- Huawei P30 Pro - teletalálat
- Tényleg jobban fogyaszt a Peugeot, az Opel és a Citroen?
- MIUI / HyperOS topik
- Xiaomi Redmi 4X - Mi-ért hagytál el engem?
- Mobil flották
- Android alkalmazások - szoftver kibeszélő topik
- Vodafone mobilszolgáltatások
- Ford SYNC 3 infotainment rendszer teszt
- Samsung Galaxy Watch (Tizen és Wear OS) ingyenes számlapok, kupon kódok
- Huawei Mate 40 Pro - a csúcson kell abbahagyni?
Hirdetés
-


Letartóztatták, mert AI segítségével csalt az egyetemi vizsgán
it A török hatóságok letartóztattak egy diákot, amiért egy egyetem felvételi vizsgáján AI segítségével válaszolt a kérdésekre.
-


Végre pontos megjelenési dátumot kapott a Visions of Mana
gp A készítők tisztázták azt is, hogy PlayStation 4-re megjelenik-e a végső kiadás.
-


Elnéztük a mai dátumot
ma Nem holnap, ma mutatkozik, pontosabban mutatkozott be a HTC U24 Pro, csak elnéztük (mármint én) egy nappal a dátumot.






-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

P.H.
senior tag
válasz
 atti_2010
#7693
üzenetére
atti_2010
#7693
üzenetére
Amit leírtál, törvényszerű.
Azt viszont érdemes hozzászámolni, hogy a AMD-k alapfesze (pár kivételtől eltekintve) 1.25-1.4 között mozog a 90 nm-es generációk óta, és ez úgy néz ki, a Bulldozer-rel sem fog változni.
Ez lehet akár SOI-sajátosság, akár kidolgozatlanság is, ki tudja.Viszont az Intel-nél az alap(mag)órajel közelében vagy felette tud dolgozni az L3 már régóta, AMD-nél viszont csak alatta, nyilván ez nem normális helyzet.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
 Oliverda
#7695
üzenetére
Oliverda
#7695
üzenetére
Tudom nagyon jól, hogy mennyire különbözik a K10(.5)-ek L3 cache-e az Intel-étől.
(És nagyjából sejthető, mit fog tudni a Bulldozer-é [link])Az egyszerűbb gyárthatósággal és az alacsonyabb fogyasztással a linkelt ábra áll szemben

[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
 Hakuoro
#7905
üzenetére
Hakuoro
#7905
üzenetére
Annyira nem meglepő, az FPU a nagy fogyasztó (pl. azt bővítik most több, mint 100 utasítással, az integer-egységeket 10-20-szal).
Illetve mindenhol arról beszélnek, hogy a Turbo megnöveli az (integer-)magok (Core) órajelét. Nem a modulokét, azaz az FPU-ét nem (ha már ez az AMD-s nevezéktan). Így megvan a dezz által emlegetett (double-pumped helyetti) eltérő órajel is modulon belül.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
 Remus389
#8095
üzenetére
Remus389
#8095
üzenetére
Kihagytad a számításból
- a platformosodást
- a jövőbeli AMD VGA-kal való továbbfejlesztett együttműködés lehetőségét
- azt a többséget, aki továbbfejlesztés helyett teljes gépet vesz/cserél pár éventeAz ár tekintetében a kompatibilitás sokaknak jó, de a nyújtott teljesítmény (esetleg ennek fölénye) pedig még többeknek. A gyártónak meg az, ha minél több(fajta) terméket értékesíthet ilyen címkékkel (lehetőleg minél többet ugyanabba a gépbe).
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
Remus389
#8583
üzenetére
"nekik jön az Ivy Bridge és annak herélt változatai van még SSD project is, aztán slussz(legalábbis így hirtelen), és erre van 8x annyi ember és sokkal több zsé, meg gyárak meg minden"
Ha már ilyen olcsó összehasonlításokkal jössz "így hirtelen", hogy 1 milliárd tranzisztorhoz mennyi ember kell, akkor oda kellene számolni az Intel-nél a kb. 10 éves Itanium-ot (most épp 3 milliárd tranzisztornál tartanak) és a jó pár éve fejlesztett Larrabee-családot is. A cég SSD-i legalább kimutatható nyereséget termelnek már a megjelenésük óta...
nem is tudom valamikor olvastam hogy az egyik negyedévben(vagy évben) az Intel kábé 10.000.000.000, vagyis tiz milliárd profittal zárt, míg az AMD -300 millióval
ennek tükrében azért kisebbfajta csoda lenne ha a Bull technikailag megverné az InteltEnnek tükrében az is kisebbfajta csoda, hogy az Intel még nem áll a grafikai és a szerverpiac csúcsán...
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
"azért ha egy cég ennyi pénzt tud ölni egy projectbe másik meg nemtudom tizedannyit, kisebbfajta csoda lenne ha az AMD "nyerne" a csúcscpuk csatáját"
Szerintem egyértelműen, hogy Remusz911 miről beszélt: a teljesítményről.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
 #95904256
#8731
üzenetére
#95904256
#8731
üzenetére
A Haswell-lel kapcsolatban nem lennék biztos a dologban, annak a microarch-váltásnak arról kell szólnia, hogy a belső RISC uop-ok tudjanak kezelni 2-nél több bemeneti register-értéket (FP) illetve 1 EFLAGS-mezőt + legalább 2 register-értéket (INT) bemenetként.
A 2 register vagy 1 register + 1 EFLAGS bemenetre vonatkozó uop-megkötést úgy tűnik, még mindig hordozza a legújabb generációjuk is (eléggé régóta, talán P6 óta), belül: +1 közvetlen érték mint bement lehet emellett, kimenet lehet 3., átnevezett register.(Ennél többet ellenük nem nagyon lehet felhozni a Sandy Bridge ellen amúgy
)Ezt mindenképp meg kell lépniük a Haswell-nél, pont az FMA-jellegű dolgok miatt: a többi ilyen utasításnál a hátráltató hatást, azaz hogy 1-nél több uop-ra fordulnak, sikeresen elrejtették a kisebb (Nehalem) - nagyobb (Sandy Bridge) uop-cache-ekkel. Ezzel viszont egyidejűleg felgyorsítják az ADC/SBB, CMOVcc vagy akár a BLEND-utasításokat is.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
#95904256
#8736
üzenetére
2 évvel ezelőtt is másról beszéltek az azóta sem implementált FMA megvalósításukkal kapcsolatban, mint ami most várható
Náluk attól függ még (jelen pillanatban is, és még pár hónapig), hogy mit lesz szükséges megvalósítani a konkurencia ellen: az utasításkódolás adott (VEX) és a fejlesztés mindenképp szükséges belül. Az FMA3-hoz ugyanúgy 3 bemenet kell, mint az FMA4-hez, és minden jel arra mutat, hogy jelenlegi generációban nem rendelkeznek az ehhez szükséges belső felépítéssel.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
 Zeratul
#9788
üzenetére
Zeratul
#9788
üzenetére
Lényegtelen, hogy csak az egyik ALU tud szorozni és egy másik tud csak 2 spec. műveletet végrehajtani, ha a további több, mint 50 utasítás végrehajtásában mindegyik részt vehet.
K10-en 3 ALU+3 AGU felállással egyszálas integer kódban ki lehet hozni folyamatos (több 10 perces) 2.5 IPC végrehajtást, ugyanaz a kód Bobcat-on 2 ALU+2 AGU-val 1.5 IPC-vel fut. Ezt a hátrányt kell órajellel kompenzálni.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
Zeratul
#9792
üzenetére
Mondjuk minden olyan programban, amelynek bizonyos részei kézzel optimalizáltak.
Pl. egyszerűbb, minden programban használt szubrutinok (memóriamásolás) vagy nagy időigényű algoritmusok.Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
Zeratul
#9795
üzenetére
A programozók nagyon kicsi része, mivel a fordítókhoz a funkciókönyvárakat, library-ket, illetve az általánosan és gyakran használt algoritmusokat jellemzően kis csoportok vagy maguk a cégek készítik.
Azokban a programokban, amelyekben szükség van kézi fejlesztésekre, azokban ezek messze a leggyakrabban futó részek (pl. videokonvertálás, karakterfelismerés).
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
"Ki lehet, ki lehet, de az átlagos kód 1.0 körüli IPC-vel fut, ugyebár."
Azt vedd figyelembe, hogy az IPC-maximum nem a plafon meghúzását jelenti, hanem annyival vissza is skálázódnak a kódok. Tehát ha egy integer algoritmus 2.5 IPC-vel fut K10-en, ami 80%-os kihasználtságát jelenti az elméleti maximumnak, akkor 2 ALU+2 AGU-val ugyanez a kód nem fog 2.0 IPC-vel futni, mert ott a vége, hanem ugyanúgy kb. 80%-os kihasználtsággal, 1.5 körül. Ez visszaszámolható 1.0 IPC-s kódokra is.
(Hangsúlyozom, csak tiszta integer kódok esetén áll ez a "szabály", a valóság sokszor igazolta).Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
"Nagyon ritka, hogy 3 független utasítás jöjjön egymás után... Összetettebb számításoknál eleve 1.0 alatt szokott lenni az IPC. Többet számít a front-end, pl. elágazásbecslés."
Az eleje abszolút nem igaz és lényegtelen is, a vége csak részben igaz.
Kis, 10-15 utasításnál kisebb ciklusoknál (mert igazából ciklusokról beszélünk) irreleváns, hogy milyen függőségek vannak az utasítások között, nem in-order felépítésről beszélünk. A lényeg, hogy minél kevesebb felesleges és random memóriahivatkozás (L1- és L2-miss) legyen és hogy a front-end minél gyorsabban indíthassa a következő ciklust (itt számít OoO esetén is az utasítássorrend és az utasításválasztás, azaz hogy hány - fused - uop egy-egy utasítás).
15-20 utasításnál nagyobb, nem kiszámítható memóriahozzáféréstől mentes ciklusból bármikor mutatok neked olyat, ahol akár egymást követő 3 utasítás független, csak bírja a végrehajtás szusszal és a Reorder Buffer hellyel.A front-end és az elágazásbecslés a felépítés szélességének fele (1.5-2.0) felett kezd el csak számítani, de az már jó, ha egyáltalán eljutottál oda. Ezek nem apró lépésekben, hanem 0.25-0.5 IPC-közzel csökkentik a sebességet.
»Általában« az 1.0 tetőt a felesleges illetve az előre nem kiszámítható memóriahozzáférések okozzák, az pedig nem asm szinten dől el.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Mire gondolsz, mi lenne így miért? A front-end sosem erőteljesebb a végrehajtási résznél, a back-end van mindig túlméretezve. Vagy láttál ellenkező példát valahol?
A blogom teli van PerfMonitoros tesztekkel, gondolom, csak figyelmetlenség miatt "ajánlod".
Az Intel HyperThreading-ével mostanában nincs baj, főleg nem a Sandy Bridge-ével. x86 CPU-fronton az a legjobb microarch, ami piacon van jelenleg, és nemigen lehet rajta (ki)fogást találni. Az Ivy Bridge még tovább csökkenti majd a fogyasztást és mobil performance processzor témában tarolni fog (pl. beérik a régi-új uop cache hatása). Hogy ez többet ér-e általánosságban rövid távon, mint az AMD GPU-ja, az majd kiderül.
"Természetesen reordering után értettem, és nem szám szerűen, hanem átlagban."
Ennek így nincs se füle, se farka. Az IPC szigorúan véve az órajelenként végrehajtott, befejezett utasítások száma, ami egyszerű esetben vagy 0 vagy a felépítés szélessége. Ezt árnyalja az AMD double decode (ahány uop-ra dekódolsz órajelenként, annyi fog majd órajelenként befejeződni, de utasításonként lehet 2 uop is) és a macro-fusion, az x86-utasítások összevonása.
Nem szigorúan véve pedig az órajelenként befejezett utasítások számának átlaga egy időszakban (pl. 50 ms)[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
"A külön L3 miatt a CPU és a GPU közötti adatcseréhez igénybe kell venni a külső memóriát, ami nem igazán kedvez a heterogén programozásnak..."
Miért is kell? A GPU L3-része ugyanúgy egy szelete lesz a nagy közösnek, mint a többi magé.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Ebből a "A procimagok nem tudnak majd belőle olvasni." nekem új. Ha ez így van, akkor miért hívják L3-nak, miért nem szimplán IGP L2-nek? A késleltetése miatt, vagy amiatt, hogy milyen CPU-cache-sel van egy szinten, vagy miért?
Az SB IGP-je azért volt újszerű, mert a CPU-k L3-ába írhatott, és onnan olvashatott is, Carmack ezért szerette, és emlegette más is, mint "tighter integration"-t, nem? A következő generációban miért lépnének ettől vissza?
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Ebben csak az sántít, hogy az LLC a Last Level Cache rövidítése, ami az L3. Így meg szóhasználatban ferde a dolog.
És az IB slide-okon én (ami nekem hozzáférhető) L3$-t látok, pl.
L3$ lowers bandwidth needed from Ring Architecture
Media Applications benefits from infrastructure changes in EU/L3$/etcA média-alkalmazások hogy tudnak profitálni abból, hogyha az IGP L3-a teljesen különálló egység? (És mekkora ez amúgy?)
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Akkor ez is megvan, gondolom:
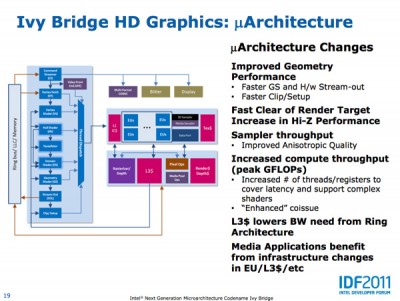
Meglátjuk. Visszalépés nagyon ritkán szokott történni, a tick-tock óta pedig talán sosem volt rá példa.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
 vadcoca
#10904
üzenetére
vadcoca
#10904
üzenetére
Valószínűleg a magától a gyártótól származó leírás több részletet árul el, mint az azt feldolgozó internetes cikkek.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
"Az IGP lényegében sok kis vektormag, amiken külön szálak futnak... Csak (egyelőre) nem a hagyományos értelemben (nem az OS kezeli őket)."
HSA esetében nem is fogja az OS kezelni az IGP-re leosztott feladatokat

Sőt, az OS nem is fogja tudni, hogy mekkora GPU-kapacitás van a CPU mellett (akár tokban, akár buszon), továbbra is annyi magot fog mutatni, ahány CPU-mag van a gépben. Sőt, az CPU-ábrákon FPU-t fogunk látni, nem fog oda GCN bekerülni (Nem is lenne praktikus: miért korlátozná le magát az AMD, hogy egy FPU-t 1-2-4 (mennyi?) GCN-nel kiváltson, amikor mellé pakolhat akárhányat? Mondjuk 1 modul/2 mag mellé is akár 16-ot? )Elég okosan van a HSA-koncepció kitalálva, úgy látom.

Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Ezt, hogy "érdemi változás" elsősorban gyártástechnológiával érhető el, az Intel ültette el a tick-tock-kal (vajon mi lehet ennek az üzleti háttere/indoka? Minden (bér)gyártónak az az érdeke, hogy az adott gyártástechnológiát a lehető leghosszabb ideig futtassa, ezzel csak az Intel megy szembe a piaci igényeket figyelmen kívül hagyó, előre eldöntött 2 éves váltási stratégiájával).
A Bulldozer - Piledriver/Trinity - Richland azonos csíkszélességen bemutatott evolúció vagyis optimalizáció, ez, úgy vélem, elég sok fabless cégnél, pl. az ARM-nál is megszokott, és valószínűleg egyre többször fogunk találkozni ezzel a jövőben.Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
A kérdés ott válik érdekessé, ha a kisebbekhez hozzávesszük a tervező+gyártó cégek közül mondjuk a Samsungot, az IBM-et: nem látjuk azt, hogy előre kimondanák, hogy (két)évente váltanak akár microarchitektúrát, akár gyártástechnológiát; és a TSMC is simán kihagyta a 32 nm-t pl. bizonyos okok miatt, ettől nem dőlt össze a(z ARM-)világ anno, sőt még a lendületét se törte meg.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
#12242
P.H.
senior tag
FireKeeper
#12238
P.H.
senior tag
válasz
 FireKeeper
#12238
üzenetére
FireKeeper
#12238
üzenetére
SZVSZ 2-nél több integer mag nem fog bekerülni egyetlen modulba belátható idő belül.

Ezen a képen jól látszik, nagyságrendileg mekkora egy Bulldozer-modulban a 2 integer core, nem kis része a modulnak ez. A Steamrollerben (legalábbis) a felső 'Instruction Decode' lesz megduplázva, így a 2 maghoz saját dekóder tartozik majd. Egy dekóder 4 utasítást tud 1 órajel alatt átkonvertálni belső RISC-műveletekre, ezért ha egyetlen van belőle, az órajelenként vált a két mag között: egyik órajelben az egyik magnak (programszálnak) ad legfeljebb 4 utasítást, a következő órajelben a másiknak legfeljebb 4-et. Így legjobb esetben 1-1 mag 2 órajelenként kap 4 utasítást, azaz 2.0 feletti IPC elméletileg sem hozható ki, ha egy modulon két szál fut. A két dekóder ezen segít, mivel maguk az integer-magok képesek max. 4 utasítást lefuttatni órajelenként, ha azok megfelelő sorrendben vannak és elég egyszerűek (azaz egy modul 8 db-ot).
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Szvsz a "nem szem elől tévesztés" egy másik, akár sikeresebb formája az is, ha - változtatva az régi Intel-stratégián - nem elnyomni szándékoznak a riválisokat, hanem azok eladott termékeiből is hasznot igyekeznek húzni (Android-Microsoft pl.).
Az már sokkal érdekesebb kérdés (és vita tárgya lehet), hogy ez a stratégiaváltozás annak köszönhető, hogy a régi Grove-Otellini tengelyű szemlélet változott az új CEO-val, vagy egyszerűen csak annak, hogy a gyártástechnológia adott legyártott mennyiséggel tudja visszahozni a befektetett dollármilliárdokat - a volumennek tehát legalább egyenes arányban kell nőnie kell a befektetett összeggel -, és az Intel eddig hagyományosan sikeres területei (szerver+asztal+notebook) már szerintük sem nem ígérnek akkora volument a következő 3-5 évre, hogy ezt vagy inkább következő gyártástechnológiai fejlesztéseket finanszírozza, és előnyét megőrizze.Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Még ha el is fogadjuk, hogy a nanométer már nem megoldás minden problémára, azért azt semmiképp sem hagyható figyelmen kívül, hogy a nanométer-csökkentés gazdaságosabbá teszi a gyártást. De csakis a gyártást - azaz az 1 mm2 waferre eső költséget -, ami csak egy bizonyos része az egész "chip-készítési" folyamatnak, de az utóbbi években egyre markánsabban látható, hogy ez a "chip-készítési folyamat" egyre jobban szegmentálódik, úgy mint:
- ARM vagy MIPS mint ISA-tervező (a.k.a architektúra)
- Qualcomm, MediaTek, Apple, stb. mint "egyedi" elvárások készítője (a.k.a microarch)
- TSMC, GlobalFoundries mint gyártó cégek (a.k.a design implementation)Emlékeztetve erre: "An understanding of the terms architecture, microarchitecture, and design implementation is important when discussing processor design.
The architecture consists of the instruction set and those features of a processor that are visible to software programs running on the processor. The architecture determines what software the processor can run. [...]
The term microarchitecture refers to the design features used to reach the target cost, performance, and functionality goals of the processor. [...]
The design implementation refers to a particular combination of physical logic and circuit elements that comprise a processor that meets the microarchitecture specifications."Ebben a közegben a néhány nagy öregen (Samsung, IBM, Intel) kívül egyre kevésbé finanszírozható házon belül az összes lépés, legutóbb látványosan az AMD is elvesztette/kiszervezte a gyártást és a bele ölt költségeket, és az IBM is erre készül; tehát ez legalábbis nem a tehetségesség vagy a tehetségtelenség mutatója.
Ha viszont ilyen vertikális tekintetben nézzük az egyes fázisok költségeit (K+F, termelési eszközök, gyárak, ...), akkor úgy tűnik, először is a gyártás a legköltségesebb, nála lényegesen kevesebbe kerül a microarch-fejlesztés; új architektúra (ISA) kidolgozása pedig a legkevésbé költséges, lévén - nem lebecsülve a szükséges tudást, - inkább elméleti, mint gyakorlati dolog. A gyakorlat is ezt látszik igazolni, eddig legalábbis a leggyakoribb a "design implementation" váltás volt, kevésbé gyakori a microarch-újratervezés (bár az Intel - kissé érthetetlen, vagy piacilag nem teljesen magyarázható módon - a kettőt évente váltogatta), a legritkább az új ISA-k létrehozása. Ez igaz GPU-fronton is.
Mivel eddig a nanométer-csökkentés volt a legfőbb fegyver hatékonyság növelése érdekében, ha ennek lehetőségei elfogynak, ennek megfelelően egy-egy architektúrát "birtokló/felügyelő" cégnek még mindig kevésbé érdeke az ISA-ja felújítása, viszont igenis érdeke a legtöbbet kihozni microarchitecture-szinten belőle; ez pedig együtt jár - SZVSZ végre - a software-es oldalra helyezett nagyobb hangsúllyal is (gondolok itt arra, hogy az AMD se dobta volna be a pl. Mantle-t, ha számításai szerint úgy haladna a chip-hatékonység fejlesztése a következő 10 évben, mint az elmúlt 10 esztendőben).
A gyártó cégeknek viszont érdeke, hogy minél több eszköz legyen legyártva, hisz a csökkenő mm2-re eső gyártási költségek melletti növekvő egyéb költségek csak úgy behozhatók, ha minél több chip kerül legyártásra. Internet of Things, you know.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
 lezso6
#14193
üzenetére
lezso6
#14193
üzenetére
A microarch - hülyén megfogalmazva - egy nagyon oda-vissza dolog: a HSA pár tucat utasításával mindent meg lehet csinálni (még kevesebb utasítás is elég lenne, pl. a lebegőpontos számok kezelése leginkább bitbirizgálás, régen a 286-386-486 időkben a fordítóprogramok belefordították a programokba a sima integer utasításokkal való végrehajtást arra az esetre, ha nincs FPU), a többi (micro)architektúra 1000+ utasításai csak arra vannak, hogy egyes eseteket/helyzeteket gyorsabban lehessen megoldani (pl. SIMD esetén 2/4/8/16/32 számpárt ugyanannyi idő alatt mondjuk összeadni, mint egyetlen párt; vagy AES is volt eddig, csak most gyorsabb; az AVX is csak közel 2x gyorsabbá tenne bizonyos utasításfolyamokat, ha kihasználnák a programok).
Ezt viszont a leghatékonyabb kihasználni közvetlen kódban; fordított/köztes rétegeket felhasználó nyelvekben ez a hatékonyság csökken. Pl. Abu szerezi emlegeti a pJ/FLOP-ot mint mérőszámot alkalmazni, ami nyilvánvalóan nő, ha a futtatott kódot fordítani is kell előtte.
Ilyen szempontból az x86/x64-nek is csökkenni tűnik a hatékonysága, mivel ezt is úgymond fordítani kell chip-en belül, viszont azt is hozzá kell venni, hogy az x86/x64-nek így sokkal nagyobb a kódsűrűsége, mivel változó hosszúságú utasításokat használ; ezért pl. egy natív x64 programrésznek kb. harmadannyi az I-cache igénye, mint egy IA-64-é és kb. feleannyi, mint egy ARM-é; így kevésbé költséges pl. loop cache-t építeni bele. Ilyeneken is múlik az energiahatékonyság.[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
válasz
lezso6
#14196
üzenetére
Neked és #14195 Abu-nak: A gyártástechnológiai fejlődés lassulásával egyre inkább jönnek elő az olyan "okos" dolgok, mint pl. ez. Az ilyesmit nehéz leírni, és nyilván az Intel és az ARM is kínál(ni fog) hasonló "okosságokat". Igen, eljött a kora az ilyesminek is; most sajnálhatjuk, hogy nem korábban.
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙


















Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Suzuki topik
- Milyen széket vegyek?
- Huawei P30 Pro - teletalálat
- Kupon kunyeráló
- TCL LCD és LED TV-k
- Tényleg jobban fogyaszt a Peugeot, az Opel és a Citroen?
- MIUI / HyperOS topik
- Xiaomi Redmi 4X - Mi-ért hagytál el engem?
- Amlogic S905, S912 processzoros készülékek
- F-Secure termékek
- További aktív témák...
