.
De két éven keresztül úgy drágult minden (chip & co), hogy közben azt mondták keresleti sokk van, és talán csak 2025-re enyhülhet. Ehelyett most enyhül a kereslet - Számomra, mint megfigyelőnek az volna logikus, ha erre csökkenne az elmúlt 2 évben tapasztalt keresleti sokkra inflálódott ár.
Most vagy az van, h a tsmc még így is tele van, csak csökkent a sorbanállás, vagy 19-re húznak lapot.
























Új hozzászólás Aktív témák

- DJI Mavic 2 Pro drón +koffer +szűrők +landing pad +SD kártya
- Oneplus Pad lite 128 Gb Új, bontatlan
- Latitude 7440 27% 14" FHD+ IPS i7-1365U 32GB 1TB NVMe magyar vbill ujjlolv gar
- OnePlus 12 256Gb 1 éves, 2027. szeptemberig gaarnciális MAGYAR vásárlás
- Samsung Galaxy S24 256GB, Kártyafüggetlen, 1 Év Garanciával
- 137 - Lenovo Legion Pro 7 (16IRX9H) - Intel Core i9-14900HX, RTX 4080 - 4 ÉV GARANCIA!
- GYÖNYÖRŰ iPhone 12 mini 128GB Blue-1 ÉV GARANCIA - Kártyafüggetlen, MS3415 94% Akkumulátor
- Azonnali készpénzes nVidia RTX 4000 sorozat videokártya felvásárlás személyesen / csomagküldéssel
- Samsung Galaxy A53 5G / 6/128GB / Kártyafüggetlen / 12 Hó Garancia
- Apple iPhone 14 Plus 256GB,Átlagos,Dobozával,12 hónap garanciával
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: ATW Internet Kft.
Város: Budapest