Hirdetés
- Samsung Galaxy A17 5G – megint 16
- Poco F8 Ultra – forrónaci
- Samsung Galaxy Watch5 Pro - kerek, de nem tekerek
- Örömkönnyek és üres kezek a TriFold startjánál
- Milyen robotporszívót vegyek karácsonyra? (2025)
- Töltő már van a Galaxy S26 Ultrához
- Milyen okostelefont vegyek?
- Bekerül az Apple Pay és Google Pay a Budapest GO alkalmazásba
- Samsung Galaxy Watch8 - Classic - Ultra 2025
- Vivo X300 - kicsiben jobban megéri
Új hozzászólás Aktív témák
-
-

mgoogyi
senior tag
válasz
 Tomi_78
#4256
üzenetére
Tomi_78
#4256
üzenetére
A pointernek és a LoadFromFile-nak nincs köze egymáshoz.
A pointer csak egy logikai memóriacím.A programod változói mind a memóriában vannak valahol.
Az, hogy valami hol van, azt elrakhatod egy pointerbe, mint pl. egy int * p;
Ebbe a p-be berakhatsz egy memóriacímet és utána azt tudod, hogy azon a memóriacímen - ami a p-ben van - van egy int értéked, azaz 4 byte-od egymás után.Az egyszerűség kedvéért 0-tól 1000-ig legyenek a lehetséges memóriacímek.
Amikor leírok egy olyat, hogy new int, akkor a programod a memóriából kér magának 4 byte-ot egymás után, ahol majd az integer-ed tartalma lesz és ebből a 4 byteből az elsőnek a címét visszaadja. (A másik 3 byte közvetlen utána van.)
Ezért tudod megtenni azt, hogy aint * p = new int;esetén a baloldalt ott van a p, ami értéket kap. Mégpedig ennek az 1. byte-nak a memóriában lévő sorszámát.Itt egy példakód megdebuggolva:
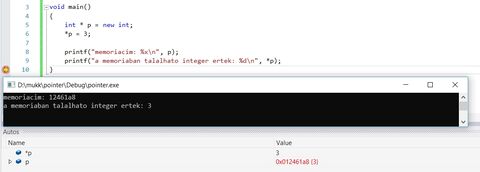
A programom a (hexadecimális) 12461a8-as byte-tól kezdve kapott összesen 4 byte-ot.
És erre a 4 byte-ra a 3-nak megfelelő adat lett beírva.Ez így világos?
Olvasd el sokszor, ha nem érted, elég fontos, hogy ez meglegyen. -
mgoogyi
senior tag
válasz
Tomi_78
#4252
üzenetére
AlakokKepe->LoadFromFile("alak\\alak_all.bmp");
kepei[0] = AlakokKepe;
kepei[2] = AlakokKepe;
AlakokKepe->LoadFromFile("alak\\alak_lep1.bmp");
kepei[1] = AlakokKepe;
AlakokKepe->LoadFromFile("alak\\alak_lep2.bmp");
kepei[3] = AlakokKepe;Anélkül, hogy érteném a teljes kódod, ez a rész biztosan rossz.
Az AlakokKepe egyetlen objektum pointere (memóriacíme).A memóriacím egy szám, ami eldől akkor, amikor a new neked helyet foglal a memóriában:
Graphics::TBitmap *AlakokKepe = new Graphics::TBitmap;
És innentől kezdve ez az érték nem változik.A kepei nevű ugyanilyen pointereket tároló tömbbe berakod ugyanazt a számértéket(pointert/memóriacímet) minden indexre.
Teljesen mindegy, hogy mit csinálsz közben a LoadFromFile függvénnyel.Az AlakokKepe változóra nincs szükséged. Első körben csináld azt, hogy minden alakok elemre ([0], [1], [2], stb.) a benne lévő kepe adattagot külön külön létrehozod
= new Graphics::TBitmap;hívással és ezeken az alakok[ 0/1/2/.. ] . kepe objektumokon hívod meg a LoadFromFile-t.Azt is megeteheted, hogy nem pointert használsz:
Graphics::TBitmap* kepe;->Graphics::TBitmap kepe;
és akkor nem kell new sem. -
mgoogyi
senior tag
válasz
Tomi_78
#4247
üzenetére
Nem vagyok otthon a Borland TTimer témában, de egy gyors google keresésnél ezt találtam:
https://programmersheaven.com/discussion/357230/creating-component-with-timer-in-it
Ez alapján:
Timer = new TTimer(this);
Timer->Interval = 5;
Timer->OnTimer = (TNotifyEvent) &alakmozgatas;
Timer->Enabled = true;
void __fastcall alakmozgatas(TComponent* Sender)
{
..... Do some stuff .....
} -
#4245
mgoogyi
senior tag
Ron Swanson
#4243
mgoogyi
senior tag
válasz
 Ron Swanson
#4243
üzenetére
Ron Swanson
#4243
üzenetére
A mohó mintáshoz hasonló lesz a megoldás, sokat segített volna, ha az elején ismerem már azt a példafeladatot.
Annak a pdf-je többet mond, mint a kódja.
Szerintem távozási idő szerint kell rendezni a vendégeket, venni az elsőt és mindenki, akivel ő találkozik, azzal nem kell foglalkozni, mert az nem lehet jobb nála. Ez a halmaz kiesik és ugyanezt ismételni, amíg el nem fogynak a vendégek.Egyébként neked az alapokat kéne rendberakni, nem algoritmusokon görcsölni.
Majd nekifutok még1x, ha lesz kedvem. -
mgoogyi
senior tag
A screenshotodban nem pointered van, hanem normál objektumod.
Gondolom a listáddal is ugyanaz a helyzet.Ezzel az a baj, ha csinász egy ilyet, hogy:
Bolygo b;
Egitest e;
e = b; // az EgitestHozzaad-nál gyakorlatilag ezt csinálodEzesetben az "e" egy ledarált Egitest méretű változó lesz, amit a "b" égitestből örökölt részei adnak.
Ez az egész castolás téma akkor nyerhet értelmet, ha pointert vagy ref-et castolsz.
Látom c# háttered van.
C++-ban a normál értékadás by value megy összetett típusokra is, amit pl. az EgitestHozzaad függvény bemenő paraméternél történik. (Kb. mint a struct c#-ban)
Ez azt jelenti, hogy mindig egy másolat változóba megy az adat, amibe vagy copy konstruktorral vagy = operatorral kerül be az adat.A a = b; // copy ctor
a = b; // = operatorHa ki akarod használni a polimorfizmust, akkor vagy referenciákkal vagy pointerekkel kell dolgoznod.
A * a / A & aMiért akarsz visszacastolni bolygóra? Nem azért tartod közös kollekcióban az objektumokat, hogy mind ugyanúgy kezelhesd a közös interfaceükön keresztül?
-
mgoogyi
senior tag
válasz
 dabadab
#4197
üzenetére
dabadab
#4197
üzenetére
Egyetértek veletek, hogy az OOP-t nem tanítják meg rendesen.
Viszont a kérdező srácnak még lehet korai túlzottan ebbe belemenni, egyelőre szerintem ott tart, hogy a nagyon alap dolgok meglegyenek. Amíg egy egyszerű téglalap reprezentációja ennyi magyarázatra szorul, az nekem azt mutatja, hogy nagyon keveset kódolt még.Visszatérve az OOP-re, nekem a láthatóságokkal kapcsolatban zavar pl, hogy mennyire nem tanítják(és nekem sem tanították), hogy mi a valódi haszna annak, hogy semmit sem szabad feleslegesen publicon hagyni.
Annyit tudnak, hogyha valami private, akkor az nem látszik kívülről, de hogy az miért jó, arra már semmi ötletük nincs.
És hát azért nem tanítják, mert jellemzően a gyakorlatvezető sem tudja. -
mgoogyi
senior tag
válasz
 cadtamas
#4193
üzenetére
cadtamas
#4193
üzenetére
Az implementáció mondja meg, hogy mit csinálnak a függvények. Anélkül nincs program, csak a függvények fejlécei. Az implementációt találod a cpp fileban.
A .h-ban megmondod, hogy ilyen-olyan függvényeid vannak az osztályban, meg ilye-olyan adattagjaid.
A .cpp-ben meg elvégzed az érdemi munkát, azaz kifejted(implementálod), hogy mit csinál a konstruktor, mit csinál a settop és a többi függvény. Ha ezt nem tennéd meg, a program futásakor nem lenne semmi a függvényhívások mögött.A privát változókat az osztály saját függvényei látják, egyedül előttük nem rejtett. Ha legalább ők nem látnák, akkor semmi értelme nem lenne a privátnak.
Ezek az osztály saját belső állapotát tükroző változók, nem lokálisak. A lokálisnak látnád a deklarációját a függvény elején, pl. int itsTop;Az osztályra meg úgy gondolj, mint egy olyan valamire, aminek a belső változói adják az állapotát és a függvények pedig azt módosítják vagy azt felhasználva csinálnak valamit.
Amikor a konstruktor lefut, akkor éppen frissen létrejött az osztályodból egy új objektum. A konstruktor a kezdeti állapotát állítja be az objektumodnak. Ezután az objektumon az osztály minden publikus függvényét meghívhatod, ami konkrétan azon az objektumon fog dolgozni. Egy osztályból annyi objektumot csinálsz(példány példányosítasz), amennyit akarsz. Mindegyiknek meglesz a saját belső független állapota, saját itsTop, itsRight stb. belső értékekkel.
-
mgoogyi
senior tag
válasz
cadtamas
#4190
üzenetére
//Ez elvileg az implementáció, amit nem taglal a könyv, hogy miért kell és később miért nem használjuk semmire.
-> Az implementáció írja le a dolgok működését, a .h-ban meg azt látod, hogy mit tudsz csinálni majd ezen az osztályon//ide kellene gondolom a destruktor, ami azért jó, mert memóriát szabadít fel?
-> vagy egyéb resource-öket enged el, de az osztályodban nincs ilyen. Akkor fogsz látni destruktort, ha az osztályodban lesz olyan, hogy "new"setupperleft:
//módosítja a JobbFelső pont Y értékét, de miért???
-> azért, mert ez egy téglalap, ha a bal felső sarkát feljebb húzod, a jobb felsőnek is követnie kell//a test felső vonalát határozza meg, de nem ez a dolga!!!
-> dehogynem, az itstop értékét, azaz mi a legnagyobb Y értéke a téglalapnak, módosítani kell, amikor valamelyik sarkát arrébb teszedsetTop(int top):
//beállítja a test felső vonalát. Ugyanazt mint a setUpperLeft() függvény. MIÉRT???
-> azért, mert ez a függvény a téglalap felső oldalát teszi arrébb, amivel együtt mozognak a felső sarkai -
mgoogyi
senior tag
-
#4175
mgoogyi
senior tag
Ron Swanson
#4174
mgoogyi
senior tag
válasz
Ron Swanson
#4174
üzenetére
Rendezésből a buborékrendezést szokták elsőnek tanítani, de az O(n^2)-es, nem leszel vele előrébb.
Ez a sort(...) gyorsrendezést használ, nyugodtan használd.
A feladat megoldását meg nem tanultad órán, azt magadnak kéne kitalálnod, ezzel fejlődsz.
Értsd meg a beszúrt kódot, próbálgasd. Ha azt érted az utolsó betűig, meg tudod majd oldani a saját feladatod is. -
#4173
mgoogyi
senior tag
Ron Swanson
#4172
mgoogyi
senior tag
válasz
Ron Swanson
#4172
üzenetére
Melyik része nem sikerül?
A megértés?Amit linkelt Drizzt fórumtárs, az pont ezt oldja meg:
#include<iostream>
#include<algorithm>
using namespace std;
void findMaxGuests(int arrl[], int exit[], int n)
{
// Sort arrival and exit arrays
sort(arrl, arrl+n);
sort(exit, exit+n);
// guests_in indicates number of guests at a time
int guests_in = 1, max_guests = 1, time = arrl[0];
int i = 1, j = 0;
// Similar to merge in merge sort to process
// all events in sorted order
while (i < n && j < n)
{
// If next event in sorted order is arrival,
// increment count of guests
if (arrl[i] <= exit[j])
{
guests_in++;
// Update max_guests if needed
if (guests_in > max_guests)
{
max_guests = guests_in;
time = arrl[i];
}
i++; //increment index of arrival array
}
else // If event is exit, decrement count
{ // of guests.
guests_in--;
j++;
}
}
cout << "Maximum Number of Guests = " << max_guests
<< " at time " << time;
}Az
int arrl[]az érkezési időpontok tömbje, aint exit[]pedig a távozási időpontok tömbbje.Ez rendezi le neked ezt a két tömböt gyorsrendezéssel O(N*logN) időben:
sort(arrl, arrl+n);
sort(exit, exit+n);A while ciklus pedig végigmegy a két tömbbön úgy, hogy hol az egyiket lépteti, hol a másikat.
Az"i" az érkezés indexe, a "j" a távozásé.Annyi, hogy ennek a programnak a kimenete az, hogy melyik időpontban voltak a legtöbben és nem az, hogy melyik vendég találkozott a legtöbb másikkal, de a két probléma technikailag szinte azonos.
Ha valami nem világos, kérdezz.
Az eredeti kódoddal a legfőbb baj, hogy volt benne egy egymásba ágyazott for ciklus pár, ami N darab vendég esetén N*N-nel arányos mennyiségű műveletet végez. Ezt hívják O(n^2)-nek és emiatt van az, hogy nagy N-re már túl sok ideig fut a programod. Ugye N=10-nél a a valahány 100 művelet nem gáz, de N=1000-nél már valahány millióról beszélünk. -
#4166
mgoogyi
senior tag
Ron Swanson
#4165
mgoogyi
senior tag
válasz
Ron Swanson
#4165
üzenetére
Pontos feladatleírás?
for (i = 1; i < vendegek.size(); i++) {
Itt 0-tól kéne indulni, az első vendég is lehet a megoldás.
A TVendegek osztályt átnevezném Vendeg-re, mert az egy darab vendég szerintem.A feltöltésnél add át a vektornak a ctor-ba a méretét, hogy a push_back-nél elkerüld az átméretezést.
Ha kevés benne a hely, újrafoglal magának helyet és másolgat. De várhatóan nem ezen múlik.A kódodnál viszont valszeg a dupla for ciklusnál lehet fogni sokat, az teszi négyzetessé a futási idejét a bemenet méretétől függően. Ez a feladat gyakorlatilag annyi, hogy melyik zárt intervallumnak van a legtöbb metszete a többivel.
Én valami olyasmit csinálnák, hogy rendezném a vendégeket érkezési sorrendben (/távozásiban ) és végigmennék rajtuk lineárisan és jegyezném, hogy most jött valaki, most elment, és azt nézném, hogy mikor voltak a legtöbben.
Oké, most esestt le. Nem kell a vendégeket rendezni, külön az érkezési idejüket egy tömbbe teszed, külön a távozásit és párhuzamosan haladsz a kettőn két külön indexszel. Ha a soron követő két szám között az érkezési <=, akkor növelsz a számlálón, ha meg nem, akkor csökkentesz. Ennek a számlálónak a maximumát keresed és egy vendéget, aki akkor ott volt.
Ez már elég erős tipp szerintem. Lényeg, hogy az egymásba ágyazott ciklusokkal nem fogod tudod megoldani elég gyorsan, csak lineárisan mehetsz végig a vendégek dolgain. -
mgoogyi
senior tag
válasz
 Teasüti
#4155
üzenetére
Teasüti
#4155
üzenetére
Amit lehet a stacken jobb tartani(gyorsabb, nem kell delete), a nagy méretű adatot meg heap-en(van neki hely gazdagon).
A new+delete párra meg vannak osztályok, amikbe becsomagolva megkapod az eltakarítást.
std::vector a dinamikus tömbhöz, std::unique_ptr, std::auto_ptr egyéb mutatóhoz.
Ezek az osztályok a delete-et úgy oldják meg, hogy a destruktorukban meghívódik az általuk tárolt pointerre a delete.
És ezeket a pointer "wrapper"-eket pedig stack-en tartod valahol és amikor elhagyod a scope-ot, szépen lefut a destruktor és magától felszabadul a memória.
Ez azért nagyon fontos, mert minden programozó hibázik és nem igazán függ a hibázás gyakorisága attól, hogy mióta űzöd a mesterséget. Ezzel védjük magunkat a memory leak-től.A vector persze elsődlegesen nem pointer wrapper, arra találták ki, hogy nagyon kényelmesen legyen egy bármikor átméretezhető tömböd. A belsejében egy dinamikus tömb van.
-
mgoogyi
senior tag
válasz
 jattila48
#4146
üzenetére
jattila48
#4146
üzenetére
Ezzel nem mondtál semmi újat. A gyakorlati jelentőség = hogyan használod a kódban.
Évekig dolgoztam c++-ban, csak a saját gyakorlati nevezéktanomban változónak hívom a konstansokat is (legalábbis a const int-eket pl). Viszont a #define-olt cuccokat viszont konstansnak hívom.
A const int nekem egy olyan változó, amin nem tehetek meg tetszőleges műveletet.És szerintem a kódodtól függ, hogy minden tekintetben konstans lesz vagy sem.
Ugyanis a kódodhoz hozzácsapva azt, hogy&haromsimán megy, kiírathatod, és így már igazi változód lesz.A const-ot egy optimalizációs tippnek tekintem a fordító számára.
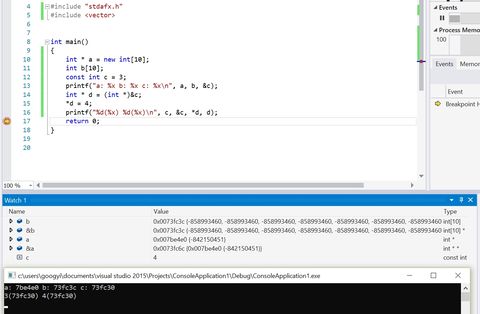
Ez nyilván péklapáttal tarkónbaszós kód, de példának jó.
-
mgoogyi
senior tag
válasz
jattila48
#4143
üzenetére
Ok, főleg nevezéktanról beszélgetünk gyakorlatilag.
Én abból indulok ki, ahogy angolul hívni szoktunk dolgokat. Magyar szakirodalmat csak egyetemen olvastam utoljára kb.[https://msdn.microsoft.com/hu-hu/library/07x6b05d.aspx?f=255&MSPPError=-2147217396]
Pl:
"The const keyword specifies that a variable's value is constant and tells the compiler to prevent the programmer from modifying it."" you must declare your const variable as"
const int harom=3;Szóval ez itt nekem egy konstants változó. Hülyén hangzik valóban.
-
mgoogyi
senior tag
válasz
jattila48
#4141
üzenetére
"Nem, nem lehet a heapen tömb. Az nem tömb lesz, hanem dinamikusan foglalt memória"
Lehet én vagyok a retardált, de nekem a tömb = összefüggő memóriaterület egy adott típusra.
Szóval nekem van olyan, hogy statikusan allokált array és dinamikusan allokált array.https://msdn.microsoft.com/hu-hu/library/kewsb8ba.aspx?f=255&MSPPError=-2147217396
Az msdn meg le mer írni ilyet, hogy "When allocating an array using the new operator"?
"Ahogy írtam, a t NEM változó, hanem konstans és ez a lényeg."
int * a = new int[10];
int b[10];Pusztán ránézve a kódra én "a"-ra és "b"-re is változóként(előbbire pointer típusú változóként, utóbbira tömb típusúként) fogok hivatkozni. Utóbbi konstans és nincs mögötte valódi változó? Pont nem érdekel, nem látom a gyakorlati jelentőségét. Lehet ez rossz berögzültség, soha egyszer nem volt még hátrányom belőle a munkám során.
-
mgoogyi
senior tag
válasz
jattila48
#4139
üzenetére
Ja értem, hogy mire gondolsz, én gyakorlatiasabban közelítem a kérdést.
int t[10] esetén a t a gyakorlatban úgy viselkedik, mint egy konstans pointer. Amikor a tömbről beszélek a kódban, akkor én a t-re gondolok, mint változóra, márpedig ez pontosan a 0. elem címe.
Az a konstans cím, amiről beszélsz, az maga a t változó tartalma. Annyit tud egy pointerhez képest, hogy a típusából kifolyólag tud arról, hogy hány elemű, azaz nem int * hanem int[10] típusú. De ettől még értékként a 0. elem címe van benne. És igen, valóban nem pointer, de mégis pontosan ugyanúgy viselkedik.Másrészt nem csak a stacken lehet a tömbünk, hanem a heapen is new-val foglalva, akkor meg direktbe egy int *-ba toljuk be a 0. elem címét és azzal a pointerrel is pont azt fogod csinálni, mint a stack-en foglalt t-vel.
Az assemblys részt elolvasom megint, amit írtál, abban nem vagyok otthon. Egyetemen meglehetősen félvállról vettem, így ennyi is maradt meg belőle. Egyébként aki most ismerkedik a C++-szal, annak lehet inkább riasztó, mint segítség.
-
mgoogyi
senior tag
válasz
Teasüti
#4135
üzenetére
Igen, így van, a tömböt is pointerként kezeled. Gyakorlatilag a 0. elemére mutató pointer van a változóban értékként.
A kérdésedre a válasz igen, mindig más memóriaterületen kapsz egy új összefüggő memóriaterületet az új tömbödnek. A pointert írasd ki és látod, hogy mindig más értéket kap. Ez a logikai címe a kezdeti memóriacellának (a programod csak a memória egy számára logikailag elkülönített részét látja).
A régi tömb ugyanúgy meglesz az előző ciklusodból, csak a címe már nem lesz meg és anélkül nehéz felszabadítani.
Csináld ciklus belsejében simán, amit írtál. Ha jó sok kört fut a ciklusod, megzabálja a géped memóriáját.
Azért figyelj arra, hogy ne zabálja meg az összeset, kevés elemű int tömböt foglalj le 1000-szer ciklusban, kísérletnek elég. -
mgoogyi
senior tag
válasz
Teasüti
#4132
üzenetére
A new meg nem new között az a különbség, hogy a new-val a heap-en foglalsz memóriát, new nélkül meg a stack-en. (itt nem erre a nem szabványos dologra gondolok:
int p [I]= {};)
Ez utóbbi elég limitált tud lenni, ha majd egyszer írsz rekurzív(önmagát hívó) függvényt, belefuthatsz.
Ezt hívják stackoverflow-nak. Olvass utána, hogy mi az a heap és mi az a stack.
Egyébként paraméterezett méretű tömböt new nélkül nehéz lértehozni.A new (new []) esetében egy pointer-t kapsz vissza és a te feladatod ezt eltakarítani delete-tel ( delete []).
Azért, hogy ezt ne felejtsd el, javasolt olyan osztályokat használni, amik megteszik ezt helyetted.
A vector meghívja helyetted a new[]-t és a delete[]-t, menet közben át is méretezi a benne lévő array-t.
Kényelmessé és biztonságossá teszi a tömbkezelést.
A unique_ptr pedig általánosságban jó arra, hogy egy objektum felszabadításával ne kelljen foglalkozni.Ha ezeket nem használod és elfelejteted a delete-et, akkor keresheted, hogy miért növekszik a progid memóriahasználata (memóriaszivárgás).
-
mgoogyi
senior tag
Szia,
Próbáld lényegretörően feltenni itt a kérdéseid, miután már úgy érzed, hogy egy adott dologgal nem jutottál magadtól előre. Én csináltam skype-pal, de ha annyit kérek, hogy nekem megérje, neked nem fogja.
A legtöbbet az számít, hogy mennyi időt ölsz a dologba. Csak azzal, hogy egyszer vagy kétszer elmondanak valamit, még nem fogod tudni hatékonyan alkalmazni. Rengeteg gyakorlásra van szükség és az egyetemek is ebben a szellemben oktatják. -
mgoogyi
senior tag
válasz
 #74220800
#3995
üzenetére
#74220800
#3995
üzenetére
Visual Studio Express 2013, de debuggolni más ide-ben is lehet.
Ez nem elég a végére?
if (v[i].size() > 0)cout << v[i][0] << " "; else cout << "- ";Vagy azokra az indexekre beírsz egy -1-et, ahol nem gyűlt ki a k=4 szumma?
A későbbiekben pedig a -1 jelezné, hogy attól az indextől kezdve nem lehet kihozni a szumma>=4-et.Nem értem ezt az előre definiálós problémádat. A v vektor sorindexek jelentése, hogy hanyadik számtól kezdve adod össze a számokat. Ezen belül a 0. index jelzi, hogy hány darab számot kell összeadj, utána meg be vannak írkálva, hogy ezek mely indexű számok az "a" vektorban. Ami mondjuk bármikor számítható a sorindexből és a darabszámból, én valszeg nem tárolnám el.
Mi a kimenet, ami szeretnél?
-
#3983
mgoogyi
senior tag
m.zmrzlina
#3980
mgoogyi
senior tag
válasz
 m.zmrzlina
#3980
üzenetére
m.zmrzlina
#3980
üzenetére
Ha csak egyszer hívnád meg azt a függvényt, akkor semmi értelme.
A többször használt kódot szokásos függvénybe kirakni. -
#3930
mgoogyi
senior tag
m.zmrzlina
#3929
mgoogyi
senior tag
válasz
m.zmrzlina
#3929
üzenetére
3. az if, amiben van 4 isGood, kiegészíted még 4-gyel ((-1,-1) (-1,+1) (+1,+1) (+1,-1))
Akkor a feladat gyakorlatilag átültethető arra, hogy csinálsz egy ugyanekkora 0-kal feltöltött mátrixot és abban a kezdőponttól indulva minden irányban elkezdessz 1-eseket rakni, amíg tudsz olyan mezőkön haladni, hogy csak 0-ás szomszédok vannak. Kb mintha vizet engednél a mátrixba és csak a keresett elemek adnák ki a tó medrét.
Pl:
void Flood (int x, int y)
{
if (floodMatrix[x][y] == 0 && összes szomszéd + (x,y) isGood )
{
floodMatrix[x][y] = 1;
Flood() összes szomszédra
}
}Mire végez, addigra a floodMatrixban ott lesznek a megoldásaid.
-
mgoogyi
senior tag
Ha csinálsz szándékosan egy szintaktikai hibát, akkor minden sorra igaz ez a sorszám tévedés?
Hátha ki lehetne találni, hogy melyik sortól hülyül meg a sorszám.
(Az első gondolatom vmi rejtett karakter a kódban, amitől valamiért meghülyül a fordídtó.)Meglehetősen ezoterikus hibának látszik.
-
mgoogyi
senior tag
válasz
 nonsen5e
#3826
üzenetére
nonsen5e
#3826
üzenetére
Tudsz feltenni netre egy problémás minimál csomagot?
A leírásodból halvány fingom sincs, hogy mi lehet gond + nem tudok róla, hogy a .h és .hpp fileok között bármi különbség kéne legyen a kiterjesztésen kívül."rögtön különböző hibákra hivatkozik"
Konkrétan?"operator<< multiple deklarációra hivatkozik"
nem include-olod duplán ugyanazt véletlenül? (akár közvetetten is) -
mgoogyi
senior tag
Debug módban indítva breakpointoknál meg tudod fogni a progi futását. Katt a sor elé és megjelenik egy piros pötty. Ha megállt a breakpointnál: F5 hagyja továbbfutni a progit, F10 egy sort lép, F11 belelép a hívandó függvénybe. Amikor áll a cucc, meg tudod nézni a változók értékét is. Próbálkozz, menni fog.
-
mgoogyi
senior tag
válasz
 Hunmugli
#3797
üzenetére
Hunmugli
#3797
üzenetére
"Baloldalt egy char van, jobboldalt egy bit, ez nem fog menni".
A char egy 8 bites szám és jobb oldalt nem bit van, hanem egy másik 8 bites szám, aminek jellemzően egy adott bitje tér el a többitől. Innentől pedig az alap bitműveletek kellenek (és,vagy,xor,negálás)
Amit csinálsz, azt szokták flageknek hívni, minden bitnek megvan a saját jelentése.Nem kell túlgondolni az elképzelést:
1101 & 0010 = 0000 (bit ellenőrzés)
1101 | 0010 = 1111 (bit beállítás)Gyakorold valamennyit papíron, lehet az segít abban, hogy lásd, hogy melyik művelet mire jó.
Pl. 1-es bittel éselés az adott bit értékét fogja kiköpni, 0-ással(1011) az adott bitet állítod garantáltan nullára.A flagekre visszatérve: ilyesmit szoktak csinálni, hogy:
Option1 = 1 (001)
Option2 = 2 (010)
Option3 = 4 (100)Options = 101 esetén az option 1 és 3 van bekapcsolva.
Bár lehet, hogy te pontosan erre akarod használni."C bitjei balról jobbra vannak számozva, 0tól kezdődően 7ig. Function szerűen kéne"
Szerintem jobbról balra számozd a biteket, akkor a természetes bitsorrendet kapod és a 001 = 1-et jelent majd decimálisan, az 100 meg 4-et pl.
A 0-ás indexű bit a 2^0-át jelenti, az 1-es a 2^1, stb.stb.Ha kérdésed van bitekkel kapcsolatban, akkor kérdezz(akár privátban is rámírhatsz), ezzel relatíve sok gyakorlatom van.
-
mgoogyi
senior tag
válasz
 EQMontoya
#3613
üzenetére
EQMontoya
#3613
üzenetére
Értem mire gondolsz, de ez csak a pointerekre vonatkozó cache miss.
Az objektumok kapcsán annyi cache miss lesz, ahányat feleslegesen megnézünk, azaz set esetén O(log(N)), vektor esetén meg O(N).Ha csak a pointert elég használni a komparálásra, akkor teljesen igazad van, de nem látom, hogy ez milyen esetben van.
A fordító csak a szimbolúm nevét látja, nem?A kis elemszámra hol van algoritmikus overheadje a set-nek pointeren keresztüli elemkeresésnél?
(Mondjuk ez tök mellékes, mert úgyis elhanyagolható.) -
mgoogyi
senior tag
válasz
jattila48
#3610
üzenetére
Lehetséges, hogy nem tudom..
Nem az, amit leírtál? Egy tábla, ami tárolja a lefordítandó kód szimbólumait, mint változó, függvény, stb. és arra használod pl., hogy ellenőrizd, hogy az adott objektumra az adott scopeban lehet e egyáltalán hivatkozni.
A process kapcsán arra gondoltam, hogy valami gépi vagy köztes kódot generálsz, mikor mész a következő sorra a kódban és találkozol pl. egy szimbólumon végzett művelettel.
És elnézést, hogy beledumáltam (inkább ne tettem volna), nem vágom, hogy működnek a fordítóprogramok. -
mgoogyi
senior tag
válasz
jattila48
#3602
üzenetére
Tudom mi a szimbólumtábla, viszont nem tudom, hogy mi történik pontosan a "tárolt attribútumai szerint folytatni a fordítást" során. Különböző külső függőségei vannak a különböző objektumoknak a további feldolgozás szempontjából? Még mindig az van a fejemben, hogy minden objektumra lehetne egy Process-t hívni, ami kezelné az adott objektumot a típusának megfelelően, ami kaphat egy olyan külső függőséget, amin keresztül mindent megkaphat, amire esetleg szüksége van, vagy esetleg vmi callback-et. Ha viszont teljesen heterogén és abszolút összegyezhetetlen dolgok vannak, akkor nincs ötletem.
-
mgoogyi
senior tag
válasz
jattila48
#3599
üzenetére
Vektorban ismétléseket keresni nem annyira hatékony. Vagy arra alapozol, hogy úgyis alacsony lesz az elemszám egy adott scope-ra?
Alapból nem tűnik jó ötletnek vektorba berakni egy csomó castolni való cuccot.Valszeg többet kellene tudnunk, hogy érdemben hozzá tudjunk szólni a témához.
Jó lenne tudni, hogy mikor mire használod a vektort, mikor van beszúrás, keresés, törlés, stb.
Az objektumok feldolgozása soros módon történik? Teszem azt be lehet rakni mindezt egy process nevű virtuális függvénybe, ami specifikus minden altípusra? -
mgoogyi
senior tag
Effective C++ könyv. Ha azt végigrágod és nagyrészt érted is, akkor jók az esélyeid az interjún.
Aminek ezen felül utánanézhetsz: stl, desing patterns, esetleg ha marad időd, akkor szálkezelés, szinkronizációs primitívek. A többi lényeges dolog szerintem benne van a könyvben. -
-
mgoogyi
senior tag
A 8-bites stringből 16-bitesre alakító függvény nyilván determinisztikus kéne legyen.
Ha memória túlírás lenne valahol és az piszkálna bele az output-ba, akkor meg nem hinném, hogy mindig pontosan ugyanazokat a kínai jeleket adná.
Arra gondolnák elsőnek, hogy a lokalizáció változik. Esetleg van inverz transzformáció is a stringre?
Debug módban is jön?
Ki kéne emelni csak ezt a konvertálás dolgot, és izoláltan megnézni, hogy erre a bizonyos kakukktojásra mennyire determinisztikus a konvertálás.
Még esetleg olyat próbálnék meg, hogy a bejövő 8 bites stringet feltuningolnám kicsit, elé-mögé dobnák néhány fix karaktert, esetleg minden karaktere után bedobnék még egy szóközt, hátha abból látszik, hogy hol történik memória korrupció. -
mgoogyi
senior tag
válasz
 bandi0000
#2394
üzenetére
bandi0000
#2394
üzenetére
Akkor nem tudod szétválasztani az előadót és a szám címét, a kettőt egy stringként tudod csak kezelni.
egyben kezelés:
char src[512] = "3 4 5 elthon john: daralt macska";
int x,y,z;
char buff[512];
sscanf(src,"%d %d %d %[]", &x,&y,&z,buff);
printf("%d %d %d %s\n",x,y,z,buff);ha esetleg lenne egy fix elválasztó karakter:
char eloado[512];
char szam[512];
sscanf(src,"%d %d %d %[^:] %*c %[]", &x,&y,&z,eloado,szam);
printf("%d %d %d %s %s\n",x,y,z,eloado,szam);%[] : olyan string, amiben bármilyen karakter lehet, pl. szóköz is (%s-sel white spaceig olvas, pl. tab,szóköz,enter megszakítja a stringet)
%[^:] : olyan string, amiben nincs :
%*c : olvass egy karaktert, de nem kell semmilyen változóba berakni a * miatt -
mgoogyi
senior tag
-
mgoogyi
senior tag
http://softwaresouls.com/softwaresouls/2011/12/11/simple-c-class-example-using-serial-port/
Google barátom ezt mondta, nem tudom, hogy segít-e.
Mindkét portodra rányitsz egy-egy ilyen SerialPort objektummal, aztán az egyikből olvasol(getArray(..)), a másikba meg áttolod (setArray(..)).
Hogy a byte-okból mit tudsz majd leszűrni + hogy mennyire jó Com input egy Com output, arról fogalmam sincs.
Nem csináltam még ilyet, szóval ne vedd készpénznek, amit írtam. -
mgoogyi
senior tag
"A b = B();"
Itt lehet van egy kis zavar az erőben, ugyanis ez a sor arra enged következtetni a 'b' változónévvel, hogy ez egy B típusú objektum lesz.
Holott ez a sor a következőt a jelenti:
A b ( B() );
Azaz hozz létre egy A típusú objektumot annak a copy konstruktorával, amely egy B objektumot kap paraméterként.
Ennek két lényeges aspektusa van.
Egyrészt a B() objektumból ledarálódik minden és A típusú objektum marad, merthogy a copy konstruktor érték szerinti A típusú bemenetet vár.
kb így néz ki és defaultból létrejön a copy constructor: A (A input)
Ez a ledarálás az ős irányába meg mindig implicit ( ~= láthatatlanul magától) megtörténik.Másrészt A típusú objektum fog létrejönni.
Másik dolog, hogy ez a kései virtuális kötés csak pointeren és referencián keresztül értelmezhető.
-
-
mgoogyi
senior tag
válasz
 axelf92
#2056
üzenetére
axelf92
#2056
üzenetére
Valami ehhez hasonló kéne legyen az osztályod:
template < class Key, class Value>
class HashArray
{
bool Insert(const Key & index, const Value & value);
Value operator[] (Key index) { return ...}
stb..
}A kérdés az, hogy a mögöttes adatstruktúra hogy kéne, hogy kinézzen.
Két általános módszer van:
1, Bináris fában vannak a kulcs-érték párok. Ezesetben a kulcsra értelmezhető kell legyen a < operátor.
2, Vagy úgynevezett bucketokban, kb van egy tömb, aminek minden eleme egy lista. A tömbbéli indexet valamiféle hasheléssel találod ki. Pl. ha a kulcs egy szám és 1024 elemű a belső tömböd, akkor a kulcs % 1024 helyen lévő listába tolod bele az új elemet. Csakhogy itt generikus kulcsról van szó, azt nem annyira triviális hash-elni.Itt valszeg az 1-es az ésszerű irány, ami nagyrészt ugyanez, mint az stl mapje:
pl:
#include <map>
#include <string>
std::map<int, std::string> m;
m[1] = "kutya";A legegyszerűbb az lenne nyilván, ha lenne belül egy std::map-ed memberként. (leszármaztatni nem szabad belőle)
De valszeg az 1-es irányt akarja az oktatód, szerintem kérdezd meg, hogy arra gondolt e. -
mgoogyi
senior tag
válasz
 pvt.peter
#2057
üzenetére
pvt.peter
#2057
üzenetére
röviden:
polimorf osztályoknál van értelme, amikor specializálod a működését az ősosztálynak és minden leszármazottat kezelhetsz úgy, mint ha az egy ősosztálybeli objektum lenne.
pl. minden almát és körtét kezelhetsz gyümölcsként
pl. Akkor van ennek haszna, mikor van egy rakás valamilyen gyümölcsöd mondjuk egy halmazban és együtt akarod kezelni őket, mert pl. az adott helyzetben számodra nem lényeg, hogy milyen specializált gyümölcsről van szó.Amikor örökölsz, akkor a virtuális függvények mindig befigyelnek!
hosszan:
class Gyumolcs
{
...
virtual void print() {printf("gyumolcs")}
...
};
class Alma() : public Gyumolcs
{
...
virtual void print() {printf("alma")}
...
};
class Korte() : public Gyumolcs
{
...
virtual void print() {printf("korte")}
...
};
Gyumolcs * a = new Alma();
a->print(); //azt írja ki, hogy alma, pedig ez egy Gyumolcs pointer
/*mivel: a virtuális függvényeknél futási időben dől el (dinamikusan), hogy mi hívódik (megnézi, hogy valójában milyen objektumról van szó és annak a függvényét hívja - a háttérben egyébként van az objektumnak egy virtuális táblája és abból nézi ki, hogy mit kell hívni)
ha nem virtuális lenne a függvény, akkor fordítási időben (statikusan dőlne el, mit kell hívni és "gyumolcs" íródna ki)*/ -
-
mgoogyi
senior tag
válasz
bandi0000
#1966
üzenetére
Szia,
Nekem az első gondolatom egy map, ahol a kulcs a kártya azonosítója (1,2, stb.), az érték meg az, hogy hány darab van belőle.
A map-be szépen beupdateeled, hogy miből mennyi van, aztán néhány állapotjelző kell csak, pl.
numOfPairs
numOfDrills
numOfPokers
, amiket a map alapján feltöltesszKét párnál a numOfPairs 2 lesz, egy full-nál a numOfPairs és numOfDrills 1-1.
Ezeket viszont muszáj végigcsekkolni esetekre bontva. -
-
mgoogyi
senior tag
válasz
jattila48
#1933
üzenetére
Igazad lehet.
Valszeg jobb a konstruktor-ból hibát dobni, mint kétfázisúan inicializálni.
Viszont ha tényleg exception lehetséges a konstruktorban alapesetben, akkor már inkább elmennék a factory irányba, ami lekreálja az objektumot, visszaad rá egy pointert és azt nézheti a hívó fél, hogy NULL vagy sem.
Ebben az esetben a hívó félnek nem kell semmi meglepetésre számítania. -
mgoogyi
senior tag
válasz
pityaa23
#1923
üzenetére
Keress neten a házitokhoz hasonló feladatokat és próbáld megoldani.
+ kérdezz itt, ha van időm, válaszolok.Mindenképp értened kéne ezeket, majdnemhogy készségszinten:
for, while ciklusok
if, else if, else
pointerek, pl int *
referenciák pl. int &
new, new[], delete, delete[]
tömbök kezelése
class
{
private:
public:
protected:konstruktor
destruktoradattagok
tagfüggvények
virtual tagfüggvényekstatic adattagok
static függvényeköröklődés
}fontosabb collection-ök: std::set, vector, list
Mondjuk ez így elég sok, nem igazán két hetes téma.
Jó lenne tudni, hogy mi az, amit elvárnak. -
mgoogyi
senior tag
Bocs, nem akartalak megbántani, de ennyire nem fog egyszerűen menni a tanulás, csak kis lépésekben.
Elsőnek csak csinálj egy kisebb programot, ami beolvas valamit és kiírja a képernyőre.
2, beolvassas azokat a dolgokat, amikre szükséged lesz és azokat kiírja
3, a beolvasott dolgokat eltárolod valahogy, majd azokon végiglépkedve íratod ki
4, elkezdhetsz gondolkozni a többi dolgonA "biztató" szavak azért jöttek ki belőlem, mert a kódod túl sok hibát tartalmaz egyszerre és úgy tűnik, hogy nem probáltad ki az alapvető dolgokat, mint beolvasás, stb.
Meg kell küzdeni lépésenként mindennel. -
mgoogyi
senior tag
válasz
jattila48
#1920
üzenetére
Úgy nézek ki, mint aki nem akar válaszolni?

- Az alapvető szabály (amennyire tudom), hogy ctor-ból és dtor-ból nem jöhet ki exception.
- Kétfázisú inicializálást meg akkor szoktak használni, amikor valamilyen hibakezelés szükséges, amit nem tehetünk meg a ctor-ban.Pl. mint amit te írsz, abban az esetben helytálló a dolog, hogy kétfázisú inicializálás kell. De ha veled kéne dolgoznom és csak az interface-ét látnám annak, amit használnom kell, akkor azt látnám, hogy az init visszatér egy bool-al, nyilván ez kéne, hogy jelezze, hogy sikerült-e az init. Ha teli kell raknom a kódot try - catch-el, mert mindenféle exception-re számítanom kell, akkor nem lesz nagy öröm használni az osztályodat.
És ha 1-nél többször kell használnom, amit csináltál, akkor már jobb, ha te try-catch-ezel az init-ben, az összes mindenki másnak, akik meg hívják az init függvényed, nekik meg elég a visszatérési értéket vizsgálniuk. -
mgoogyi
senior tag
Mi a probléma konkrétan?
A függvény törzsébe nem tudod mit írj, vagy a paraméterlistájába?
Le se fordul?
Vagy ha elakad, hol akad el?Közben megpróbáltam lefordítani.
kivalogatas függvény:113.sor: string Mehetnek[N];
miért definiálod újra, ott van paraméterként
egyébként stack-en foglalt (nem írsz new-t) tömb esetén a tömbméret konstans kell legyen
(pl. const int N = 500 vagy #define N 500)114.sor: újradefiniálás megint, ha csak 0-ázni akarod, akkor elég a K = 0, de ekkor meg nincs értelme, hogy paraméter legyen
main:
33. sor: kivalogatas(N, M, Tanulok); - több, mint 3 paraméter kéne
34. sor: kiiras(); - nem hívhatod meg paraméterek nélkül, mert vannak paramétereibekeres:
89.sor: cin >> Tanulok.nev; - itt elsőre nem tom mi a baja, átírnám cin.getline-osra első próbálkozásképp
kiiras:
139.sor: cout <<"\n" <<" " << Mehetnek(i) <<endl; - itt sem értem miért nem kajolja be, egy .c_str() biztos megoldja
Összefoglalva:
Próbálj meg lépésenként haladni, és miután kipróbálsz(fordít,futtat, minden ok) egy kisebb dolgot, utána lépsz tovább.Most itt összehánytál egy csomó mindent, aztán halvány fingod sincs, hogy mi nem jó.
-
mgoogyi
senior tag
válasz
jattila48
#1913
üzenetére
Én még különösebb iránymutatást nem hallottam kétfázisú inicializálással kapcsolatban, pedig egy ideje már c++-ozok.
A ctor-os try catch dolog:
A felszabadítós dolgokat be lehet rakni egy függvénybe és azt hívod a ctor catch ágában és a dtor-ban is.
Na szóval az a véleményem, hogy ez nem egy lényeges kérdés. -
mgoogyi
senior tag
válasz
jattila48
#1911
üzenetére
- auto_ptr-rel nem tudsz tömböt felszabadítani (ha tudsz is róla, nem biztos, hogy mindenkinek egyértelmű, főleg mert char tömbökkel dolgozol)
- miért lenne baj a kétfázisú inicializálás? azt kell használni, ami célszerű az adott helyzetben.
- az exception dobás elkerülhető a new esetén az std::nothrow paraméterrel: new(std::nothrow), ekkor NULL pointer-t ad vissza a new, ha nem volt elég memória.
- a destruktorodnak muszáj az objektumod által lefoglalt dolgokat felszabadítani, ez nem kérdés. Nem értem ezt a nagy felhajtást.
- a try catchet ennyi erővel berakhatod a ctor-ba is, ha csak az exception a nagy problémád -
mgoogyi
senior tag
válasz
pityaa23
#1909
üzenetére
Csinálsz egy ehhez hasonló Aminosav osztályt:
Class Aminosav
{
private:
std::string rovidites;
char betujel;
int C,H,O,N,S;
const static int C_TOMEG = 12;
const static int *_TOMEG = ...
const static int *_TOMEG = ...
stb.
public:
Aminosav( >>paraméterek<< ) :
rovidites (p1),
betujel(p2),
stb.
{
}
std::string OsszegKeplet()
{
...
}
int RelativTomeg()
{
...
}
stb.
};Beolvasáskor valamilyen konténerbe(pl. std::set vagy std::vector) bepakolod őket a file-ból beolvasott adatok alapján.
Minden részfeladathoz csinálsz neki egy függvényt, és a függvényben megoldod a részfeladatot.
pl a relatív tömeg az egy súlyozott összeadás.Beolvasás: std::ifstream-mel például, a sorok parsolása meg tokenekre szedéssel vagy sscanf.
Az a kérdés, hogy milyen szinten vagy és mi nem világos abból, amit leírtam?
-
mgoogyi
senior tag
válasz
jattila48
#1867
üzenetére
Szia,
Ennek mi lenne a gyakorlati haszna számodra?
Csak a polimorfizmust akarod kihasználni, mert minden ilyen objektumra ugyanazt a virtuális függvényt hívod majd meg az f(Base **)-on belül?
Ezesetben azt tudod mondani, amit előttem is írtak, hogy Base ** tömb-ben közlekedtesd az összes leszármozott objektum-ra mutató pointert.Kooperálnak is ezek az objektumok f()-en belül, vagy csak minden egyes tömbelemre meg kell hívni egy függvényt?
Googyi
b, lehetőség egy makró, aminek a paramétere a tömböd, amit meg csinálni akarsz a makrón belül, azt úgyis csak a Base-ben definiált függvényekkel tudod.
-
mgoogyi
senior tag
válasz
 Jhonny06
#698
üzenetére
Jhonny06
#698
üzenetére
Nálam semmi hibaüzi nincs, visual studio + winXP.
Annak, hogy something.nev semmi értelme, mert a something az egy tömb, neki nincs olyan mezője, hogy nev. A something struktúrák tömbbje, a tömbnek van [i.] eleme, ennek az i. elemnek vannak mezői, mert ez a struktúra. Valahol nagyon kavarhatsz vmit.
Miért nem jó neked, ha azt írod, hogy something[változó].nev??? -
mgoogyi
senior tag
válasz
Jhonny06
#694
üzenetére
Egyrészt ezt így próbáld ki, nekem így simán működik:
#include <stdio.h>
#include <iostream>
#include <fstream>
#include <string>using namespace std;
struct example
{
int day;
string name;
};typedef example array[5];
int load(int& counter, array something);
int write(array something);int main()
{
int counter;
array something;
load(counter, something);
write(something);getc(stdin);
return 0;
}int load(int& counter, array something)
{
ifstream file;
file.open("file.txt");
file >> counter; //<- #2 PROBLEM
for(int i=0; i<counter; i++)
{
file >> something.day;
file >> something(i).name;
cout << something(i).day << " " << something(i).name << endl;
}
file.close();
return 0;
}int write(array something)
{
int one=1;
if(something[one].day)
cout << something[one].name; //<- #1 PROBLEM
/*else
continue;*/
return 0;
}Referencia, cím, stb:
ha van egy tömböd, pl. int tomb[5];
akkor ha csak simán ezt írod le, hogy pl(sorry a c-s kiíratásért, én azt szeretem):
printf("%d",tomb); -> a tömb memóriacíme
tomb[0] -> a tomb memóriacíménél lévő int elem
tomb[1] -> a tomb címéhez képest egy inttel arrébb lévő elem
tomb[2] -> a tomb címéhez képest két inttel arrébb lévő elemtomb + 0 -> a tomb első elemének, avagy a tömbnek a memóriacíme
tomb + 1 -> a tomb második elemének a címe*(tomb + 0) -> a * rámutat a zárójelben lévő címre, azaz az ottani int értéket jelenti
az és(&) jel több dologra jó, most kettőre térek ki:
1. Cím lekérése
van egy ilyen változód, hogy:
int i = 5;
&i ennek az i változónak a címét jelenti a memóriában.
Ha pointerezel: *(&i) az i címére mutató pointer, tehát maga az i.2. Referencia (nem tudom milyen nyelvekben vagy jártas, pascalban pl. ez a var kulcsszó, ill. sok nyelvben meg mindig referencia szerinti átadás van, mint pl. java - persze vannak kivételek

int i = 5;
int & j = i; // az i "álneve" vagy "aliasa" j leszitt a j egy és ugyanaz a változó, mint az i, tehát ha ezt csinálod, hogy
j = 6;
akkor az i is 6 lesz, mivel a két változó ugyanaz, csak két különböző néven tudod őket elérni.ha van egy függvény, ami referenciát vár, pl:
void inc (int & j) {
j++;
}int i = 5;
inc (i);akkor ennek a függvénynek a paramétere egy alias lesz i-re, tehát ha a függvényben megváltoztatod j-t, azzal i-t változtatod. Szal a referencia arra van általában, hogy a bemeneti paraméter kimeneti is lehessen ill. még azért használják, mert ez egy dereferált pointer a beadott paraméterre és ha az a paraméter nagyobb helyet foglal, mint egy pointer, akkor nem kell lemásolni a beadott értéket az újonnan létrehozott ugyanolyan nagy paraméterváltozóba. Ha az utóbbi félmondatot még nem érted, nem nagy gond.
Szóval te egy függvénynek átadtad referenciaként egy tömb címét. Ezt a címet te nyilván nem akarod megváltoztatni, mert akkor a memóriában ki tudja honnan olvasnál be dolgokat.
Kíváncsi vagyok, hogy ebből mit értettél meg...
-
mgoogyi
senior tag
válasz
Jhonny06
#692
üzenetére
Szia,
Első körben két problémát látok:
1, Write() meg Load() függvényeknek fordított sorrendben kéne lennie, mert egy inicializálatlan arrayből nem tudom mit akarsz kiíratni.
2, A Load()-ban a második paramétert tök felesleges referenciaként átadni, nem a tömb címét írod át, hanem a memóriacímen lévő adatokat piszkálod. Ha ez nem világos, amit írtam, akkor bővebben kifejtem. (Referencia helyett inkább const lenne a logikus szvsz.)Még most talán lényegtelen, amíg az alapok nem mennek, de dinamikusan kéne a tömböt lefoglalni menet közben, mert nem tudni, hány sor lesz a fájlban. Ezt így tudod megtenni, hogy: example * tomb = new example[n]; ahol n-et a fájl első sorából olvasod be. Bár ha dinamikusan foglalod le, akkor értelmet nyer a referencia, mert akkor a függvényen belül derül ki a címe. Felszabadítás pedig: delete [] tomb;
Ha pl. azokat a neveket akarod kinyerni, amelyeknél 2 van a név előtt, akkor egy for ciklus a tömbbön és ha if (something.day == 2) cout << something(i).name << endl;
Még valami:
Azzal a continue-val mit akartál elérni a végefelé?? -
mgoogyi
senior tag
#include "fifo.h"
#include<stdio.h>FiFo:
 iFo()
iFo()
{
elementNum=0;
pData=0;
}FiFo:
iFo(const FiFo&theOther)
{
if(theOther.elementNum==0)
{
elementNum=0;
pData=0;
}
else
{
elementNum=theOther.elementNum;
pData=new double[elementNum];
for(int i=0;i<elementNum;i++)
{
pData=theOther.pData(i);
}
}
}FiFo::~FiFo()
{
if (pData) {
delete [] pData;
pData = 0;
}
}double FiFo::get()
{
if (elementNum==0) {
return 0;
}if(elementNum==1)
{
double element=pData[0];
if (pData) {
delete [] pData;
pData = 0;
}
elementNum=0;
return element;
}
elementNum--;
double element=pData[0];
double*pTemp=new double[elementNum];
for(int i=0;i<elementNum;i++)
{
pTemp(i)=pData[i+1];
}
if (pData) {
delete [] pData;
pData = 0;
}
pData=pTemp;
return element;
}bool FiFo::put(double element)
{
double*pTemp=new double[elementNum+1];
elementNum++;
for(int i=0;i<elementNum-1;i++)
{
pTemp(i)=pData(i);
}
pTemp[elementNum-1]=element;
if (pData) {
delete [] pData;
pData = 0;
}
pData=pTemp;
return true;
}bool FiFo::empty()
{
elementNum=0;
if (pData) {
delete [] pData;
pData = 0;
}
return true;
}Alapból a destruktorban szállt el, hiszen a get()-nél mikor kivetted az utolsó elemet, már felszabadítottad a pData-t, a destruktor pedig még1x megpróbálta ezt megtenni.
-
mgoogyi
senior tag
Ha bármely két pont között akarsz pontosan egy irányítatlan szakaszt, akkor az ennyi:
for (int i=0; i<N; i++) {
for (int j=i+1; j<N; j++) {
lineto (i, j);
}
}Bár nem tudom, hogy megy ez a lineto...
Ha két lineto kell egy szakaszhoz úgy, hogy először a kezdőpontot adod meg, aztán a végpontot, akkor a belső ciklusban két lineto kell így:for (int i=0; i<N; i++) {
for (int j=i+1; j<N; j++) {
lineto (pont(i).x, pont(i).y);
lineto (pont[j].x, pont[j].y);
}
}(/I) -
mgoogyi
senior tag
1, Ha csinálsz egy olyat, hogy
delete pData; akkor csináld így:
if (pData!=null) {
delete pData; pData = null;
}Ha úgy próbálsz felszabadítani, hogy a pData-t már egyszer felszabadítottad, el fog szállni futás közben, ezért a null-ra állítással jelzed magadnak, hogy felszabadítottad-e vagy sem.
Meg engem eléggé zavar, hogy pData=0; -t használsz pData=null; helyett.
2, A get()-nél nem ellenőrzöd, hogy elementNum elérte-e a nullát, mert ha igen, akkor a pData[0]-tól semmi jót ne várj.
3, az empty()-nél is ez kéne:
if (pData!=null) {
delete pData; pData = null;
}4, Nagyon nem hatékony, hogy minden egyes beszúrásnál és törlésnél újrafoglalod a tömböt meg átmásolgatod az elemeket. Célszerűbb lenne egy oda-vissza láncolt lista.
Remélem tudtam segíteni! Ha null-t Null-nak vagy NULL-nak kell itt írni, akkor sorry, mostanában inkább java-zok...








































 iFo()
iFo()Új hozzászólás Aktív témák
● ha kódot szúrsz be, használd a PROGRAMKÓD formázási funkciót!
- Motorolaj, hajtóműolaj, hűtőfolyadék, adalékok és szűrők topikja
- One otthoni szolgáltatások (TV, internet, telefon)
- Apple asztali gépek
- urandom0: Száműztem az AI-t az életemből
- Kertészet, mezőgazdaság topik
- Milyen processzort vegyek?
- Real Racing 3 - Freemium csoda
- Call of Duty: Modern Warfare III (2023)
- Az SK Hynix elárulta, hogy meddig nem lesz elég memória
- SörcsaPH!
- További aktív témák...

- BESZÁMÍTÁS! MSI B450M R5 5600X 32GB DDR4 512GB SSD RTX 3070 8GB Zalman Z1 PLUS Cooler Master 700W
- PS Plus előfizetések kedvező áron
- GYÖNYÖRŰ iPhone 13 Mini 128GB Starlight-1 ÉV GARANCIA -Kártyafüggetlen, MS4183, 100% Akkumulátor
- Vállalom telefonok,tabletek javítását ,(szoftveres hibát is,frp lock-ot is)márkától fügetlenűl
- DOKKOLÓ BAZÁR! Lenovo, HP, DELL és egyéb más dokkolók (TELJES SZETTEK)
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest