Hirdetés
Hirdetés
-
Konvektor korszerűsítés - Computherm KonvekPRO felszerelése Q7RF szobatermosztát
lo Működési elv:A gázkonvektorok szerves része a hőmérsékletérzékelő szonda. A szonda egy a termosztáthoz kapilláriscsővel...
-


Titan Army P27GR monitor: hogy tud ilyen olcsó lenni?
ph Meglepően kedvező áron rendelhető meg a kínai netes áruházakból ez a 180 Hz-es gamer monitor – megnéztük, érdemes-e lecsapni rá!
-


Wooting 80HE teszt
gp Megérkezett a játékos billentyűzetek koronázatlan királyának nagytestvére, a TKL méretű Wooting 80HE, amelyet az elsők között próbálhattunk ki.




-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#59867
 Petykemano
veterán
bjasq99
#59845
Petykemano
veterán
bjasq99
#59845
Petykemano
veterán
válasz
 bjasq99
#59845
üzenetére
bjasq99
#59845
üzenetére
Ez egyébként szerintem is érdekes kérdés.
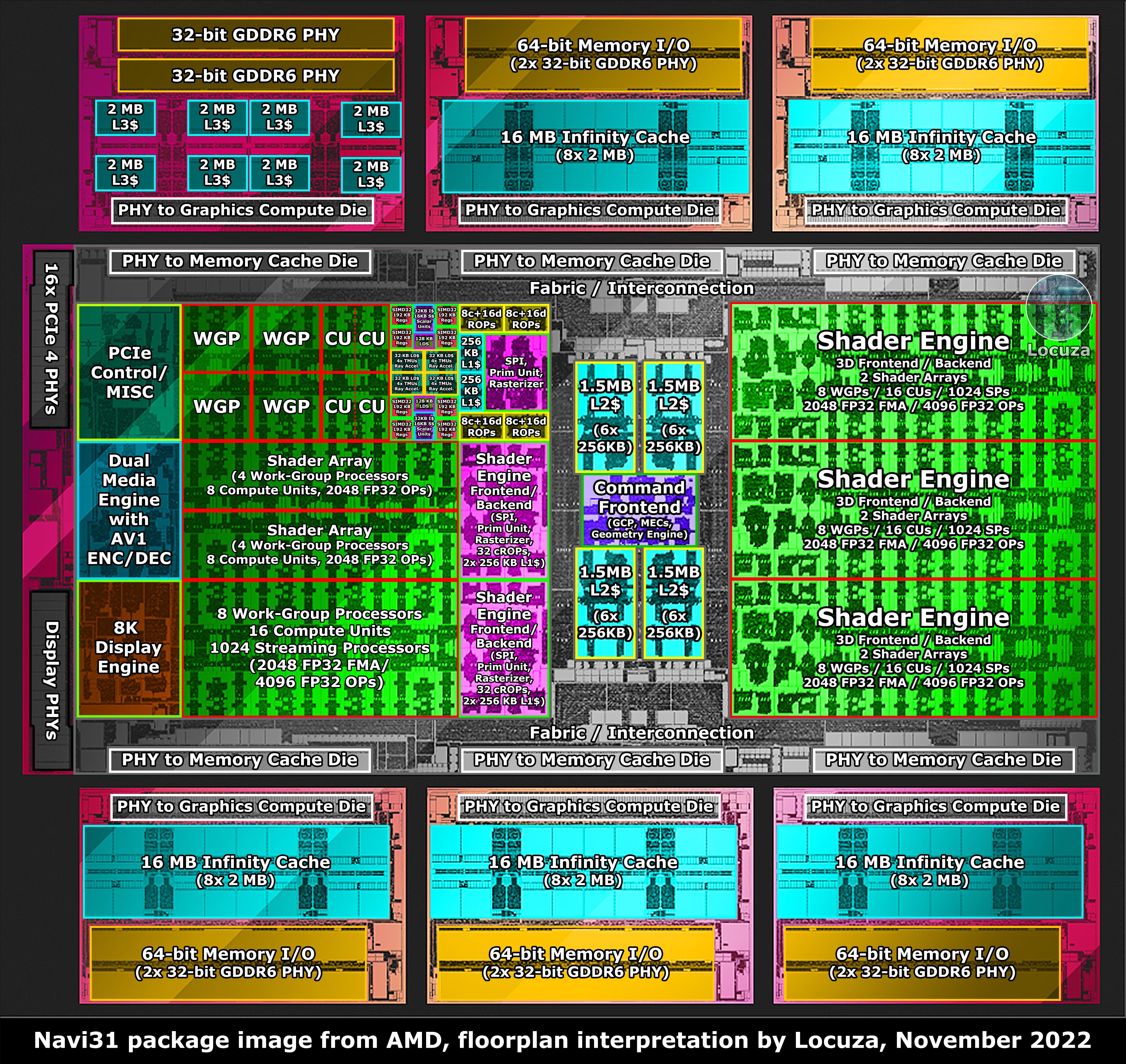
Elvileg az N5 előnye sűrűség kéne hogy legyen. A lapka nagy része N5-on készült elég magas, megsüvegelendő tranzisztorsűrűséggel.Túl a L0 regiszter méretkülönbségén....
Locuza rajzainak tanúsága szerint az infinity interconnect kapcsolatonként az MCD-ből és a GCD-ből mindössze 6-6mm2, összesen 36mm2. Mondjuk összességében nem kevés. Nem csak lapkaméretben, hanem biztos tranzisztorszámban is. A TPU szerint átlag 111.0M / mm² a tranzisztorsűrűség, ha ezzel számolunk, akkor ez is lehet 3-4mrd tranyó.
Az MCD-ken nem csak L3$ és GDDR vezérlő van, hanem TSV is, hogy fogadni legyen képes a 3D a v-cache-t. Abu szerint azt elkaszálták, de attól még foglalja a helyet és a tranyókat. A kiterjedése úgy sacc/kb lehet akkora, mint az interconnect PHY. Azt persze nem tudom, hogy az ott mennyi tranyót jelent.
Azt sem tartom lehetetlennek, hogy az MCD esetén annyira nem törekedtek a helytakarékosságra, hiszen ott azt is figyelembe kell venni, hogy méret szerint passzoljon a V-cache-hez. Tehát nem kizárt, hogy van ott némi "structural silicon" is.
Számomra a GCD-n elég soknak tűnik a szürke terület, ami "Fabric/Interconnection" néven szerepel. Nem vagyok szakértő, de kissé pazarlónak tűnik. Olyna mintha nagyon sok területet (és tranzisztort?) emésztene fel a széleken elhelyezett memóriavezérlőktől központi parancsprocesszorig és L2$-ig a huzalozás. Nekem úgy tűnik, mintha az Nvidiánál kevesebb ilyen szürkével jelölt csupán adatszállításra használt, de legalábbis másnak nem azonosított részegység lenne. A különbség magyarázata lehet valami olyasmi, hogy az AMD esetén a széleken levő L3$ és a központban levő (jó messze) L2 között lényegesen nagyobb sávszélesség van, mint az Nvidia esetén a széleken levő GDDR6 vezérlő és a központban levő nagy L2$ között.Elképzelhető, hogy a Navi33 esetén, mivel jóval kevesebb a GDDR kapcsolat, azért hatékonyabb elrendezést tudnak használni és ott is kevesebb az "huzal".
(Nem emlékszem, mi a szakkifejezés rá, de egy videoban láttam, hogy a 3D stacking azért is fontos előrelépés, mert mivel a tranzisztorsűrűség épp a jellemzően a lapkán belül levő részegységek esetén skálázódik és a lapka szélein levő adatkapcsolatra szolgáló (PHY-k) meg nem, ezért egy idő után egyre inkább szűkösebbé válnak a lapkák szélei és egyre több lehet a holt terhet jelentő huzalozás "befelé"Ami még számíthat az az, hogy a Navi33 esetén biztos nem lesz 16x PCIe PHY. a 200mm2-be bizonyára csak 4x fért el és valószínűleg a Media engine sem dual.
Találgatunk, aztán majd úgyis kiderül..




Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- (Akár komplett PC-vel is eladó!) AORUS GeForce RTX 4090 MASTER 24G - 3+ év garancia
- GIGABYTE RX 6600 XT 8GB GDDR6 EAGLE - 3 ventis hűtés - Eladó!
- Nvidia Quadro P400/ P600/ P620/ P1000/ T1000 - Low profile (LP) + P2000 5Gb, RTX 4000 8Gb
- BESZÁMÍTÁS! ASUS STRIX GeForce RTX 3090 24GB GDDR6X videokártya garanciával hibátlan működéssel
- Pcie 5.0 ATX 3.0 12Pin - 16Pin Moduláris Tápkábelek És Adapterek 12VHPWR Egyedi Harisnya Nvidia
Állásajánlatok

Cég: Ozeki Kft
Város: Debrecen

Cég: Ozeki Kft
Város: Debrecen