- Huawei P30 Pro - teletalálat
- MIUI / HyperOS topik
- Samsung Galaxy S23 Ultra - non plus ultra
- Vodafone mobilszolgáltatások
- Most 2027-re tippelik az Apple iFoldot
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Milyen okostelefont vegyek?
- Netfone
- Computex 2024: Vérnyomásérték megbecsülésében is partner az Asus VivoWatch 6
- Fotók, videók mobillal
Hirdetés
-


AMD Radeon undervolt/overclock
lo Minden egy hideg, téli estén kezdődött, mikor rájöttem, hogy már kicsit kevés az RTX2060...
-


Computex 2024: MagSafe külső SSD és Apple Lokátoros burkolat az MSI-től
ma iPhone-hoz, Androidhoz és számítógépekhez egyaránt használható kiegészítők érkeztek.
-


Musk átirányította a Teslának szánt AI-chipeket
it A jelentések szerint Musk arra kérte az NVIDIA-t, hogy a Teslának szánt AI-chipeket az X és az xAI felé irányítsa át. Idén 3-4 milliárd dollárt költhet NVIDIA hardverre a Tesla.






-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
És beszéljük ki, hogy mi mire jó?
Ugye az ESRAM leginkább akkor volt hatékony, ha különböző puffereket nem a RAM-ba mentettél, hanem direkten az ESRAM-ba. A tipikusan memória-intenzív effekteknél ennek nagy haszna van, mert közelebb van, mint a RAM. És akkor tulajdonképpen a 100%-os cache hit mellett az olyan effektek, mint például az SSAO marhára felgyorsultak. Akár alkalmazhattál elborult regiszter- és/vagy LDS-nyomást is, mert nem kellett a tipikus RAM elérési időhöz szabni a konkurens wave-ek számát, hanem lehetett az ESRAM-hoz, és ott már a memóriaelérés átlapolásához elég volt két-három wave is. Ez azért nagyon komoly előny az adott shaderre.
De ez PC-n nem működne, mert per alkalmazás szinten kell optimalizálni. Erre volt is egy saját SDK az Xboxban, amivel tök jó volt, de PC-n senki sem foglalkozna vele.Az L2 cache szimpla növelése igazából egyszerű. Semmi komolyabb indok nincs mögötte a cache hit növelésén kívül. És GPU-król lévén szó az L2 cache hit eléggé fos. Jellemzően 5% alatti, és ha mondjuk sokszorosára növeled az L2-t, akkor is 10-15% alatt marad, mert a GPU egy gyorsítótárakat nagyon szemetelő "állatfaj" a több ezer konkurensen futó szálcsoportjával. De ugye a 10-15% az a duplája-triplája az 5%-nak, tehát ha úgy sem lehet mire költeni a tranyót, akkor miért is ne? Még akkor is, ha nem éppen hatékony ez a fajta brute force koncepció.
Az Infinity Cache az igazából egy másfajta koncepció. Az egy úgynevezett victim cache, aminek a GPU-kban jelenleg semmi más célja nincs, minthogy a tile-alapú leképezést segítette abban, hogy ne kelljen egy csomó esetben elmenni a VRAM-ig. Emiatt az Infinity Cache nem is alapértelmezett része teljes GPU-s cache-rendszernek, és ez azért van így, mert pont az a cél, hogy a GPU ne szemetelje össze.
Ugye egy mai GPU-nál az L2 gyorsítótárak jellemzően a ROP blokkok kliensei. Ez az NV-nél Maxwell óta van így, az AMD-nél a Vega óta, mert a tile-alapú leképezéshez ez az optimális. Ugyanakkor a ROP blokkok úgy kliensei az L2 gyorsítótáraknak, hogy közben a GPU ezt a gyorsítótárat egy rakás más dologra is használja/használhatja. Tehát nem uralkodnak felette a ROP blokkok teljesen, és emiatt az ott tárolt adatok bármikor átdobhatók a VRAM-ba, és ez eléggé tipikus helyzet is. A ROP blokknak sokszor nagyon hasznos lenne, ha a kívánt gyorsítótársort megtalálná az L2-ben, de mivel egy rakás adat cserélődik ott folyamatosan, így elég sokszor kell menni érte a VRAM-ig, és akkor újra behúzza gyorsítótársort az L2-be, amit aztán újra kidob a rendszer, majd ha kellene megint, akkor megint kell menni az adatért a VRAM-ba. És ez úgy nagyjából egy tipikus helyzet, amivel a kívánt adat csak 5-15%-ban van ott az L2-ben, a többi elérés az miss lesz, vagyis menni kell a VRAM-ig.
Az Infinity Cache specifikusan erre a problémára reagál, ugyanis nem része szokásos gyorsítótár-hierarchiának, hanem egy védőhálót képez az L2-ból kidobott, ROP blokkoknak fontos gyorsítótársorok összegyűjtsére. Ezzel tulajdonképpen megelőzi azt a problémát, hogy a GPU-nak a VRAM-ig kelljen menni, ha a ROP blokk által keresett gyorsítótársor hiányozna az L2-ből. És ugye a tipikus nyüzsgés miatt nem is célszerű az L2 kapacitását nagyon növelni, mert a nyüzsgés attól még ott lesz, hogy a gyorsítótár sokkal nagyobb. Szinte minden részegység ír oda valamit, és sok ezer párhuzamosan futó lane mellett ez nem kevés adat ám. Ellenben az Infinity Cache-be a lane-ek nem írnak. Tilos nekik, így nem tudják azt szemetelni. Ez a gyorsítótár csak azt teszi, hogy "felfogja" az L2-ből a nyüzsgés miatt kidobott, de fontos adatokat. És pont azért ér el az AMD pixelszámtól függően 40-70% közötti cache hitet az Infinity Cache-ben, mert magát a nyüzsgést irtotta ki belőle. Nem a kapacitás itt a fontos, hanem a victim cache-sé szeparálás, elvágva a gyorsítótárat attól a több tízezer lane-től, ami alig várja, hogy szétszemetelje az L2-t minden egyes ciklusban.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Yany
addikt
Szerintem a DLSS az egyik legjobb dolog, ami a desktop grafikával az elmúlt időszakban történt. Iszonyat sok ember kiörgedő VGA-jának élettartamát nyújtja ki, vagy akár tesz játszhatóvá addig játszhatatlan játékokat szészőséges esetben. És itt a DLSS-t muszáj nem önmagában nézni, hanem azt is, hogy mit indított el (fsr, és egyéb leszármazottak). Igen, vannak ilyen antialias fronton gigászi hazugságok, amit az emberek a saját szemük által látottakhozt képest is elhittek, pl. amikor a morphologic antialiast bármilyen értelemben is pozitívnak értékeltek. Ha valami, az volt a világ legdurvább szemellenzős átbaxása.
A DLSS-ről kialakult pozitív véleményem egyébként nem hit kérdése, játékfejlesztőként is értékelem, de felhasználóként is a tényekre hagyatkozva alakítottam ki a véleményem. Természetesen látom az esetlegesen előkerülő artifactokat is, hogy szép magyar kifejezéssel éljek, mindenkinek saját értékelése alapján dől el, hogy ez a "trade-off" mennyit ér meg. Nincs ingyen ebéd, ez tény, de egy 4-kra skálázó Quality DLSS 2.x nagyon kellemes szinte minden tekintetben. A DLSS3-mal egyetértek, az már csak az "üljünk fel a DLSS hyprea" című dal a kazetta B oldalán, előadja: NV.
Építs kötélhidat - https://u3d.as/3078
-

PuMbA
titán
Így van. 6800XT-n simán mehet az RTX On
 Ez is belement az agyamba. AMD oldalról még nem találkoztam olyan marketinggel, ami ennyire befészkelt volna az agyamba. A 7700XT vagy 7600XT-nél remélem nyomnak egy kampányt, ha már ezek lesznek a népkártyák.. Ahogy múltkor írtam. Egy jó termék önmagában semmi, ha nem tudják róla az emberek, hogy jó. Önmagában a jó termék nem jelenti azt, hogy többet fognak eladni belőle, mint egy valamivel rosszabb termékből. Abu el tudja nekünk magyarázni, hogy mi hogy van, de ez eladás befolyásolásra haszontalan.
Ez is belement az agyamba. AMD oldalról még nem találkoztam olyan marketinggel, ami ennyire befészkelt volna az agyamba. A 7700XT vagy 7600XT-nél remélem nyomnak egy kampányt, ha már ezek lesznek a népkártyák.. Ahogy múltkor írtam. Egy jó termék önmagában semmi, ha nem tudják róla az emberek, hogy jó. Önmagában a jó termék nem jelenti azt, hogy többet fognak eladni belőle, mint egy valamivel rosszabb termékből. Abu el tudja nekünk magyarázni, hogy mi hogy van, de ez eladás befolyásolásra haszontalan.[ Szerkesztve ]
-

Raymond
félisten
" Pl. BF5-ben az FPS is teljesen jó RT-vel, maxon, WQHD-n... Egy RTX3070 szintjét azért általában hozza, ami az RT-s középkategória volt akkoriban."
Ja, majdnem hozza a 3070 teljesitmenyet ott RT-val, csak a lenyeg itt is a reszletekben van.RT Off On
----------------
6800XT 175 62
3070 139 73
A 6800XT ugy van elmaradva RT-val a 3070-tol 15%-al hogy RT nelkul 26%-al gyorsabb.Privat velemeny - keretik nem megkovezni...
-
Raymond
félisten
-
Nem értem miért ne lett volna ez a konklúzió.
Az RDNA2 első kiadásának felső kategóriás GPu ja, egyetlen SKu volt fölötte,a 6900XT. .Ez szerintem az elvárás volt, hogy raszterben legyen 3080 szintű, meg RT ben is elvárás volt több embernél.
Abból kifolyólag lett ez a következtetés , hogy komolyabb/ megterhelő RT címekben 50% lemaradása volt RT ben a 3080 nal szemben, lásd mint Control vagy Metro, Mindecraft, sorolhatnám míg a 3080 kompetens/ akár gyorsabb is volt RT nélkül magasabb felbontáson.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Inkább én úgy mondom hogy az RDNA2 -őt meg lehet kímélni bizonyos RT megoldások elhagyásával, de ez megközelítés kérdése
De 6900XT nem a 3080 kategóriája szerintem.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Raymond
félisten
-
Yany
addikt
Sokkal inkább ilyen "face-lift" kiadású dolgokra gondoltam, mint egy jobb csíkon kitolt cpu vagy apu, embedded/nas/htpc helyzetekbe nem kell több, vagy fejlettebb kraft, csak sokkal hatékonyabb üzem. Arra tök faja lenne egy-két am4 cuccos, ami nem is kannibalizálna.
Építs kötélhidat - https://u3d.as/3078
-
PuMbA
titán
Nagyon rossz, hogy ennyire erőltetik a dolgot, miközben az összes VGA-nak a legjobb perf / watt közelében kéne gyárilag mennie
Aki ért hozzá és akarja, az tuningol és kisajtol, aki meg nem ért hozzá annak meg pont ez lenne a legjobb, mert a kártya halkabb lenne, elég lenne egy kisebb tápegység stb.[ Szerkesztve ]
-

Pakmara
őstag
Ezzel is egyetértek user oldalról, de ne az legyen a marketing anyag alapja, hogy letelerem mérek egyet és tádám 54%. Aztán vissza és tádám ennyi fps. Out of box összenézik a két kártyát és megvan mennyit javult twljesítmény és mennyit perf/w alapon. Lehetne nézni 7900 xtx vs 6900 XT 250-280 W limit és el is olvadna az egyébként létező előny java.
Egyébként minden kártyámnál így csinálom én is. Nekem valahogy szimpatikusabb hasam a ütök minusz 5-10% teljesítményért 15-20%-al kisebb fogyi mint fordítva.
-
Pakmara
őstag
Igen eltér, de sztem ez nem probléma összehasonlításnál. Out of box össze kell nézni és ennyi. Kapott fps/ 300 w a 6900-nál, ugyanez a 7900-nal is fsp/355. Szerintem így fair perf/w-ot nézni. Ha manual belenyúlsz akkor a nagyobb alap kerettel rendelkező kártyának kedvezel akarmerre húzod is. 355-nél a 6900 az ellaposodó görbe miatt nem profitál annyit mint amennyivel magasabb a keret, 300-nál a 7900 megy a jellemzően jobb p/w-al kecsegtető irányba.
-
#60413
 Petykemano
veterán
HSM
#60412
Petykemano
veterán
HSM
#60412
Petykemano
veterán
> kockázat
Ez így van.
Az azt megelőző posztban így fogalmaztam:
"HA ugyanazt a profit volument el lehet érni magas margóval és kis értékesítési volumennel, mint amit alacsony margóval, szélesebb körben terített nagy termékvolumennel, akkor előbbi sokkal nagyobb működési biztonságot jelent."De igazad van, hogy ezen túlmenően, hogy ha nagyobb mennyiséget gyártasz kisebb margóval nagyobb összprofit volumen reményében (mármint itt persze nem reménykedés, hanem kalkuláció van) akkor az nagyobb kockázatot, kitettséget jelent váratlan események vonatkozásában.
Az AMD-t szokás manapság meglehetősen kockázatkerülő magatartással jellemezni. Legalábbis sokan azzal magyarázzák az OEM térhódítás elmaradását, hogy az AMD szinte semmilyen manővert nem vállalt, amiben benne volt az a kockázat, hogy rajtuk marad egy nagyobb tétel valamilyen termékből (vagy waferből), mert nem sikerül a pályázat, vagy a partner visszadobja.
Találgatunk, aztán majd úgyis kiderül..
-
#60420
Petykemano
veterán
HSM
#60414
Petykemano
veterán
Nem mondtam, hogy indokolatlan az óvatosság
Csak azt, hogy a cégek tudatosan és nagy befolyással kontrolálják a kereslet-kínálat törvényének nevezett jelenségnek azt a részét, amit a kereslet visszaesésével vagy túlkínálattal szoktak jellemezni.Ahelyett, hogy kiszolgáltatnák magukat ennek a gazdasági törvényszerűségnek és engednék a piac szabályai szerint a lebegő árat bezuhanni a kereslet visszaesésének következtében, inkább hajlandók és képesek kooperálva meghatározni egy árszintet, amelyen a tervezettnél időben jobban elnyújtva, de nagyobb margót elérve képesek meglevő készleteiken túladni, amelyen hosszabb ideig is hajlandók kotlani.
Találgatunk, aztán majd úgyis kiderül..
-
#60449
 Alogonomus
őstag
HSM
#60448
Alogonomus
őstag
HSM
#60448
Alogonomus
őstag
Sokáig ez volt a vélemény itt a 70 dollárból készíthető, de 700 dollárért is elkapkodott 7950X esetéből kiindulva. Most visszanézve Petyke írta, hogy az olcsóbb Navi 31 és GDDR6 előnyén sokat ront a drágább PCB, ami szükséges a Navi 31 "alá". De mintha Abu is írt volna ilyet.
Szóval a Navi 31-es kártyák esetén azért annyira nem komoly előny a chiplet kialakítás, amennyire a különböző Zen processzorok esetén hatalmas előnyt jelent.[ Szerkesztve ]
-
#60451
Petykemano
veterán
HSM
#60448
Petykemano
veterán
Mihez képest olcsóbb?
Ez a körülmények és viszonyítási alap függvénye.Ha Abu számaival kalkulálunk, hogy 7x drágább az N5, vagyis $35000 vs $5000 az N5 és N6 wafer ára, akkor relatív kevés N5 megspórolása is sokat számít.
Viszont ezeket az árakat semmilyen más forrású pletyka nem erősítette meg. Megkockáztatom, hogy ilyen N5 waferár mellett talán a zen4 se kerülhetne annyiba, amennyiért árulják. Hiszen olcsóbb a Raphael, mint a zen3 volt hasonló korában, amelyről szűkösséget ugyan igen, de $35000-es waferárat sose mondott senki.Lehetséges, hogy 1-2 éve, amikor még fullra pörgött a gyár, meg a kapacitás lefoglalás előfordult olyan helyzet, hogy kurrens licit ár ennyi volt. De a mai 70%-os kihasználtság mellett kétlem, hogy a fölös kapacitások még mindig ennyiért mennének.(ezzel arra utalok, hogy az se biztos, hogy egy cég wafer ára egységes, lehet, hogy vannak eltérő időben ektérő áron lefoglalt kapacitások)
Szóval.
Ha az N5 ára mérsékeltebb, akkor az azon nyert árelőny is mérsékeltebb, hogy a lapka egy része nem N5-ön készülni.És akkor mi a viszonyítási alap?
Ha a navi31 versenyképes lenne az 500mm2-es ad102-vel, akkor valóban nagy előnyt jelentene a chipletezés. Kár, hogy nem pörög annyit a frekvencia, vagy nem segít a v-cache, vagy talán megérte volna egy 400mm2-es GCD-vel próbálkozni. (Ugyanakkor azt se felejtsük el, hogy a 4090 vágott!)
De mondjuk egy AD103-hoz képest, amivel versengeni tud, és ami 70mm2-rel nagyobb N5 lapkát jelent. Hogy valóban költségmegtakarítást jelent-e az a -70mm2 N5 +180mm2 N6 + csomagolás?
Hááááát. Én kétlem.Ha ahhoz viszonyítjuk, hogy mekkora lenne ez monolitikus N5-ön, akkor kivonhatnánk 6x2x5mm2 kapkaterüketet (60mm2), ami így 420mm2-re jönne ki és nem lenne csomagolási költség. Talán sűrűbb lenne az MCD rész, legyen inkább 400mm2
Annyi előnye biztosan lenne, hogy az infinity cache hasznosulása nem lenne limitálva az chiplet interconnect sávszélessége által és talán némi késleltetést is spórolnának. Talán lenne annyival gyorsabb, mint amennyivel nagyobb az AD103-tól.Cserébe 1/3-dal nagyobb lapka lenne. Valamivel rosszabb kihozatal. Ha abban a kapacitáskorlátos időszakban lennénk, mint amire feltehetőleg számítottak, akkor ez pont eggyel több eladott gpu lenne minden harmadik után. De "sajnos" jelenleg nincs kapacitáskorlát. Ha annyival drágább lenne az N5, mint ahogy Abu mondta, akkor ez valóban komoly költségmegtakarítást jelentene. De valószínűleg nincs akkora difi.
Én nem látom, hogy ez jelen körülmények között akkora előnyt jelentene - mint mondjuk a Naples volt egy 700-800mm2-es szerverlapkával szemben.
Szerintem ezt elkalkulálták.
Bízzunk benne, hogy jó tanulás volt és sokat lendített előre a multigpu irányba. Merthogy a chipletezés másik jelentősége ott lehet, hogy nagyobb lapkát tudsz összelegózni, mint monolitikusan legyártani. De ez meg még nem az a generáció.Találgatunk, aztán majd úgyis kiderül..
-
#60454
Petykemano
veterán
HSM
#60450
Petykemano
veterán
Tulajdonképpen kiadhatnának ilyen Navi31-et is, négy GCD-vel és 256 biten, de úgy lehet kicsit túl kevés lenne az L3, viszont V-cache-el a gyártási bonyolódás.
A Navi31 - ha nem számoljuk a dual issue / VOPD képességet, tulajdonképpen nem jelent nagy felskálázódást a Navi21-hez képest, csak 20%-kal több CU-t tartalmaz.
Bár abu szerint azért csökkent 128MB-ról 96MB-ra az oo$ mérete, mert az AMD olyan sokat fejlesztett rajta, hogy ennyi is elég, ha ez tényleg így volna, mi a fenéért tervezték volna rá a v-cache ráilleszthetőséget teljesen feleslegesen?
Szerintem a chiplet interconnect sávszélessége limitál.
Szerintem egy interconnecten 16MB oo$-hez tartozó sávszélesség megy át. Lehetne 32MB, vagy rárakhatnák a v-cache-t, ami talán picit segítene a késleltetésen a VRAMból való beolvasáshoz képest, de összességében kevés volna és ezért inkább növelni kellett a chiplet interconnectek számát.Persze ez csak az én elméletem.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
PuMbA
titán
Cyberpunk (és ennek okán a Witcher 3) esetén nem minden fényforrás számolódik RT-vel jelenleg. Ezt onnan lehet tudni, hogy van jó pár fény, ami előtt elhalad például egy NPC és nincs árnyéka. Metro RT esetén pedig csak a GI (Global Illumination) számolódik RT-vel, tehát csak a nap / holdfény. A lokális fények nem.
A Cyberpunk 2077-be belekerül az RTXDI, ami fut AMD-n is és képes fényforrások tízezreit RT-vel számolni, árnyékokkal együtt.
[ Szerkesztve ]
-

Busterftw
veterán
En is emlitettem ketto tesztet es egy tucat Reddites usertol sajat merest.
Na akkor most mi legyen, visszatero butasag vagy van alapja?
Mert ugye AMD GPU magas idle fogyasztas is butasag, hiszen paran bedobtak a "nalam nem fordul elo, tehat nem letezik" ervet.
Raymond
Tavol all a valosagtol, ne erolkodj.[ Szerkesztve ]
-
Busterftw
veterán
Ahogy a tenyek es a tesztek mutatjak, egyertelmuen van alapja, tobb publikalt meres is alatamasztja, lasd fentebb.
"Ebben a formában igen, ugyanúgy butaság"
Nem, nem az, ez egy AMD altal elismert teny, amit a tesztelok kimertek.
Aztan hogy te milyen meset koritesz hozza, teljesen irrelevans.
"AMD's release notes also reveal why some early RX 7900 XT/XTX reviews have noted that AMD's RX 7900 series GPUs have higher than expected levels of idle power consumption."
Known Issues:
- High idle power has situationally been observed when using select high resolution and high refresh rate displays.Tovabbi jo valosag tagadast.
[ Szerkesztve ]
-
Busterftw
veterán
Persze, de akkor most ez a szint?
Van par teszt es pelda a magas idle fogyasztasa: ez csak par pelda, nincs alapja.
Van par ellenpelda a magas idle fogyasztasra: latod van par ellenpelda, nincs alapja.Ertem hogy ez a szokasos kikezdhetetlen win-win strategia AMD vitakban, ne menjunk mar le dedoba egy vitaban.
-
#60602
 KaszkóPalkó
kezdő
HSM
#60601
KaszkóPalkó
kezdő
HSM
#60601
KaszkóPalkó
kezdő
egyébként ha te hozol példát, akkor az ellenpélda, amit komolyan kell venni, ha a másik akkor pár esetből ne vonjunk le következtetést
és ez a hozzáállás kb minden vitádra igaz, amikor már elmegy a vonat és nincsenek vagy elfogytak érveid, illetve megcáfoltak
meg úgy általánosságban rossz amd nincs, és akármilyen blőd indokokkal mindig meg tudod magyarázni miért kell amdt venni
ennyivel összefoglalható a fórumtevékenységed, és nem csak az itt olvasottak alapján
[ Szerkesztve ]
-
#60604
KaszkóPalkó
kezdő
HSM
#60603
KaszkóPalkó
kezdő
"kinek van szerencsém?" az igen, szép
![;]](//cdn.rios.hu/dl/s/v1.gif) , mivel ezen kívül mivel több nem telik tőled, az irreleváns személyeskedésed visszautasítom, jó?
, mivel ezen kívül mivel több nem telik tőled, az irreleváns személyeskedésed visszautasítom, jó?Az alapvető logikád hibás, főleg hogy csak az amd esetében használod ezt a "logikát" nagyon durván idézőjelbe téve. Mert a néhány ellenpéldádból nem lehet általános következtetést levonni, ezért nem cáfoltad meg az eseteket (magas idle fogyasztás)
Na?
[ Szerkesztve ]
-
#60606
KaszkóPalkó
kezdő
HSM
#60605
KaszkóPalkó
kezdő
"ugyanazon a néven vagyok jelen itt, mifelénk ez így szokás" alapvetően egy nagyon szép bizonyítvány ez rólad, mivel bizonyítékok nélkül vádaskodsz. Mifelénk ez nem szokás. Az meg pláne nem, hogy így próbáljunk valakit hitelteleníteni.
"Én nem vontam le általános következtetést néhány ellenpéldából, hanem EGY HIBÁS ÁLTALÁNOS KÖVETKEZTETÉST CÁFOLTAM velük"
1. Nem tudtad megcáfolni, hiszen abból a néhány ellenpéldából amit hoztál, nem lehet általános következtetést levonni. Ha pedig igen, akkor áll a kettős mérce. Hiszen ha a magas idle fogyasztást nem lehet általánosítani pár esetből, akkor az ellenkezőjét sem...
2. A 60603-as hozzászólásodban még nem voltak hibásak a magas idle fogyasztásról szóló példák, akkor még csak kevés volt a példák száma az általános következtetéshez.= szépen alakítod a véleményed, és ebből az látszik te pontosan tisztában vagy a kettős mércével, amit alkalmazol.

[ Szerkesztve ]
-
Busterftw
veterán
De pontosan errol van szo.
Egy jelenseget par ellenpeldaval probaltad cafolni amire pont ugyanannyi ha nem tobb bizonyitas is van.
Csak nalad a vitakultura az, hogy a "par" bizonyitasra kisujjbol ramondtad hogy nem jelent semmit, a te ellenpeldad viszont mindent eldonto cafolat.Ha ezt egy 5 evesnek elmagyarazom megerti, hogy WTF logika es massziv double standard.
-

S_x96x_S
őstag
> Az eredeti állítás, amit cáfoltam ez volt:
> "a 30-60 Wattos idle fogyasztás hátránya az AM5-nek".
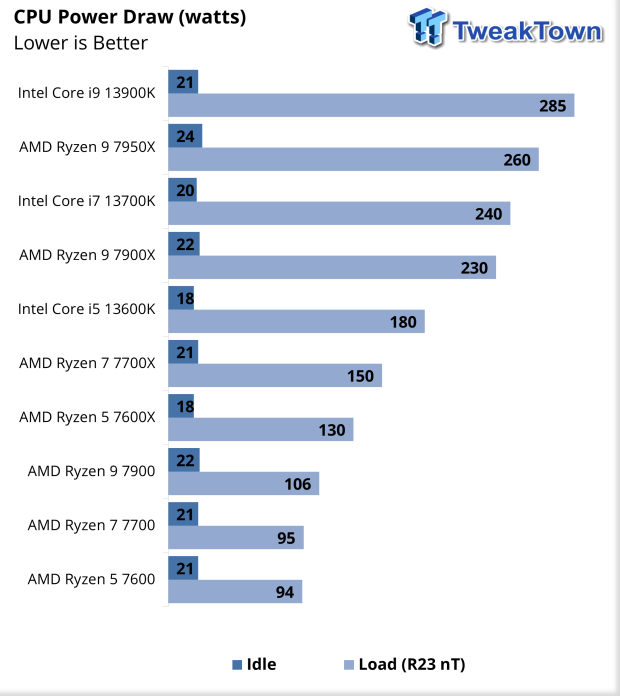
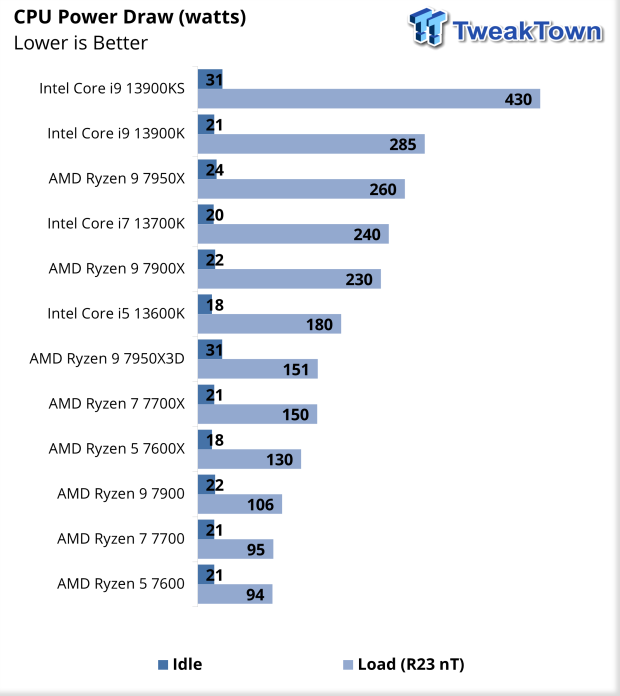
amúgy itt egy teszt idle-re ..[1] [2]ha netán valaki azzal érvelne, hogy a procik sokat esznek idle-ben,
akkor valószínüleg hoz egy hasonló ellenpéldát ..amúgy egy mérés nem mérés ..
és sok függ a BIOS, Windows verziótól meg az alaplaptól is.Mottó: "A verseny jó!"
-
#60618
KaszkóPalkó
kezdő
HSM
#60613
KaszkóPalkó
kezdő
Nem nekem írtad, de rólam beszélsz, így válaszolok. Azért mert nem volt regem, olvashattam a fórumot. Hogy milyen hosszú életű egy új fiók nem tudom, de csomó rangú reget látok, valahogy csak lettek ők is... ha nem az idők alatt, a megírt hsz-ek száma miatt, akkor elég fanboynak lenni egy félistenhez? Ne vedd magadra, csak kérdeztem, ahogy te is...
[ Szerkesztve ]
-

GeryFlash
veterán
,,Nem bug, technikai sajátosság". Édesistenem. Még az AMD szerint is knonw issue, tehát bug.
Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
PuMbA
titán
Senki nem kötelezi az AMD-t, hogy félkész dolgokat engedélyezzenek. Sajnos ez menedzsment probléma
 Ha nem működik 100%-osan, akkor hagyják a fenébe, mert az egyszeri felhasználó nem fog venni AMD-t soha az életben. Nem tudom, hogy miért nem veszi észre az AMD, hogy maga alatt vágja a fát, de már nem meglepő ennyi év után.
Ha nem működik 100%-osan, akkor hagyják a fenébe, mert az egyszeri felhasználó nem fog venni AMD-t soha az életben. Nem tudom, hogy miért nem veszi észre az AMD, hogy maga alatt vágja a fát, de már nem meglepő ennyi év után.[ Szerkesztve ]
-

Frame G:
" ami a számolt képkocka szín- és mélységadatai, illetve a mozgásvektorok mellett, a korábban elkészült kép információit is beolvassa előzményminták formájában, és ezekből a részadatokból próbál optimálisan felskálázott új képkockát generálni."8 már lerenderelt képkockát, mozgásvektort vesz alapul az új képkocka generálásához. és ebből tér el a petyke által leírttól, de természetesen ez lassabb.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Hiába linkelgetsz..
Nem a képkocka megjelenítésről volt szó hanem a generálásról, ahogy fogalmaztál kitalálásáról, és ez két különböző fogalom.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
így van, tökéletesen leírtad.
Annyi csak, hogy nem az utána jövő képkocka teljes kialakulásáig alkotja meg a köztest, mert az OFA (Optical Flow Accelerator ) a beérkező mozgásvektor adatok alapján már megalkotja a köztes képkockát az előző 8-ból mintavételezéssel és az utána jövő mozgávektor adataiból, tehát az utána lévő képkockából a bemeneti információkra van "csak" szüksége, így gyorsítja a folyamatot és alkot pontosabb képet , ebben tér el egy sima két képkocka közé beszúrt blindframe megoldástól.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Raymond
félisten
Tehat fogalmad sincs milyen a minoseg csak "nem tudod elkepzelni". Akkor javaslom jarj utanna eloszor es ha van lehetoseged akkor tapasztald meg aztan folytathatjuk.
"Nyilván ezért vezették be itt a késleltetett megjelenítést, hiszen itt alapvetően a jó minőségű interpolált kép elérése az elsődleges cél."
VR-nal ott az IMU-bol az adatok a jovo joslasara, ez a 2D PC-s jatekoknal nincs igy valami kellett a masik oldalra is. Peldaul, de mondom eloszor jobb ha picit jobban erted, mert addig felesleges a diskura.
Privat velemeny - keretik nem megkovezni...
-
Raymond
félisten
"Ugyan miért ne lenne? Ugyanúgy megvannak PC-n is az input adatok, csak nem az IMU-ból, hanem az egérből jönnek... Ne állítsuk már be varázslatnak, ami nem az..."
Mert nincsenek. VR-ban az IMU adatok feldolgozasa, prediction, stb. egy teljesen mas dimenzio mint az hogy a PC-n meghuzod az egeret. De mondom, ha nem ertesz hozza akkor legalabb kezd azzal hogy megnezed milyen egy VR pipeline mielott irsz valamit ami aztan egy badarsag lesz."Épp elég panaszt olvastam a VR generált képeire, hogy legyen róla elképzelésem."
Ergo fogalmad sincs mirol beszelsz "Maradjunk annyiban, hogy ez amolyan "educated guess". Informatikai végzettségűként van némi fogalmam ezen technológiák korlátairól anélkül is, hogy részletes analízist kellene készítenem róla..."
Abbol amit eddig irtal az jon le hogy az "educated guess"-tol egyelore merfoldekre vagy.
Privat velemeny - keretik nem megkovezni...
-
Raymond
félisten
"Mert az egérmozgást nem lehet előre jósolni? Pont annyira lehet, mint az IMU-val."
Minek josolgatnal egy PC-s jateknal? Senki nem josolgat, akkor tudod mi az uj input amikor megtortent aztan az alapjan kezdesz renderelni. VR-nal viszont fontos hogy a kesleltetes minel alacsonyabb legyen igy az IMU adatok alapjan megy a josolgatas fuggetlenul attol hogy fut vagy nem valami jatek vagy csak a menuben vagy es a kompozitorban van a megjelenites elott meg rapasszintva a bejovo kep az epp aktualis helyzetre. Ez az ATW/PTW es fuggetlenul attol megy hogy fut vagy nem a jatek es hogy hasznal vagy nem a jatek ASW-t ami akkor fontos amikor a jateknal nincs meg a kivant FPS."Persze, értem én, hogy érvelés helyett könnyebb olyasmikkel dobálózni, hogy "nem értesz hozzá"
Nem en vagyok az aki ertelmetlen dolgokkal dobalozik. Mar a legelejen vilagos volt hogy nincs semmilyen hasznalhato informaciod a temaval kapcsolatban es ezt le is irtam neked. Azota ahelyett hogy utannaneztel volna csak meg tobb bizonyitekkal szolgaltal arrol hogy az elso megiteles helyes volt.
Privat velemeny - keretik nem megkovezni...
-
Raymond
félisten
OK, ha nem hagyod akkor tessek. A #60690-re eloszor akartam valaszolni de mondom hagyom hogy meglegyen neked ez a "saving face" dolgot de latom nem volt sok ertelme nem leirni hogy fantasztikus hogy megtalaltad vegre az irast amit linkeltel akkor es el is olvastad, azzal kellett volna az elejen kezdened.
Egyebkent itt megint nem tudom mirol beszelsz. Amit en kifogasoltam az a "VR-nal nem fontos a minoseg" kijelentesed. Ami termeszetesen badarsag. Amit most ideztel ott sznten nem azt mondom, hanem ezt: "A VR-ban sokkal fontosabb a kesleltetes mint a 2D jatekoknal." Az hogy nem erted vagy szandekosan nem akarod erteni a gyakorlatban lenyegtelen.
Azon se valtozott semmi hogy egy edge case-eket is bemutato videobol itelsz meg valamit ami nem igazan szerencses. En es rengetegen masok is evek ota latjak hogy nez ki a gyakorlatban az osszes valtozata. Az hogy bizonyos esetekben nem idealis azt nem vitatka senki, csak amikor az esetek 99%-ban nem latod vagy nem zavar akkor azzal a maradekkal egyutt tud elni mindenki.
A DLSS3-nal is amit en az osszes eddigi videoban lattam az hogy a UI a legnagyobb problema. Legyen az MSFS vagy az F1 floating elements. De az hogy egy scene valtasnal amikor a ket kep 100% kulonbozo nem tud normalis eredmeny generalni az nem meglepo es nem is igazan problema 120FPS-nel az az egy frame. Vagy amikor a HUB videoban 10% sebessegel (es egyszer raadasul 3%) kell valamit lejatszani hogy megmutassa a "problemat" akkor az a kakan a csomo kereses kategoria szerintem.
Privat velemeny - keretik nem megkovezni...
-
Busterftw
veterán
Igen, amit 2015-ben atadtak. De a DXVK 2018-2019 release.
A Wine-t fejleszto sracok dolgoztak be a Protonba, hiszen az egy Wine fork.Kb annyi koze van az AMD-nek ahhoz, mint a BOE-nek, hiszen ok szallitjak a displayt.
Nem arrol van szo, hogy a Vulkan nem relevans a modern jatekokhoz, hanem arrol hogy a DXVK-hoz az AMD-nek semmi koze.[ Szerkesztve ]
-
Busterftw
veterán





 Ez is belement az agyamba. AMD oldalról még nem találkoztam olyan marketinggel, ami ennyire befészkelt volna az agyamba. A 7700XT vagy 7600XT-nél remélem nyomnak egy kampányt, ha már ezek lesznek a népkártyák.. Ahogy múltkor írtam. Egy jó termék önmagában semmi, ha nem tudják róla az emberek, hogy jó. Önmagában a jó termék nem jelenti azt, hogy többet fognak eladni belőle, mint egy valamivel rosszabb termékből. Abu el tudja nekünk magyarázni, hogy mi hogy van, de ez eladás befolyásolásra haszontalan.
Ez is belement az agyamba. AMD oldalról még nem találkoztam olyan marketinggel, ami ennyire befészkelt volna az agyamba. A 7700XT vagy 7600XT-nél remélem nyomnak egy kampányt, ha már ezek lesznek a népkártyák.. Ahogy múltkor írtam. Egy jó termék önmagában semmi, ha nem tudják róla az emberek, hogy jó. Önmagában a jó termék nem jelenti azt, hogy többet fognak eladni belőle, mint egy valamivel rosszabb termékből. Abu el tudja nekünk magyarázni, hogy mi hogy van, de ez eladás befolyásolásra haszontalan.

 Harmadolja az RT bekapcsolasa igy ahhoz hogy meglegyen ott a 60FPS az kell hogy a jatek RT nelkul 180FPS legyen.
Harmadolja az RT bekapcsolasa igy ahhoz hogy meglegyen ott a 60FPS az kell hogy a jatek RT nelkul 180FPS legyen. 

![;]](http://cdn.rios.hu/dl/s/v1.gif)











 (
(  (
( 

 Ha nem működik 100%-osan, akkor hagyják a fenébe, mert az egyszeri felhasználó nem fog venni AMD-t soha az életben. Nem tudom, hogy miért nem veszi észre az AMD, hogy maga alatt vágja a fát, de már nem meglepő ennyi év után.
Ha nem működik 100%-osan, akkor hagyják a fenébe, mert az egyszeri felhasználó nem fog venni AMD-t soha az életben. Nem tudom, hogy miért nem veszi észre az AMD, hogy maga alatt vágja a fát, de már nem meglepő ennyi év után.Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Glo cigaretta
- Huawei P30 Pro - teletalálat
- CURVE - "All your cards in one." Minden bankkártyád egyben.
- Musk átirányította a Teslának szánt AI-chipeket
- VR topik (Oculus Rift, stb.)
- nVidia tulajok OFF topikja
- Autós topik
- Nvidia GPU-k jövője - amit tudni vélünk
- MIUI / HyperOS topik
- Milyen processzort vegyek?
- További aktív témák...

Állásajánlatok

Cég: Alpha Laptopszerviz Kft.
Város: Pécs

Cég: Ozeki Kft.
Város: Debrecen