- Mobil flották
- Magisk
- Redmi Note 11 Pro 5G - a bajnokesélyes nem készült fel
- Samsung Galaxy S21 FE 5G - utóirat
- Eleglide C1 - a középérték
- Samsung Galaxy A72 - kicsit király
- MIUI / HyperOS topik
- Ennyibe kerülnek a Huawei Pura modellek Európában
- Motorola Edge 40 - jó bőr
- Nothing Phone 2a - semmi nem drága
Hirdetés
-


Letartóztatták a bitcoin-Jézust
it Amerikai adókerülés vádjával, Spanyolországban tartóztatták le a bitcoin-Jézusként ismert Roger Vert.
-


Az Apple megszerezné a klubvilágbajnokság közvetítési jogait
ph A vállalat ezért irgalmatlan pénzt fizetne a FIFA-nak, és ezzel rajzolná át az online streaming platformok háborújában a frontvonalakat.
-


Mindent megtudtunk az új Nokia 3210-ről
ma Részletes képek, specifikációk és euróban megadott ár is van a legendás modell újraélesztett verziójához.






Új hozzászólás Aktív témák
-

S_x96x_S
őstag
AMD Ryzen Threadripper PRO 3000 final specifications leaked
- up 128 PCIe 4.0 lanes
- up to 2TB of UDIMM (Unbuffered DIMM) , RDIMM (Registered DIMM), LRDIMM (Load-Reduced DIMM) and 3DS (three-dimensional stacking) RDIMM EEC memory.
-https://videocardz.com/newz/amd-ryzen-threadripper-pro-3000-final-specifications-leaked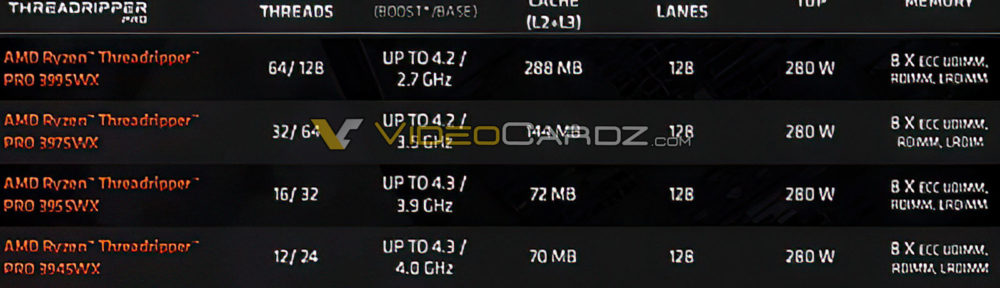

Mottó: "A verseny jó!"
-
#3552
 hokuszpk
nagyúr
Petykemano
#3544
hokuszpk
nagyúr
Petykemano
#3544
hokuszpk
nagyúr
-
#3553
 awexco
őstag
Petykemano
#3550
awexco
őstag
Petykemano
#3550
awexco
őstag
válasz
 Petykemano
#3550
üzenetére
Petykemano
#3550
üzenetére
Gondolom Amd úgy viselkedik mint egy kúrva .... felméri a terepet és a kuncsaftnak azt csinálja amiért fizetnek ...
I5-6600K + rx5700xt + LG 24GM77
-
S_x96x_S
őstag
#versenytárs ; #X86 utasítások
Linus Torvalds megátkozta az AVX512-öt.
Linus Torvalds: "I Hope AVX512 Dies A Painful Death"
https://www.phoronix.com/scan.php?page=news_item&px=Linus-Torvalds-On-AVX-512"I hope AVX512 dies a painful death, and that Intel starts fixing real problems instead of trying to create magic instructions to then create benchmarks that they can look good on.
I hope Intel gets back to basics: gets their process working again, and concentrate more on regular code that isn't HPC or some other pointless special case.
I've said this before, and I'll say it again: in the heyday of x86, when Intel was laughing all the way to the bank and killing all their competition, absolutely everybody else did better than Intel on FP loads. Intel's FP performance sucked (relatively speaking), and it matter not one iota.....
And AVX512 has real downsides. I'd much rather see that transistor budget used on other things that are much more relevant. Even if it's still FP math (in the GPU, rather than AVX512). Or just give me more cores (with good single-thread performance, but without the garbage like AVX512) like AMD did.

...
"
Mottó: "A verseny jó!"
-
#3555
 Petykemano
veterán
S_x96x_S
#3554
Petykemano
veterán
S_x96x_S
#3554
Petykemano
veterán
-
#3556
S_x96x_S
őstag
Petykemano
#3555
S_x96x_S
őstag
válasz
Petykemano
#3555
üzenetére
> Egy pár mondatban összefoglalható, hogy mi az ellenszenv oka?
az én értelmezésem szerint a fragmentáció a legnagyobb problémája
.... a rengeteg AVX-512 variáció
https://en.wikichip.org/wiki/x86/avx-512#Implementation
... aminek nehéz a támogatása ...
meg összehasonlítva az ARM SVE2 -vel .. az AVX-512 .. gányolás...Az ARM-es SV2 bár késői szülés ... de alaposabban átgondolt mint az Inteles rögtönzés - és jobban skálázódik .. mobiltelefontól --- az ARM-es HPC -ig .. egy utasításrendszer ... amit bárhol lehet használni ...
későbbi e-mail -ben jobban kifejtette ...
-------------------------------
"Now, that said, do I hate MMX/SSE/AVX/AVX2 with the same burning passion as AVX512? No. Because there's a big difference between them.MMX/SSE was a first-attempt (plus fixes). The i387 was a particularly nasty thing to be compatible with anyway, it's entirely understandable why it was done the way it was done. In hindsight, maybe it could have been done better, but a "in hindsight" argument is always complete BS. So that's not a valid argument. MMX/SSE was fine.
AVX/AVX2 were reasonable cleanups and honestly, I don't think 256 bits is a huge pain even as a baseline. And Intel has been good about keeping AVX always there. Afaik, new CPU's really have gotten AVX reliably. So it hasn't been a fragmentation issue, and while I think it has the same state dirtying issue ("helper function using MMX instructions and saves/restores the instructions it modifies will be clearing upper bits in AVX registers and trashing state"), I think it was a fairly reasonable extension.
So again, AVX/AVX2 was fine. Was it "lovely"? No. But I think it's a reasonable baseline.
So what's different with AVX512?
One fundamental difference is that fragmentation issue. It came up before AVX512 was even out, with the failed multi-core Knights atoms having a completely different versions. But it's really been obvious lately, with even today, in CPU's being sold, it being a "marketing feature".
But the other - and to me really annoying - fundamental issue is "by now, you should have damn well have learnt from your mistakes".
Here, look at the real competition for Intel and x86 long-term: ARM. They had an equally disgusting and horrendously bad FPU situation originally. Yes, their FPU situation was differently bad from the i387, but the whole soft-FP vs VFP vs random other implementations was arguably worse than Intel ever had, even if at the time, you would find the usual ARM fanbois that made excuses for just how horrendous the situation was.
But then ARM got their act together, and NEON happened. I'd say that was roughly the equivalent to SSE, because I'll call the original mess of nasty shit comparable to the nofp/i387/IBM-mis-wiring-the-exception-pin/MMX era. The timing may not line up, but with NEON, ARM at least had gotten rid of their messy lack of standards, and I think it's fair to compare it to Intel and SSE conceptually.
So ARM did SVE, and I'll call that their AVX/AVX2. But now you see signs of differences. Part of it is just the name. "S" for "Scalable". ARM is starting to do something interesting and fundamentally different from what AVX was for Intel.
And then ARM designed SVE2, and again, let's see how it actually plays out in real life, but I think it has the potential to be their "AVX512 done right". And they designed it to have a reasonable downgrade/upgrade path, to be extensible, to do that masking and memory accesses etc that is so important for compilers to auto-parallelize.
Honestly, if I were into HPC and vectorization, I'd be all in on the ARM bandwagon.
As it happens, I'm not into HPC and vectorization, and it's possible that exactly because I'm not into it, I'm missing why SVE2 has some horrible problems. And I realize that AVX512 does some things that a very very very small minority of people care deeply about (I don't know why, but some people really love the shuffle instructions and will put up with absolutely anything if they get them).
So just as a bystander, I'm looking at AVX512, and I'm looking at SVE2, and I'm going "AVX512 really is nasty, isn't it"?
And by now it's the third big generation, and the "it wasn't clear what the right answer was" is no longer an excuse for doing things wrong. People knew that scaling up and down the CPU stack was an issue. This wasn't something where Intel couldn't have seen it coming - when Intel was designing AVX512, Intel was still trying to also enter the smartphone and IoT area.
Have I sufficiently explained why I absolutely despise AVX512?
And yes, maybe in five years, AVX512 is there everywhere and my fragmentation argument goes away.
Buy maybe in five years, SVE2 is everywhere too, and is happily working in cellphones and in supercomputers, and I think I won't be the only person in the room that says "AVX512 is a butt-ugly disgrace".
We'll see, even if it might take years. I'm happy to be proven wrong.
And I'm here for the heated technical discussion anyway. Tell me why I'm a pinhead and a nincompoop, and why SVE2 is so bad, and why AVX512 is clearly better.
Because this forum is about architecture design and implementation, isn't it? So I think it's very fair to put down that gauntlet: AVX512 vs SVE2. "Gong plays" - FIGHT!
Linus"
https://www.realworldtech.com/forum/?threadid=193189&curpostid=193248[ Szerkesztve ]
Mottó: "A verseny jó!"
-
#3557
S_x96x_S
őstag
Petykemano
#3555
S_x96x_S
őstag
válasz
Petykemano
#3555
üzenetére
> Mármint az ARMos SVE - túl azon, hogy ott dinamikus/változtatható
> a bithossz - mennyiben jobb?
> az SVE-t az armos oldalon istenítik.
ARM-es oldalon nem kell újrafordítani a szoftvert ..
ha 2048 bitesre megírod .. mögötte a hardver lehet 128 vagy akár 2048 bites ..vagyis a következő öt évre a szoftvereket a hardver automatikusan skálázza ... nem lesz olyan mint az X86 -oldalon, hogy mindig újra kell fordítani az AVX-512 ... majd az AVX-1024 .. vagy az AVX-2048 -ra ...
és ez az Apple oldalon nagy előny ...
mert támogatni fogja az SVE2 -öt.lesz egy gyenge mag ... ami 128 bites hardverre fordítja a 2028 bites utasításokat ..
és lesz egy erős mag ... ami 1024 bites hardver ...
és ARM-es oldalon a kettő között egyszerű az átjárás .. szoftveres kompatibilitás megvan ... könnyű hibrid CPU -t összerakni.------------------------------------------
mig most az Inteles oldalon a Hibrid cpu-knál erős és a gyenge mag két külön implementáció hardveresen és szoftveresen .. a gyenge nem tudja az AVX-512 -öt .. emiatt az erősön is le kell tiltani
mivel fontos a homogenitás az utasításkészletben ...
... szívás és hajtépés ....
Ahogy az AT -irta
https://www.anandtech.com/show/15877/intel-hybrid-cpu-lakefield-all-you-need-to-know/5"
The hair-pulling out moment occurs when a processor has two different types of CPU core involved, and there is the potential for each of them to support different instructions or commands. Typically the scheduler makes no guarantee that software will run on any given core, so for example if you had some code written for AVX-512, it would happily run on an AVX-512 enabled core, but cause a critical fault on a core that doesn’t have AVX-512. The core won’t even know it’s an AVX-512 instruction until it comes time to decode it, and just throw an error when that happens. Not only this, but the scheduler has the right to move a thread when it needs to – if it moves a thread in the middle of an instruction stream, that can cause errors too. The processor could also move a thread to prevent thermal hotspots occurring, which will then cause a fault.There could be a situation where the programmer can flag that their code has specific instructions. In a program with unique instructions, there’s very often a check that tries to detect support, in order to say to itself something like ‘AVX512 will work here!’. However, all modern software assumes a homogeneous processor – that all cores will support all of the same instructions.
It becomes a very chicken and egg problem, to a certain degree.
The only way out of this is that both processors in a hybrid CPU have to support the same instructions completely. This means that we end up with the worst of both worlds – only instructions supported by both can be enabled. This is the lowest common denominator of the two, and means that in Lakefield we lose support for AVX-512 on Sunny Cove, but also things like GFNI, ENCLV, and CLDEMOTE in Tremont (Tremont is actually rather progressive in its instruction support)."
Mottó: "A verseny jó!"
-
#3559
Petykemano
veterán
S_x96x_S
#3557
Petykemano
veterán
válasz
 S_x96x_S
#3557
üzenetére
S_x96x_S
#3557
üzenetére
De miért ne lehetne az AVX512-t, vagy későbbieket olyanná "tenni", hogy egy olyan cpu, ami csak AVX-et vagy AVX2-t tud, az azzal a vektormérettel végre tudja hajtani?
Van az AVX, AVX2, AVX256 és AVX512 között más különbség is, mint a vektorhossz?
Afelől nincs kétségem, hogy a jelenlegi AVX512 olyan, hogy erre nem alkalmas (még azt is el tudom képzelni, hogy ebben van némi szándékosság, hiszen az intel az utasításkészletekkel szegmentálta a piacot, lehetett az a policy, hogy ha a legjobb utasításkészlet kell, vedd meg a legdrágább terméket => ez persze meg is világítja a különbséget, hiszen az SVE2-ben ha jól értem az utasításkészlet megegyezik, és a hardver vektorhossz-képességével lehet szegmentálni. Az intel meg ezt összekötötte),
de úgyis nagy a fragmentáció, tehát kiemelkedhetne egy olyan (akár az AMD-től jövő?) ami az Armos irányt viszi és standarddé válik.
Találgatunk, aztán majd úgyis kiderül..
-
#3560
S_x96x_S
őstag
Petykemano
#3559
S_x96x_S
őstag
válasz
Petykemano
#3559
üzenetére
> De miért ne lehetne az AVX512-t, vagy későbbieket olyanná "tenni"
majd valamit az AMD kitalál ...
de amúgy nincs könnyű helyzetben ...
ha meg teljesen új dolgot csinál .. akkor csak a fragmentációt növeli ..én amúgy az AMD helyében az APU-s dolgot erőltetném ...
vagyis az AVX-512 -es utasításokat valami belső fordító áttolja a GPU részre .. és ott hajtódnak végre. persze ez a gyakorlatban nem biztos, hogy optimális ...ami érdekes az Raja - OneApi -ja ... ami automatikusan osztja el a feladatot a cpu és a gpu között ... szerintem ez lehet az Intel "B" terve ... az AVX-512 mellett ...
és ne felejtsük el a fejlesztés alatt álló Centaur Technology -s CNS -core ... ami szintén az AVX-512 -es piacra pályázik ...
> hiszen az SVE2-ben ha jól értem az utasításkészlet megegyezik,
> és a hardver vektorhossz-képességével lehet szegmentálni.
> Az intel meg ezt összekötötteigen .. az én megértésem is hasonló ..
Az ARM kód binárisan ugyanaz ..
mig az X86( Intelnél) ... nem lehet tudni, hogy az 1024 bites utasításoknak mi lesz a kódja ..
a 2048-asokat meg végképp nem .lehet tudni ..
míg az új ARM-es hardvereket rögtön ki tudják használni a szoftverek ..
az új Inteles AVX-1024 -es kódnál ez nem igaz .. . hasonló mint most az AVX-512 ... kevés program használja ki .. kell új fordító támogatás ... stb ...
nehezebb a hibakeresés és a debuggolás is ...--------------------
amúgy ha valaki nem érti az avx-512 fragmentációt annak itt egy ábra ..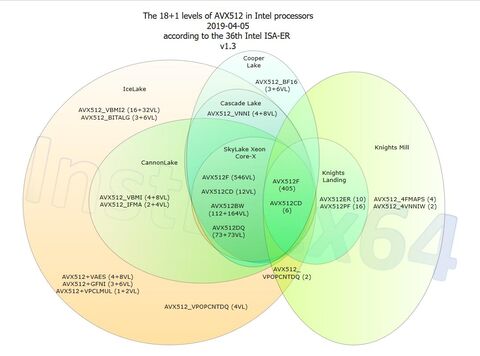
[ Szerkesztve ]
Mottó: "A verseny jó!"
-

Fred23
nagyúr
-
S_x96x_S
őstag
Linus ... AVX-512
avagy szépen spanyolul ... : Espero que el AVX-512 tenga una muerte dolorosamásképpen megfogalmazva ... az AVX-512 -ből nem lehet pici chipet csinálni .. nem lehet letranszformálni kis design-ra ... és ez a mobil felhasználást eleve megakadályozza
https://www.realworldtech.com/forum/?threadid=193189&curpostid=193209
"""
the problem with AVX512.
I'd argue that you simply can't put it in a smaller chip. Not while actually making it worth using. It wasn't designed that way.
Some of the AVX512 parts I like: intel did make things more generic with it. I think the masking stuff is new to AVX512, no?. But that's less about the width, and more about cleaning things up and making them more useful in general.
But I think the 512-bit part is a hot mess, and I think ARM potentially did things much better with SVE2. Exactly because hopefully you can have a small and large implementation co-existing, instead of the fragmentation that is the AVX world.
Are there any actual SVE2 chips and users out that validate that point? Not that I know. I haven't really followed it. But I appreciate people trying to do it right. Maybe SVE2 won't work out well, but at least ARM tried.
Not like Intel.
I'll give kudos to Intel when they do things well, and they do do many things well (well, used to, and I'm still hoping to see the old Intel come roaring back, because it's been so depressing lately). But I'll also point out when I think they've screwed up. AVX512 and transactional memory have been bad, I think. They've been bad both from a technical standpoint, but equally importantly from that "fragmenting the market" standpoint.Linus
"""Mottó: "A verseny jó!"
-
-
-

Balala2007
tag
válasz
Petykemano
#3559
üzenetére
Van az AVX, AVX2, AVX256 és AVX512 között más különbség is, mint a vektorhossz?
Marmint
- a plusz 16 regiszter (4x regiszterter)
- a +8 kreg es maszkolhatosag
- a szinte teljes adatortogonalitas es konvertalhatosag
- a disp8 tomorites
- az implicit blending/zeroing
- az implicit broadcasting
- a ternlog
- a rotalas/v rotalas
- a 2-source crosslane permutaciok
- a compress/expand
- a full popcnt
- az 8x8bit affin transzformacio
- scatter/gather-en kivul?Egy rakas FP cucc, de azt most nem mondom el.
AIDA64.com
-
#3566
Balala2007
tag
S_x96x_S
#3557
Balala2007
tag
válasz
S_x96x_S
#3557
üzenetére
GFNI be van kapcsolva a Lakefieldben, rossz az Anandtech cikk.
ARM-ra meg csak akkor nem kell ujraforditani, ha nem kell SVE2.1, SVE2.2 SVE3....-t hasznalni, ami az
SVE/SVE2 es ARMv8, ARMv8.1, ARMv8.2, ARMv8.3, ARMv8.4, ARMv8.5, ARMv8.6 utan azert nem egy keptelen gondolat.AIDA64.com
-
#3567
Balala2007
tag
hokuszpk
#3563
Balala2007
tag
válasz
 hokuszpk
#3563
üzenetére
hokuszpk
#3563
üzenetére
nemlehet nyomni ezen az AVX torteneten egy resetet ?
Maceras, SNB i7-2600 2011Q1-ben jelent meg, BDZ-ben AMD is atvette, Jaguar is tudja a konzolokban, Gracemont-ban lejon Atom-okra is...
Ez nem marginalis XOP, TBM, 3DNow!. vagy HLE, MPX, SGX, ez maga az x64
meg nincs olyan rengeteg avxet tamogato szoftver,
Ezt honnan lehet tudni? Sztem ez egyaltalan nem igaz, 10 ev alatt tortent ez+azAIDA64.com
-
#3568
hokuszpk
nagyúr
Balala2007
#3567
hokuszpk
nagyúr
válasz
 Balala2007
#3567
üzenetére
Balala2007
#3567
üzenetére
"Ezt honnan lehet tudni? Sztem ez egyaltalan nem igaz, 10 ev alatt tortent ez+az"
iden doglott ki a Phenom II alol a lapom, addig az volt "A" melos gep.
egy szoftver se jott szembe, ami reklamalta volna, hogy neki marpedig egetoen szuksege van az AVXre


[ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...
-
#3569
Petykemano
veterán
Balala2007
#3565
Petykemano
veterán
válasz
Balala2007
#3565
üzenetére
Értem
Egy laikussal beszélgetsz
Akkor nem lehetne ez(eket) úgy megcsinálni (reset?) hogy van az
AVX, AVX2, AVX3 - ami utasításkészlet
És tartozik a képlethez még maximális vektorhossz is, ami meg hardveres implementációHa jól értem, az SVE2 esetében is előfordulhat, hogy lesz SVE2.1, SVE2.2
Nyilván ezek azonban mind 128-2048 vektorhosszúságig ugyanúgy jók lesznek.Azt gondolom, hogy a kis és nagymagok közötti szegmentálási lehetőség az ARM-os megoldással (vagyis hogy az utasításkészlet megegyezik a kis és nagy magok között, viszont a feldolgozó szélessége nem) rugalmasabb. Ha az intel nem csinálna hibrid cpu-t, lehet, hogy ez a kérdés fel sem merülne. Hogy látod, lehetne-e, vagy érdemes lenne-e az AVX család következő verzióját már így készíteni?
Vagy lesz egy hátraarc és GPU?
Egy laikussal beszélgetsz
Találgatunk, aztán majd úgyis kiderül..
-
#3570
 Ueda
senior tag
Balala2007
#3567
Ueda
senior tag
Balala2007
#3567
Ueda
senior tag
válasz
Balala2007
#3567
üzenetére
Esetleg amire az avx képes, azt meg lehetne oldani több maggal is. Konkért példa, x265 kódolás, 4 mag avx2-vel vagy 6 mag avx/2 nélkül. Az utóbbi kombináció rugalmasabb,kvázi "RISC architektúra". De én is csak laikus vagyok, szóval nem tudom, mennyire felcserélhető a avx/2 a több magokkal.
OS : EndeavourOS KDE . . . . . . Parancs menü : https://pastebin.com/u/txt444
-
#3571
Balala2007
tag
hokuszpk
#3568
Balala2007
tag
-
#3572
hokuszpk
nagyúr
Balala2007
#3571
hokuszpk
nagyúr
válasz
Balala2007
#3571
üzenetére
nalatod. pont az a jo, ha mindennek van non-avx codepathja.
bazinagy piros resetgomb megynyom, es megis mukodik minden tovabb, csak amig lemegy az atallas, picit lassabban.[ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...
-
Konkért példa, x265 kódolás, 4 mag avx2-vel vagy 6 mag avx/2 nélkül
Ez Sse4.2 vs Avx2? Mert ebben az esetben az Avx2 alternatívája (Sse4.2) is vektorkód. Az 50%-os gyorsulás pedig kb hihető az Avx regiszretek szélességéből (+100%) adódóan.
Ha az Avx2 "alternatívája" a sima skalár kód, akkor nem, nem tudod /aligha tudod több maggal a vektorkódot helyettesíteni. Nem branchelő/branchelést kiküszöbölő kódnál akkora gyorsulást tud hozni az Avx2, hogy egy Avx-es szál lenyomhat nyolc skalárt.
A kérdés nekem az, hogy az Avx512 ad-e annyi plusszt az Avx2-höz képest, hogy az alkalmazásfejlesztőnek megérje a vesződséget.
[ Szerkesztve ]
-
S_x96x_S
őstag
Google’s new Confidential Virtual Machines on 2nd Gen AMD EPYC
"Secure Encryption Virtualization in AMD’s 2nd Gen EPYC processors allows cloud providers to encrypt all the data and memory of a virtual machine at the per-VM level. These are generated on-the-fly in hardware, and are non-exportable, reducing the risk of side attacks by potentially aggressive neighbors. Previously this sort of computing model was only possible if a host assumed control of a whole server, which for most use cases isn’t practical.
...
With SEV2, technically AMD allows for up to 509 keys per system. Google will offer images for its cVMs with Ubuntu 18.04/20.04, COS v81, and RHEL 8.2; other operating system images will be available in due course."https://www.anandtech.com/show/15909/googles-new-confidential-virtual-machines-on-2nd-gen-amd-epyc
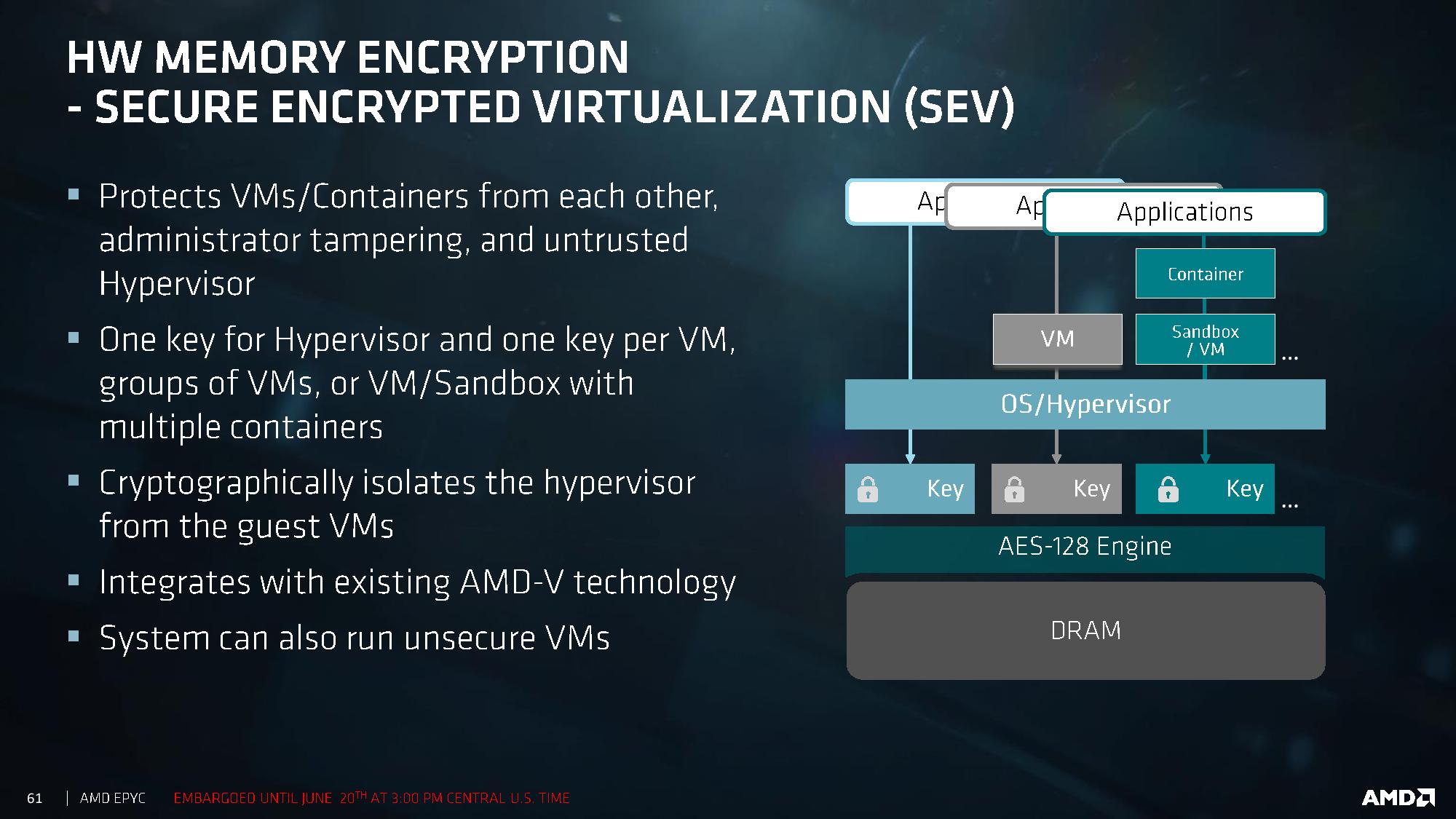
+
https://cloud.google.com/confidential-computing
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
STH-s értelmezés:
"Google Cloud Confidential Computing Enabled by AMD EPYC SEV"
https://www.servethehome.com/google-cloud-confidential-computing-enabled-by-amd-epyc-sev/
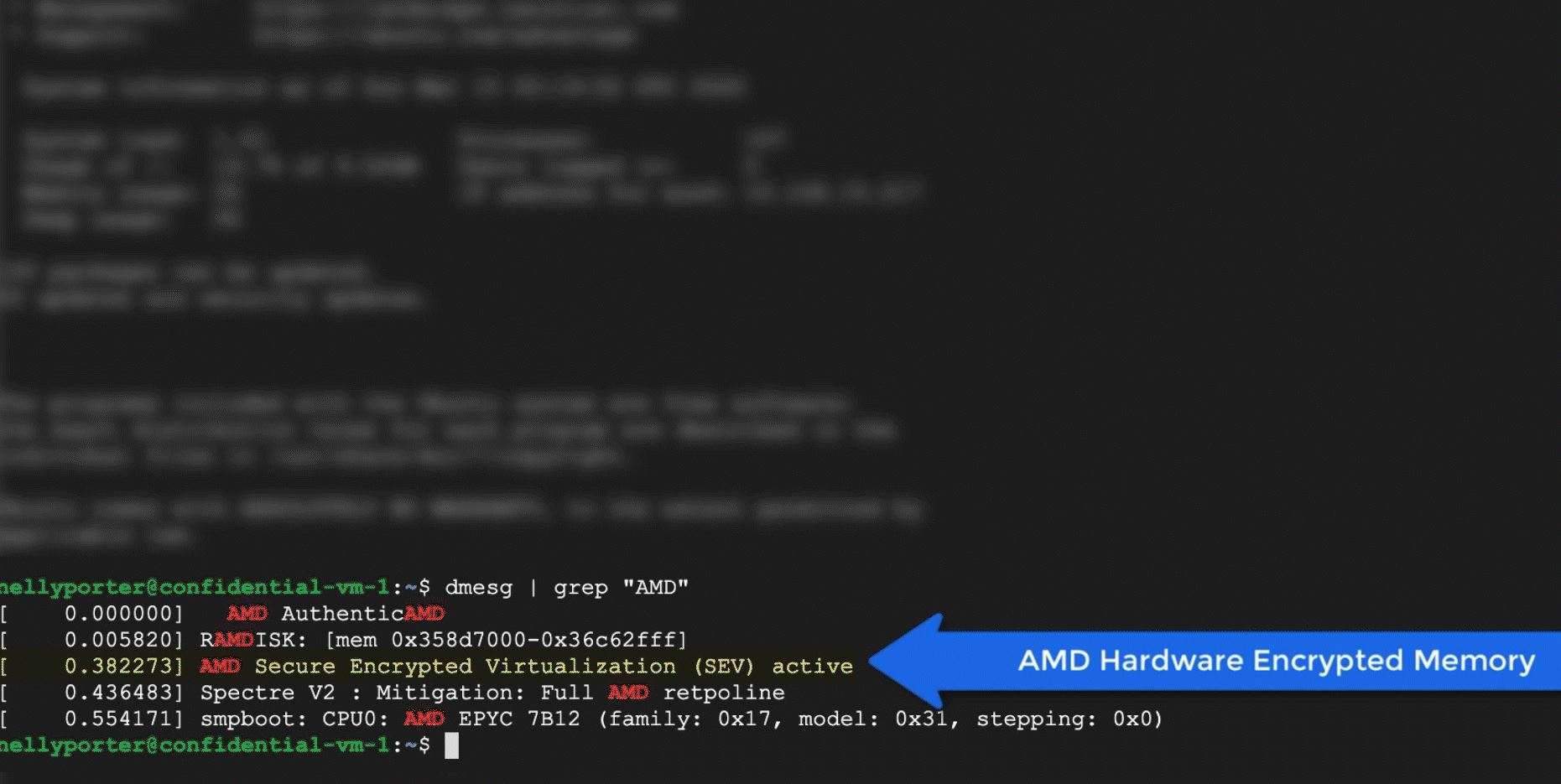
ez a trend eleje ... jönnek majd az Intel-es titkosítások is ..
"Confidential computing is still in its early days. Looking beyond this announcement, we fully expect that this will become more commonplace in public clouds within the next 18-24 months. Beyond AMD’s “Rome” today and the next-gen EPYC 7003 “Milan” chips, we expect Intel to expand SGX functionality and memory encryption in Ice Lake Xeons as they round out the 3rd gen Intel Xeon Scalable lines. There are also non-x86 vendors working in this space. As we see the hardware proliferate to make this possible, we expect confidential computing to be more commonplace. It is great to see Google forging ahead early in the capability lifecycle here."
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
"AMD Ryzen 9 3900XT Memory Scaling Performance Under 100 Different Tests"
https://www.phoronix.com/scan.php?page=news_item&px=Ryzen-9-3900XT-DDR4-MemoryMottó: "A verseny jó!"
-
thgergo
tag
válasz
 joysefke
#3573
üzenetére
joysefke
#3573
üzenetére
Értelmezésem szerint az SSE, AVX stb vektorműveleteknek előnye akkor van, ha a skalár kódban néha néha szükség van vektorműveleteket letudni. Különben ott a GPU/Xeon phi vagy másegyéb gyorsító a célfeladatra pl FPGA.
Pl. Egy vektorművelet offloadja pl gpu-ra: ~8000 ns legalább.
Persze lehet, ugyanez egy APU-nál csak 100-500 ns, de erről nem találtam sehol adatot.
Egy L1, L2, L3 cache lényegesen jobb, 3...20 ns, AVX műveletekkel is! DRAM is 100-200 ns...
Más:
AVX2 és AVX512 kód között csak pár % teljesítményelőnyt tapasztaltam, intel MKL, cascade lake csodákkal. Feltehetően azért, mert az 512 bit széles AVX unit képes egyszerre két db 256 széles AVX2 végrehajtására is... Tehát az igazi előny így elveszik, hagytam a csodába az AVX512 kódot innentől fogva.Linus @ AVX-512:
Van az AVX512-nak további fregmentációja is. Az intel össze vissza mesterségesen letiltogatja az AVX512 képességeket, drágább termékek felé terelve az embereket:
Xeon Scalable Bronze, Silver, és Gold 5000: 1 db AVX FMA egység
Xeon Scalable Gold 6000, 8000, 9000: 2 db AVX FMA egység
Core i9-ként brandelt verziókban mégis engedélyezve van a 2 db AVX FMA unit (!)[ Szerkesztve ]
-
-
válasz
thgergo
#3577
üzenetére
Különben ott a GPU/Xeon phi vagy másegyéb gyorsító a célfeladatra pl FPGA.
Ezt nem tudom, azokat még játék szinten sem programoztam soha (SSE-AVX-et intrinsic-kel igen, hobbiból megvalósítottam pár egyszerűbb képfeldolgozó algoritmust) mindenesetre szerintem arra nem lehet építeni, hogy a usernek majd pont lesz megfelelő GPU-ja és arra pont van megfelelő driver installálva. Ezzel szemben, a legalább SSE 4.2 vagy akár AVX képes processzor az adott.
==
AVX2 és AVX512 kód között csak pár % teljesítményelőnyt tapasztaltam, intel MKL, cascade lake csodákkal.Én még azt olvastam, hogy bár az Avx512 kód lehet akár gyors is, azonban ha csak kevés Avx512 utasítást kell végrehajtani, akkor könnyen elmarad a gyorsulás (vagy még lassul is) mert az Avx512 kód alacsonyabb órajelen fut és utána viszonylag hosszú időre (~ms nagyságrend) van szükség, hogy visszaugrojon az órajel, tehát azon a szálon az Avx512 utasítások utáni kódrészlet lényegesen lassabb lesz, mintha nem Avx512 futott volna előtte.
Na most ha ez így van, akkor ennek fényében, a fenti utasítás halmazábra fényében és annak fényében, hogy az egyes processzorok még különböző számú Avx512 képes egységet tartalmaznak, ki fogja érdemben kitsztelni/eldönteni, hogy egy adott függvény esetén melyik processzorcsalád melyik kódutat futassa? Nekem ez laikusként aránytalan munkának tűnik ahhoz képest, hogy mekkora gyorsulásra lehet elméletben képes az Avx512.
Vagy Avx512 eleve csak szuperszámítógépek esetén lesz hasznos, ott meg majd megírják a kódot az adott processzorhoz?

[ Szerkesztve ]
-
S_x96x_S
őstag
hivatalos oldal:
AMD Ryzen™ Threadripper™ PRO 3000WX Series Processors
https://www.amd.com/en/processors/ryzen-threadripper-pro+ egy hivatalos video https://www.youtube.com/watch?v=rQj4PJvPFeU
Mottó: "A verseny jó!"
-
#3583
S_x96x_S
őstag
Petykemano
#3582
S_x96x_S
őstag
válasz
Petykemano
#3582
üzenetére
Amúgy az STH keresztelte el WEPYC-nek
https://www.servethehome.com/amd-threadripper-pro-is-a-workstation-epyc-or-wepyc/Mottó: "A verseny jó!"
-
S_x96x_S
őstag
"The Linux Performance For AMD Rome vs. Intel Cascade Lake One Year After Launch"
https://www.phoronix.com/scan.php?page=article&item=rome-cascade-2020&num=1"When taking the geometric mean of all 116 benchmark results, the AMD EPYC 7742 2P with the newer "2020" software stack (Ubuntu 20.10 daily + GCC 10 + Linux 5.8) yielded a 4% improvement to the system performance. The Xeon Platinum 8280 2P saw a 6% improvement with the upgraded software. For these over 100 tests run, the AMD EPYC 7742 2P on the latest Linux software packages yielded 14% better performance over Intel's top-end non-AP Xeon Platinum 8280 dual socket server."
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
ilyen is ritkán van .. AdoredTV hűti a várakozásokat ..
szerinte nem lesz +50% lebegőpontos teljesítmény növekedés a ZEN3-nál ..
az "5.3 petaflops" -alapján visszaszámolva
https://adoredtv.com/confirmed-zen-3-will-not-have-50-higher-floating-point-performance/A tegnapi postja
"EXCLUSIVE: ZEN 3 TO FEATURE OVER 20% HIGHER INTEGER PERFORMANCE THAN ZEN 2, PRODUCTION IN SEPTEMBER"
https://adoredtv.com/exclusive-zen-3-to-feature-over-20-higher-integer-performance-than-zen-2-production-in-september/Mottó: "A verseny jó!"
-
S_x96x_S
őstag
AsrockRack - mini DTX - SP3 ..
( via )
Ultra Compact EPYC7000 Server Board with Dual 10GbE
- CPU Socket SP3 (LGA4094), supports AMD EPYCTM 7002 Series Processors
- Memory Capacity 4DIMM Slots (1DPC); Supports DDR4 R-DIMM up to 3200MHz, 64GB/ LR-DIMM up to 3200MHz, 256GB
- Expansion PCIe slot 1 PCIe4.0 x16
- M.2 1 M-key (PCIe4.0 x4 or SATA 6Gb/s), supports 2280 form factor
Mottó: "A verseny jó!"
-

HookR
addikt
válasz
S_x96x_S
#3586
üzenetére
"So they said fitting an AMD Epyc on a mini-ITX motherboard was impossible..."
Az állításra ezzel még nem sikerült rácáfolni. Se nem Mini-ITX, se nem Mini-DTX. Bár tény, hogy a méretei alapján (170 x 208 mm) közel van a Mini-DTX-hez (203 x 170 mm), csakhogy annál a magasság a nagyobb, nem a mélység.▌www.thunderbolts.info | youtube.com/ThunderboltsProject ▌16personalities.com▐
-
S_x96x_S
őstag
kíváncsi leszek, hogy lesz-e idén az AMD-nek
5nm-es terméke a TSMC-vel gyártva .. [1]
Mindeközben a Samsung küszködik az 5nm-el. [2]Nem könnyű azért ..
------------
[1] "TSMC expects to see 5nm process technology account for about 8% of its total wafer revenue in 2020, compared with the about 10% estimated previously. " ( Friday 17 July 2020 )
( https://www.digitimes.com/news/a20200717PD201.html )[2] Samsung struggling to improve 5nm process yield, say sources https://www.digitimes.com/news/a20200720PD203.html
[ Szerkesztve ]
Mottó: "A verseny jó!"
-
S_x96x_S
őstag
nézegetve a német DIY CPU eladási statisztikát
a Ryzen XT procikból nem nagyon lesz tömegtermék ..
( persze lehet, hogy ez még csak tört hét ..az XT -k szempontjából )
pár hét múlva újra ránézek ..
https://twitter.com/TechEpiphany/status/1284800864490848257Mottó: "A verseny jó!"
-
S_x96x_S
őstag
Kütyü ... Ryzen Embedded SoCs : EFCO’s “VideoStar100”
+ "SecuBoot security solution. Billed as “the most advanced security available for digital displays,” SecuBoot prevents malicious applications introduced via the Internet or USB devices during the boot process. The algorithm includes BIOS Lock, Device Verification, Storage Checksum, and Whisper Talk features."
"You get 4x 4K-ready DisplayPorts on the dual- or quad-core V1000-based VideoStar100-V and 3x DP on the dual-core R1000-based VideoStar100-R for 4x or 3x simultaneous displays, respectively. In either case, there are dual DDR4 slots for up to 32GB RAM: 3200MHz for the VideoStar100-V and 2400MHz for the VideoStar100-R."
http://linuxgizmos.com/ryzen-embedded-signage-system-offers-secure-boot/

Mottó: "A verseny jó!"
-
S_x96x_S
őstag
az nem jó hír, hogyha csak OEM-eknek ...
persze majd meglátjuk "holnap" ( amikor publikus lesz a hír ) ...
-------------
We can now confirm that tomorrow AMD will announce three Ryzen 4000G non-PRO processors.
AMD Ryzen 4000G for pre-built OEM system
https://videocardz.com/newz/amd-to-announce-ryzen-7-4700g-ryzen-5-4600g-and-ryzen-3-4300g-for-oem-systemsMottó: "A verseny jó!"
-
#3593
Petykemano
veterán
S_x96x_S
#3592
Petykemano
veterán
válasz
S_x96x_S
#3592
üzenetére
Abunak volt pár hete egy cikke arról, hogy az AMD-nek összefolytak a termékek és abban gondolkodik, hogy egy-egy műsor/rendezvény keretében tudja le a mainstream cpu és gpu és a szerver cpu és gpu rajtokat.
Ennek fényében vajon kapacitás korlátok miatt (chip? vagy doboz?) maradt ki a dobozos Renoir verzió rajtja vagy azért, mert összekötik a Ryzen 4000 többi részének rajtjával?
Találgatunk, aztán majd úgyis kiderül..
-
#3594
S_x96x_S
őstag
Petykemano
#3593
S_x96x_S
őstag
válasz
Petykemano
#3593
üzenetére
nem tudom ... én is találgatok magamban ...
viszont találtam már rendelhető APU-kat .. árral ...
és valamiből 2 verzió is van ( MPK =?= dobozos )
https://prohardver.hu/tema/re_teritette_az_amd_az_asztali_ryzen_soc_apu-kat/hsz_29-29.htmlremélem ez alapján csak valami OEM-es szivesség .. és 1 hónapon belül mindenkinek elérhető.
Mottó: "A verseny jó!"
-

wwenigma
Jómunkásember
Ryzen 7 Pro 4750G DDR4-6234 [link]
Steam: http://bit.ly/1rRuf8p , Origin: wwenigma -- | -- Jiayu F1 / G3C / OT995 cuccok: http://bit.ly/1w44CI2 -- | -- ZTE V5 Red Bull -> http://bit.ly/1mgtfrd -- | -- Xiaomi RN3SE -> http://bit.ly/2r8DlV7 -- | -- Live Stream: twitch.tv/wwenigma
-
S_x96x_S
őstag
uborkaszezon ..
Ha az nVidia felvásárolja az ARM-et ..
akkor az eléggé átrendezi a CPU piac jövőjét ... és az X86 - jövőjét is.
( egyes internetes vélemények szerint ez se az Apple-nek se az AMD-nek nem jó hír ... )Nvidia expresses interest in SoftBank's chip company Arm Holdings: Bloomberg News
https://www.reuters.com/article/us-arm-holdings-m-a-nvidia-idUSKCN24N2P1[ Szerkesztve ]
Mottó: "A verseny jó!"
-

Cathulhu
addikt
válasz
S_x96x_S
#3596
üzenetére
nem tudom a hatosagok ezt hagynak-e oszinten. tul sok tul meghatarozo ceg fugg az ARMtol, hogy az nvidia diktaljon folottuk. Mintha mondjuk az apple megvenne a TSMC-t.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
S_x96x_S
őstag
válasz
 Cathulhu
#3597
üzenetére
Cathulhu
#3597
üzenetére
nézegetve az egy hetes hírt[1] .. úgy néz ki, hogy a SoftBank nagyon pénzt akar csinálni ... és úgy gondolhatja hogy mostanra kell időzíteni
( miután bejelentette az Apple a váltást ? )
Szerintem az Apple lehet az akinek van pénze és fontos lehet még ...
talán fel akarja tornázni az árakat ...A másik lehetőség, hogy kimegy tőzsdére ( IPO ) mint a többi cég.
-----------------------
07.14.2020 ( ~ 1 hete )
"Softbank is said to have been weighing the possibility of holding an initial public offering (IPO) for Arm Holdings, but now there’s said to be at least one company out there that wants to straight-up buy Arm from Softbank."
[1]
https://www.eetimes.com/softbank-said-to-have-a-buyout-offer-for-arm/#Mottó: "A verseny jó!"
-
#3599
Petykemano
veterán
S_x96x_S
#3598
Petykemano
veterán
válasz
S_x96x_S
#3598
üzenetére
Vajon miért most akar pénzt látni ebből a softbank?
Annyira jön föl a RISC-V?
Vagy csupán megirígyelte a softbank Azokat a cégeket, amelyek a fed által nyomtatott pénzt nem munkahelyek megőrzésére fordítják (mivelhogy növekvő munkanélküliség, bedőlő ágazatok miatt csökken a kereslet, így rossz befektetés lenne beruházni, vagy termelést felfuttatni, arra meg semmi szükség hogy valaki malmozzon), hanem saját részvényeket vásárolnak. Ezzel látszólag szárnyal a tőzsde, emelkedik a részvényárfolyam, mehetnek a bónuszok, meg hát ha időbeni szállsz ki, realizálhatod a nyereséget.
?
Találgatunk, aztán majd úgyis kiderül..
-
#3600
S_x96x_S
őstag
Petykemano
#3599
S_x96x_S
őstag
válasz
Petykemano
#3599
üzenetére
> Vajon miért most akar pénzt látni ebből a softbank?
Talán mert kompenzálni akarja a WeWork, Uber veszteségeket ..
https://www.bloomberg.com/news/articles/2020-05-18/softbank-vision-fund-books-17-7-billion-loss-on-wework-uberMottó: "A verseny jó!"





























Új hozzászólás Aktív témák

- EDIFIER R1700BTS hangfal pár makulátlan, új állapotban, 2 év hivatalos garanciával, alkalmi áron
- LG OLED55B23LA 2 Év GYÁRI GARANCIA
- Apple iPhone XR 128GB, Kártyafüggetlen, 1 Év Garanciával
- Gamer PC , i7 12700KF , RTX 3080 Ti , 64GB DDR5 , 960GB NVME , 1TB HDD
- Intel PC , i5 8500 , 1660 6GB , 32GB DDR4 , 512GB NVME , 500GB HDD
- D-Link DIR-842 kétsávos, Gigabites router - Foxpost az árban!
- H96 MAX RK3318 TV okosító - 2/16 GB - Új!
- MacBook Pro 13" 2016, i5 2.0GHz, 8GB Ram, 256GB SSD - rossz saját képernyővel, occón!
- Logitech G502 X vezetékes gaming egér, fehér, akár 25600 DPI
- Garett GRC Maxx okosóra, fekete, Android és iOs kompatibilis
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: Ozeki Kft.
Város: Debrecen