- Kisebb méretben is elérhető a OnePlus Watch 3
- Belépő táblagépet is villantott a OnePlus
- Változó design, tekerhető lünetta: megjött a Galaxy Watch8 és a Classic
- Teljes külső kijelzővel hódítana a Flip7, ami kapott egy kistestvért is
- Vékonyabb lett, jobb kamerát kapott, de az akku maradt a régi: itt a Fold7
- Azonnali navigációs kérdések órája
- Vékonyabb lett, jobb kamerát kapott, de az akku maradt a régi: itt a Fold7
- Feljutott a G96 a Moto széria csúcsára
- Változó design, tekerhető lünetta: megjött a Galaxy Watch8 és a Classic
- Realme GT 2 Pro - papírforma
- Mobil flották
- Okosóra és okoskiegészítő topik
- Profi EKG-s óra lett a Watch Fitből
- Teljes külső kijelzővel hódítana a Flip7, ami kapott egy kistestvért is
- Samsung Galaxy Watch7 - kötelező kör
Új hozzászólás Aktív témák
-

stratova
veterán
Azért ha azt nézzük, hogy Fiji pl 28 nm-en 596mm^2 volt ehelyett összedrótozhatnák 4 ~150-160mm^2 lapkából, biztosan sokkal jobb lenne a kezdeti kihozatali arány is.
Egyébként az Infinity Fabric nem csak egy nyákon lévő lapkáknál van használatban: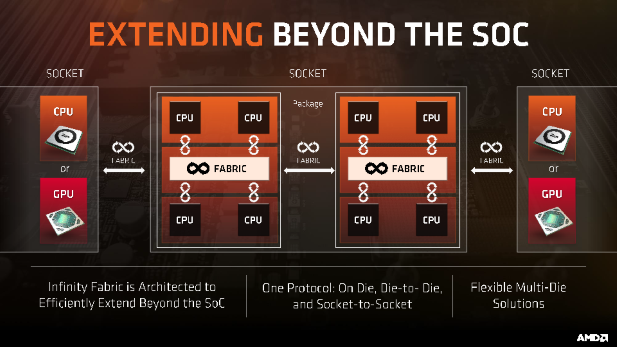
Azaz lehet ki tudnak vagy már kidolgoztak egy nem feltétlenül crossbar működésű, de jobban skálázható megoldást vállalható kompromisszumokkal.
NVLink sem kizárólag GPU-ra érvényes:
Nyilván némi lassulással jár a PCIe összeköttetés, de ez PCIe 4 mellett gondolom javul: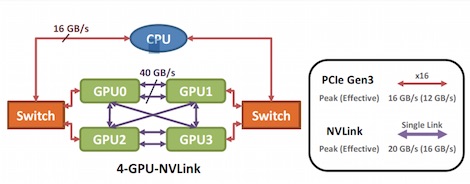
-

Cathulhu
addikt
válasz
 #32839680
#55
üzenetére
#32839680
#55
üzenetére
Ez alapjan mondjuk nem tunik annyira infinite-nek a dolog, inkabb hasonlit a regi crossbar (azt hiszem igy hivtak) memoria buszokhoz, amiknek pont az volt a hatranyuk, hogy exponencialisan novekedett az osszekottetesek szama a modulokkal. Ezen abra szerint pl az infinity fabriccal sem kellene nagyon 4 CCX fole menni, holott ugy tudom, hogy ennel azert joval robosztusabb, nem lehet hogy ez csak egy szemleleteto abra, hogy mindenki mindenkivel osszekottetesben van, de nem a valos logikai kapcsolatrendszer?
-
-

Reggie0
félisten
Csakhogy a GPU-nal sokkal jobban fel lehet osztani az adatot, mint egy CPU-nal. Arrol nem is beszelve, hogy SIMT es nem SIMD. Meg az sem kizart, hogy helybol ket helyre irja ki az eredmenyt, igy mar mindenki a sajat node-jan tudja hasznalni, attol fuggoen, hogy milyen utemben allnak elo az adatok es lesz ra szukseg. Ezen felul meg dual/quad port ram hasznalata sem lehetetlen.
-

.mf
veterán
"Ez nem teljesen igaz. A HBM ota kicsit fejlodott az interposer technika, ma mar sokkal jobb eredmenyeket lehet elerni ket chip kozott."
...... Mit is írtam?
"Itt is megvan a veszély, hogyha egyik GPU-nak éppen egy másik GPU-hoz kapcsolt memóriában lévő adatra van szüksége. Egy nagy sávszélességű interposer réteggel és megfelelő algoritmusokkal ez ma már kevésbé fog korlátozni, de még mindig nem az a minden rózsaszín és MCM-mel minden jobb kép, mint amit a cikk fest."
Szóval GPU1-nek kell valami adat, ami nem VRAM1-ben van.
GPU1 körbekérdezi a többi GPU-t, hogy kinél van
GPU2-3-4 csekkol
GPU3 megtalálja, és beolvassa VRAM3-ból
GPU3 átküldi GPU1-nek vagy GPU1 az interposeren és GPU3-on keresztül VRAM3-ból dolgozza felMég ha az interposer sávszélessége már nem is korlátoz, attól még sokkal nagyobb latency és sok felesleges ciklus, mintha GPU1 simán feldolgozná VRAM1-ből.
-
Reggie0
félisten
Kulonbozo piaci erdekek, legalitas, stb.. Pl. intelnek is kellett egy kis probalkozas sajat IGP-vel, mig rajottek, hogy ez nem fog menni nekik. AMD pedig vagy processzort gyart vagy GPU-t, attol fugg hova teszi a kulcsembereket, de mint latjuk egyszerre nem megy mind a kettobol a csucskategoria. Most pl. ugy dontottek procit gyartanak, a gpuval meg kinlodnak. Nvidianak meg nincsen hozza licence, hogy x86-al egy tokba pakolja a gpuit, ezert inkabb a powerpc fele mozognak, ami a piac eleg kis szelete.
-
Nekem inkább az a furcsa, hogy eddig vártak vele. Az nVidiánál a Fermi óta, az AMD-nél a GCN óta megvannak azok az alapok hozzá, amiknek a megteremtése a legfájdalmasabb volt, a highend kártyák azóta kis túlzással 4-6 kisebb GPU-ból állnak, nyilván a közös scheduler és az egy chip előnyeit kihasználva. Az AMD-nek ráadásul állati nagy szüksége is lenne erre. Kíváncsi leszek.
-

janos666
nagyúr
"Az MCM előnyei vitathatatlanok."
Csakúgy, mint a hátrányai?
![;]](//cdn.rios.hu/dl/s/v1.gif)

"a kisebb lapkák kihozatala biztosan jobb lesz"
Most nincs kedvem tisztességesen átgondolni a valószínűségszámítást redundanciával fűszerezve (tudom, hogy nem kell az összes tranzisztornak, vagy akár "építőblokknak" hibátlannak lennie egy lapkában, hogy valamire jó legyen), de biztos, hogy sokkal jobb lesz az eredmény (piaci igényt is nézve)?
Az összfelület (akár egy lapkás, akár miután összelegóztak több kis lapkát) valamivel nagyobb lesz, hisz be kell építeni magát a buszt is pluszban minden lapkára (és gondolom még pár más dolgot, amiből jobb ha minden lapkának van saját [bizonyos felállásokhoz túlméretes] példánya, mert túl nagy sávszélt zabálna a buszon, ha körbe-körbe csevegne valami folyamat során ez is), így erre a nagyobb területre már rosszabb esélyekkel indulunk (az pedig már valamennyire véletlenszerűnek tűnik, hogy mennyi olyan kis lapkát lehet eladni low-end SKU-n, amire elég egy szál lapka is, így akár a busz is lehet rajta hibás, stb + még a változó piaci igény, hogy milyen kiviteleket keresnek a piacon, kicsiket vagy nagyokat...).
-

Baryka007
addikt
Nah álljunk meg egy pillanatra... Nem tudom mi történt velem, talán aludtam az utolsó pár évben... De mi is pontosan ez az MCM (Azt a tanulnivalót ami angolul van leírva a linkben ne haragudjatok nem volt kedvem elolvasni)
Gyakorlatilag több lapkát teszek egyetlen lapkára amiket egy busz köt össze ? Ez ha GPU-t GPU-val kötök össze gyakorlatilag olyan mintha lenne egy "2 magos gpu-m" ? Vagy teljesen rosszul gondolom ?
-
.mf
veterán
Ugye?
Na ezért kell engem felvenniük 
Anno az Arrandale koncepciója csúnyán elhasalt, mert a külön lapkán lévő proci és IMC közti átvitel sávszélességben korlátozott volt, és a latencyre is rátett még egy kicsit. Itt is megvan a veszély, hogyha egyik GPU-nak éppen egy másik GPU-hoz kapcsolt memóriában lévő adatra van szüksége. Egy nagy sávszélességű interposer réteggel és megfelelő algoritmusokkal ez ma már kevésbé fog korlátozni, de még mindig nem az a minden rózsaszín és MCM-mel minden jobb kép, mint amit a cikk fest.
-
#24
 [CS]Blade2
addikt
.mf
#18
[CS]Blade2
addikt
.mf
#18
[CS]Blade2
addikt
És akkor az volt a hír, hogy micsoda gány munka, hogy úgy van összedrótozva a kupak alatt. Egyébként Dual Core proci is kezdetben drótozott volt.
Na mind1, a lényeg, hogy akkor is ugyanígy itt voltunk, és arról beszéltünk, hogy ez milyen gáz, és ennyi hátránya van, és, hogy milyen jó lesz, amikor jön a CPU-ba integrált IGP és a drótozás nélküli 2 magos CPU-k.
NB és SB kompletten a CPU-ba, főleg a mem vezérlő, hogy annak milyen jó helye lesz ott.Most pedig mindent drótozni kellene, az a tuti, de ahogy én látom itt egyetlen előnye van a drótozásnak, mégpedig az a gyártó cég pénze.
Lévén, hogy olcsóbb egy 1536 számolóegységes GPU-t megtervezni és gyártani, majd összedrótozni 2-t és 4-t, még ezen kívül a selejtben letiltani kb 256-osával párban, és még azt is eladni, mint
tervezni egy 6144-est, abból válogatni a hibátlant és eladni a letiltásokkal a selejtet, meg még egy másik kisebb chipet a középkategóriába, meg egyet az alsóba.Egyébként csak szarabb a drótozott. Az lenne a kompromisszummentes dolog, ha eljutnának oda, hogy a 500-600 vagy nagyobb mm2-es chip egy kicsi, egyszerű könnyen gyártható, chip lenne a számukra.
Nem is olyan régen még az olyan méretű chipeket is csak nehezen tudtak gyártani, ami ma már rutin, közel 100%-os kihozatallal menne manapság.
Ezen kell dolgozni, hogy, ahogy ontja a gyár a 200mm2-es chipet, úgy kellene 600-asokat.
Mi lesz ezek után a fejlesztés: A következő évben 6-ot vagy 8-at drótoznak össze kisebb csíkszélen vagy 2048-as chipet terveznek a kisebb csíkszélre és azt drótozzák össze 4-esével? Értitek, egy idő után ott lennénk, hogy a ma ismert 4096-osból kell összedrótozni 4-et.
Azt mondanom sem kell, hogy a végfelhasználónál egy idő után probléma lenne a túl integrált változat, mert 4db 4 magos CPU, 4db 1536 számolóegységes GPU, az NB, az SB, a rendszer és videómemó mind a kupak alatt lenne, és van egy memóriahiba, és mehet az egész a kukába.
Egyébként így nagyon kicsi lenne a késleltetés és nagyon nagy a sávszél. Minden ott van azonnal -

DraXoN
addikt
válasz
#06658560
#13
üzenetére
A rossz kihasználtság oka kettős.
az első az alacsony hatásfok a jelenlegi több GPU-s rendszereknél, minden, része duplázott, ami nem előnyös programozhatóság szempontjából (duplázott regiszterek, memória kezelés, nem egymás felé gyorsan elérhető munkafolyamatok).
a második az előbbiből ered, maguk a programozók se törekedtek, a tökéletes kihasználhatóságra, túl sok munka lett volna és akkor se lett volna tökéletes az eredmény.A jelenlegi koncepció teljesen más. Ezért lehet érdekes az itteni működés.
-
.mf
veterán
"Amiről igazából kevés szó esik az MCM-es GPU-k kapcsán, hogy nem csak GPU-k köthetők össze így. Ezt minden bizonnyal titkolja az AMD és az NVIDIA is, de ha csak egy picit is továbbgondoljuk a lehetőségeket, akkor bőven opció a GPU-k és a CPU-k egy tokozáson belüli összeköttetése. Ez sokkal nagyobbat fog durranni a fenti iránynál,"
Intel Arrandale, Core ix 5xx, 6xx széria, 2009

-

carl18
addikt
Most nézzem és én is arra leszek legjobban a kíváncsi például msi afterburner hogy fogja látni a magvakat? Külön GPU-nak vagy lehet valami trükk amitől 1 gpu-ként fognak dolgozni. Bár szerintem biztos lesz valami trükk hogy megoldják.
 Ez még egy nagyon hosszú folyamat.
Ez még egy nagyon hosszú folyamat. 
-
Cathulhu
addikt
GPUkban eleg szepen csoportokba vannak rendezve a feldolgozok es a csoportok kozott amugy se tul olcso az interakcio, amig a sajat cachet es registereket hasznaljak jol elvannak, de amint a global memoryhoz kell nyulni ott mar faj igyis-ugyis. Ezen olyan nagyon nem rontana szvsz egy modularis design, inkabb meglepo lenne, ha most gondoltak volna erre eloszor.
-

#06658560
törölt tag
"A grafikus feladatok számítása pedig tradicionálisan jól párhuzamosítható, relatív egyszerűbb parancsokból áll, így (talán) egy automata is letudhatja kezel"
Ha ez így lenne, akkor jobban kellett volna teljesítsenek a több GPU-s rendszerek, mert nem lett volna annyira reménytelen rájuk fejleszteni a játékokat.
"Hardveresen van lekezelve a több magra osztás és a rendszer csak egy GPU magnak látja?"
Szerintem hardveresen elég nehéz ezt lekezelni a driver fogja elrejteni. Ha nem, akkor jön a szoppó.
-
DraXoN
addikt
Viszont lényegesen kisebb lehet a tervezési költség és idő, ami a termék árát is "lenyomhatja"... bár annak jelenleg is csak az ár egy kisebbik részét teszi ki a GPU.
Ez a rész szerintem inkább egy következő "előzetes" lépcsője az újabb generációs APUknak.
Én arra lennék kíváncsi, hogy ez a "többmagos" konstrukció a rendszer felé, hogy látszódik.
Hardveresen van lekezelve a több magra osztás és a rendszer csak egy GPU magnak látja? Mert mindenképpen sokat segítene a konstrukción ha rendszerszinten nem kell figyelni ezen felépítési jellemzőre. A grafikus feladatok számítása pedig tradicionálisan jól párhuzamosítható, relatív egyszerűbb parancsokból áll, így (talán) egy automata is letudhatja kezelni..
De nem tudom, hogy ilyen lesz-e a felépítés, vagy lehetséges-e megoldani ténylegesen hatékonyan. -
#11
Reggie0
félisten
E.Kaufmann
#6
Reggie0
félisten
válasz
 E.Kaufmann
#6
üzenetére
E.Kaufmann
#6
üzenetére
Ok, de ebben nincsen furcsa, prociknal is csinaltak/csinaljak. Max az a furcsa, hogy eddig miert nem csinaltak
-
#10
#06658560
törölt tag
E.Kaufmann
#9
#06658560
törölt tag
válasz
E.Kaufmann
#9
üzenetére
De csak megközelít, el nem ér. Plusz plusz fogyasztás árán, mikor mindegyik cég igyekszik hatékonyabb megoldásokat tervezni.
-

Patice
nagyúr
Nekem az alábbi (nem is olyan régi) cikk ugrott be:
Egyre valószínűbb, hogy AMD GPU-kat szeretne magának az Intel

Attól furcsa, hogy lehetségessé válik az, hogy a prociba integrált IGP lehet akár nVidia, vagy AMD GPU is és nem kell házon belül fejleszteni.
-
stratova
veterán
Ehhez gondolom az is kellett, hogy a 2,5D stacking elért egy megfelelő fejlettségi szintre, vagy más összeköttetést választanak?
(Azt gondolná az ember kézenfekvő, ha már a RAM is 2,5D stackingel kapcsolódik a GPU-hoz interposeren keresztül).nyakdam azért nem teljesen, eddig az APU egy lapkán volt (sőt AMD-nél egy lapka volt), most Applenél lehet egy kupak alatt Intel CPU és AMD GPU. De ilyen monstre lapkáknál a fabric egy NYÁK-on pihenő egységek és és másutt elhelyezkedő CPU ill GPU összeköttetéséért is felelhet.
Az eredeti NV-s hír ha nem tévedek inkább a GPU oldali teljesítménynövelés szempontjából vizsgálta az MCM lehetőségét.
-

Z10N
veterán
Ebből a szempontból az a lényeges, hogy az NVIDIA kutatja ezt az irányt, ugyanis az AMD is így tesz
példáulaz AMD is, mivelKorábban már volt rá utalás, hogy a Navi család a skálázhatóságot több lapka egy tokozáson belüli elhelyezésével fogja biztosítani.Ideje volt mar, ha a multi-gpu kihasznalasa elmarad.
Ui: összeköttetéseket kell beletervezni



























![;]](http://cdn.rios.hu/dl/s/v1.gif)











 igaz ott meg fsbn kommunikaltak.
igaz ott meg fsbn kommunikaltak.





















Új hozzászólás Aktív témák
Hirdetés

- Azonnali készpénzes INTEL CPU NVIDIA VGA számítógép felvásárlás személyesen / postával korrekt áron
- REFURBISHED - HP USB-C Dock G4 docking station (L13899-001)
- Mire Vágyik a Gamer Szíved? Mi tudjuk! Kamatmentes rèszletre is!
- Bitcoin Miner Eladó Bitmain Antminer S19 JPro 104 Th 3150 watt
- Csere-Beszámítás! Custom vizes számítógép játékra! I7 12700KF / RTX 3090 / 32GB DDR5 / 1TB SSD
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest