Hirdetés
-


AMD Radeon undervolt/overclock
lo Minden egy hideg, téli estén kezdődött, mikor rájöttem, hogy már kicsit kevés az RTX2060...
-


Miniképernyős, VIA-s Epomaker billentyűzet jött a kábelmentes szegmensbe
ph A megfizethető, szivacsokkal jól megpakolt modell ötfajta kapcsolóval és kétféle színösszeállítással/kupakprofillal szerezhető be.
-


Mozgásban az Arena Breakout: Infinite (PC)
gp A korábban csak mobilokra/tabletekre megjelent FPS hamarosan PC-n is elérhető lesz.






Új hozzászólás Aktív témák
-
#7
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
Abu!
Azt látjuk, hogy az apple 3Ghz-en hozza azt a teljesítményt, amit az AMD és az intel 5Ghz körül. Ez nyilván jótékony hatással van a fogyasztásra is, hiszen a szerver procik az intel és az AMD esetében is 3Ghz körül ketyegnek, ahol ideális a hatásfok.
(Mellesleg valószínűleg épp ezért kereste meg Twitteren a Cloudflare CEO-ja Tim Cookot, hogy lenne-e kedve beszélni az M1 design szervercélú felhasználásáról.)
Az alacsony órajel nyilván nem csupán a fogyasztásra van hatással, hanem arra is, hogy mennyire sűrű tud lenni egy design. A magas frekvenciát elérő designoknak nagyobb kiterjedés kell, hogy el tudjon szökni a hő.
Arról ejtenél pár szót, hogy az Apple miért választott, vagy tudott választani ennyire széles designt? És az AMD és az Intel miért nem?
"Mindemellett az OOO (sorrendtől független végrehajtás) logika működési ablaka is rendkívül mély, köszönhetően a 600-nál több bejegyzést is tároló ROB-nak (re-order buffer). Az integer és lebegőpontos rész is egészen erősnek tűnik a mobil szintre. Előbbiben két komplex és négy szimpla ALU található, míg utóbbi négy darab 128 bites NEON SIMD-et kínál, és ennyi feldolgozó bizony még asztali szinten is megsüvegelendő. A fentiekhez mérten a gyorsítótárak tekintetében is el van eresztve a fejlesztés: az L1 utasítás- és adatgyorsítótár rendre 192 és 128 kB, míg a megosztott L2 cache 12 MB."
Az intel és az AMD (és a gyári ARM)
- miért ragadt le 4 ALU-nál?
- miért ragadt és töredék L1$ mellett? Az intel nemrég növelte 32KB-ről 48-ra, az AMD 64-ről csökkentette 32-re a zen2-ben. Nyilván okkal, de miért előnyös ez az Apple esetén és hogyan tudja kihasználni?
- miért nem tud vagy akar elérni ilyen magas ILP-t? (4 v 8 decoder, meg ilyesmi)mi az igazság ebből a mondatból?
"Other contemporary designs such as AMD’s Zen(1 through 3) and Intel’s µarch’s, x86 CPUs today still only feature a 4-wide decoder designs that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions."
[link]
Vagyis hogy azért 4 a decoder az x86 esetén- Miért lenne előnytelen hasonló design azokon a felhasználási területeken, ahol az intel és az AMD dolgozik?
Találgatunk, aztán majd úgyis kiderül..
-
#19
Petykemano
veterán
Sanya
#11
Petykemano
veterán
A GPU engem annyira nem is érdekel.
A CPU esetén a GB tehát olyan teszteket futtat, ami erősen támaszkodik a memória alrendszerre.
Amit ugye a jó cache-hierarchia jól támogat, erősít - ebben pedig jó az Apple M1.Nyilván nem fed le a GB minden terhelési típust.
De attól miért rossz teszt?
Találgatunk, aztán majd úgyis kiderül..
-
#28
Petykemano
veterán
Sanya
#25
Petykemano
veterán
"Ha nem elég erős a processzor, de gyorsan ott az adat, attól még nem lesz gyorsabb a művelet."
Ezt hogy érted?
Tudtommal az összes bohóckodás a többszintű cache megoldásokkal azt a célt szolgálja, hogy gyorsan ott legyen az adat. Én eddig csak olyan ábrát láttam, hogy a compute teljesítmény milyen mereden nőtt és ahhoz képest a memória sebessége milyen laposan.
Szóval szerintem pont attól lesz gyorsabb a művelet, hogy hamarabb van ott az adat.Ha az "erő" alatt a frekvenciát érted, akkor abban valóban van elmaradás, de ha megnézed a késleltetéseket, akkor az nem rosszabb.
"Maga a CPU vérgyenge. Itt a számításokról van szó"
Ezt is hogy érted?
Ian Cutress @anandtechbés abu is elmondta,, hogy az integer backend mennyivel szélesebb, mennyivel szélesebb a decoder párhuzamossága, és a regiszterek vonatkozásában mennyivel vastagabb."de ugye itt tipikusan alacsony fogyasztású rendszerről van szó: 2-4 watt, tehát hiába 2x többet tud számolni, mint egy 2 wattra lebutított Intel CPU, attól még az lassú lesz."
A geekbench és specint mérések nem 2-4W-ra lebutított Intel/amd cpuval való összevetésben állta meg a helyét. Geekbenchben single threadben 8% választja el a fullos 5950X-től."Az ARM processzorok viszont nagyon-nagyon rosszul skálázódnak, ha növeled a teljesítményt, tehát több kakaó, többet is dolgozzon: Egy 65W-os ARM proci viszont már annyira, de annyira vérgyenge lesz egy akár COre i3 procihoz képest, hogy siralmas."
Persze, az eddigi mobilra (2-10W) optimalizált designok nem skálázódtak jól egy bizonyos ponton túl. Ugyanabból a designból nem tudtál mobil 5W és 100W-s változatot is készíteni.
De az apple M1 notebook design. Az Intel és az AMD is ugyanazt használja 15-45W között.
Ne feledkezz meg arról sem, hogy az Apple M1 a korábban látott "notebookba szánt" qualcomm chipnél is lényegesen gyorsabb. Az Apple magjai legalább 50%-kal gyorsabbak a gyári arm magoknál is."Azért abba is gondoljunk bele, hogy az nvidia már réges-réges-réges-régen csinált volna már egy asztali ARM cpu-nvidia gpu kombót, és konkurálhatna az Intellel és az AMD-vel, de nem teszi. Pedig a Windows már akár futhatna is rajta."
Pont erre keresem én is a választ. Hogy az apple m1 cpu magja forradalmi és a szent grál megtalálása, amit évekkel később követhet csak a general cpu development. Vagy egy más célterületre való optimalizálás. De akkor számokkal magyarázza el nekem valaki, hogy ez milyen felhasználási területen nem lenne jó. Például egy remek érv, hogy a zen esetén a designnak akár 64 vagy 128 magra nézve kell cache koherenciára felkészítve lennie. Vagy hogy mekkora teljes memória terület cachelésére kell felkészíteni.Az nvidia arm cpu készítésének több kerékkötője is van. Egyrészt nyilván csak mobil célra készült designok voltak. Fel lehet venni és lehet átdolgozni, de hová és kinek? Chromebookot lehet, hogy lehetett volna belőle készíteni.
"Ez akkor lesz majd baj, ha böngészőzöl, nem lesz nativ youtube kliens, reklámok teleokádják a böngésződet, akarsz statikus weboldalakon kívül bármi mást is csinálni: kéne egy kis CPU is.
Na ott már elvérzik. Ekkor majd jusson eszedbe a geekbenches diagram, hogy ott veri agyon a core i9 procikat, ahol tudja, mindezt 2 watton: rájössz, hogy a teszt nem volt az igazi."
Értem, hogy ez az álláspontod. Korábban én is láttam már... volt a Microsoftnak ez a dokkolós megoldása, éa a legerősebb telefon elvérzett a multitaskingban. (azért az nem az az Apple M1 volt.)De ez például egy lehetséges magyarázat: a clusterekben a magok között megoszrott L2$ remekül kiszolgál több magot, ha azok mindegyike ugyanazon a programok, lényegében ugyanazon az adathalmazon dolgozik. Egy megnyitott böngészőben a renderelés meg js futtatás lehet, hogy ilyen. De ha már több Tab nyitott, meg még egyéb programok, az szaturálja az megosztott L2$ tárhelyet és drasztikusan csökkenti a különböző feladatokon dolgozó magok teljesítményét.
De itt azért 4 magra jut 3db 4MB-os L2$ szelet. Tehát legalább 3 magig még mindig kiváló teljesítményt kell nyújtania. Ezen kívül ez nyilván nem is 2W-os.
Beletették a Mac minibe is. Legkevesebb 15W-os.Félre ne érts, én most nem bizonygatom, hogy de az arm, vagy az m1 a tutijó. Sokan mondják, hogy nem az. Én csak Szeretném mégérten, miért nem az.
Találgatunk, aztán majd úgyis kiderül..
-
#39
Petykemano
veterán
Sanya
#31
Petykemano
veterán
A készítő honlapján ezt a leírást találtam: [link]
Itt mondjuk érdekes módon nem található meg az a megjegyzés a memória használatáról.
De ez nyilván igaz. Ez azt jelenti, hogy azok a programok, amik a memória rendszert intezíven használják, a geekbenchhez hasonlóan jól fognak futni.A geekbenchről azt olvastam, hogy meglehetősen rövid, 10-20 másodperces teszteket hajt végre. Ennyi idő alatt nem melegszik föl egy mobil eszköz, kellően magas frekvencián tud ketyegni. De ez egyaránt kedvez a kezedben levő telefonodnak és egy notebooknak is, Aminek az alapórajele 2GHz, a turbó meg 5GHz.
Ha a Mac minin.sincs hűtés és 15W-os a TDPje, akkor nyilván pont ugyanez igaz arra is.
Mivel a geekbench rövid teszteket hajt végre, ezért nem tudja mérni, hogyan teljesítene az eszköz mondjuk 2 óra renderelés közben. Vagy full load szerverként.
Én a GB helyében azt csinálnám egyébként, hogy szétszedném
ST burst
ST long
MT burst
MT long
Mérésekre. Tehát fut a teszt mondjuk 5 percig és nézi az első 20 másodpercet és a teljes 5 percet. Ebből nyilván kibukna, hogy egy mobil eszköz tartós terhelés alatt megbucsaklik.Gondolom fogják még ezeket az eszközöket mással is mérni. Majd meglátjuk
Találgatunk, aztán majd úgyis kiderül..
-
#68
Petykemano
veterán
Sanya
#63
Petykemano
veterán
Szerintem azt senki nem vonja kétségbe, hogy
- az Apple marketing a legjobb színben igyekszik feltüntetni a bejelentett terméket és épp ezért nem kellően megbízható, a kényes részletekről nyilvánvalóan hallgatnak és abban a tesztben domborítják a terméket, ahol kiemelkedik. (ahová szánják, amire való)
- Ennek megfelelően a GB teszt nem ad mindenre kiterjedő általános képet és különösen nem ad renderingről, meg szerver workload alatti teljesítményről számot.Mondd el, hogy Te milyen formában, forrásból, milyen (teszt)programmal szeretnéd látni, hogy mit tud? (És megköszönném, ha azt is hozzátennéd, hogy az általad megnevezed metrika milyen vonatkozásokban tér el attól, amit a Geekbench mér)
Találgatunk, aztán majd úgyis kiderül..
-
#111
Petykemano
veterán
Sanya
#85
Petykemano
veterán
Én nem állítottam olyat, hogy a geekbench a legrelevánsabb, ám jelenleg ez áll rendelkezésre.
Elmondtam: nyilván ez nem mér mindent és nem is mér minden aspektusból. És azt is elmondtam, hogy nyilván marketing célokat szolgál az apple kezében. [link]Éppen ezért nekem nem célom megvédeni a geekbenchet, sem az Apple-t.
Azt is én mondtam a geekbench ellen és nem te, hogy
1) A készítő honlapján ezt a leírást találtam: [link]
Geekbench 5 CPU Workloads
Geekbench 5 uses a number of different tests, or workloads, to measure CPU performance. The workloads are divided into three subsections:
Crypto Crypto workloads measure the cryptographic instruction performance of your computer by performing tasks that make heavy use of crypto instructions. While not all software uses crypto instructions, the software that does can benefit enormously from it.
Integer Integer workloads measure the integer instruction performance of your computer by performing processor-intensive tasks that make heavy use of integer instructions. All software makes heavy use of integer instructions, meaning a high integer score indicates good overall performance.
Floating Point Floating point workloads measure floating point performance by performing a variety of processor-intensive tasks that make heavy use of floating-point operations. While almost all software makes use of floating point instructions, floating point performance is especially important in video games, digital content creation, and high-performance computing applications.
A complete description of the individual Geekbench 5 CPU workloads can be found hereAz előbbi linken egyébként részletesen ki van fejtve, hogy mit mérnek.
2) "A geekbenchről azt olvastam, hogy meglehetősen rövid, 10-20 másodperces teszteket hajt végre. Ennyi idő alatt nem melegszik föl egy mobil eszköz, kellően magas frekvencián tud ketyegni. De ez egyaránt kedvez a kezedben levő telefonodnak és egy notebooknak is, Aminek az alapórajele 2GHz, a turbó meg 5GHz."
Arra a kérdésre, hogy miért relebáns a geekbench szerintem az a válasz, hogy vagy azért, mert kevés a cross-platform benchmark program, vagy azért, mert az Apple ebben adott meg adatokat, ilyen adatok szivárogtak ki. Egyébként kiszivárgott már a cinebench R23 eredmény is, beszélhetünk arról is. Neked az alapján is gyengének tűnik?
Egyébként néztem pár Geekbench pontot.
Itt vannak pl Samsung telefonok értékei: [link]
Itt pedig a gépedé: [link]A néhány éves telefonok egymagos teljesítménye fele-harmada a desktopnak. A multithread érték pedig harmada-negyede.
A legfrissebb, legcsúcsabb Samsung Galaxy S20 ultra+ közelíti meg egyszálas teljesítményben az amúgy 3 éves szerver procidat és többszálas teljesítményben pedig felére méri.A pontozás referenciája egy i3 8100
Nekem a pontok nagyjából reálisnak tűnnek.Most már csak az a kérdés, milyen telefont használsz. Azt mondod, hogy valami friss apple vagy ilyen SD865 chipet használó készülék megmakkan ugyanattól, ami a szerverprocin vajsima?
Találgatunk, aztán majd úgyis kiderül..
-
#154
Petykemano
veterán
makkmarce
#152
Petykemano
veterán
válasz
 makkmarce
#152
üzenetére
makkmarce
#152
üzenetére
"Ami kb 5 éven belül ki fog derülni, hogy az x86 koncepció elavult e, vagy csak lazsáltak, mert ha rossz, akkor az ARM nagyon el fog húzni."
Károgáson és azon az általánosságon túl, hogy az x86 memóriakezelése vagy címzése elavult, eddig egy konkrétumot olvastam arra vonatkozólag, hogy az x86 ISA limitálna az ARM-mal való IPC versengésben:
"Other contemporary designs such as AMD’s Zen(1 through 3) and Intel’s µarch’s, x86 CPUs today still only feature a 4-wide decoder designs (Intel is 1+4) that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions."
[link]Találgatunk, aztán majd úgyis kiderül..
-
#155
Petykemano
veterán
Dare2Live
#146
Petykemano
veterán
válasz
 Dare2Live
#146
üzenetére
Dare2Live
#146
üzenetére
"De a nagy gond itt se ez, hanem, hogy apple is évek óta hozza a +20%ot (inkább többet) azonos fogyi mellett."
Ha jól tudom, az A14 csak valami 7%-os IPC előrelépést hozott, ami jelentősen elmarad a korábbi évek gyakorlatától. A maradék teljesítmény növekedést a 2.5Ghz=>3Ghz hozta.
Találgatunk, aztán majd úgyis kiderül..
-
#162
Petykemano
veterán
Dare2Live
#159
Petykemano
veterán
válasz
Dare2Live
#159
üzenetére
Amdahl törvénye szerint ha egy program nem tökéletesen többszálúsítható, akkor mindig maradni fog valamekkora rész, ami a feldolgozó cpu egyszálas teljesítményének függvénye
A big.LITTLE/DinamiQ/hybrid multithreading lényege az, hogy a "nagy" magok ezeket a feladatrészeket kapják.
Jó, ez így nem teljesen igaz, mert mobilban jellemzően a "kicsi" magok nem a jól párhuzamosítható feladatok miatt vannak, hanem az alacsony számításigényű feladatokra.De ha az Apple szeretne nagyobb tesót csinálni az M1-nek, akkor szerintem elegendő lenne a hatékonyságra optimalizált magokat sokszorosítani. Pl: 4+8 vagy 4+16, már elég komoly desktop kihívó lenne, miközben lehet, hogy még mindig belefér 25W-ba. És egy 8+32-es lapka már a akár a threadripperrel is versenyképes lenne úgy, hogy belefér egy 45W-os notiba.
Ha valamiért, akkor ebből a megfontolásból lehetett érdemes(ebb) a hatékonyságra optimalizált magokat fejleszteni. Ez akkor térül meg igazán, ha sokat használsz belőle.
Ami az ARM-ot illeti, saját bevallásuk szerint lesz lassulás:
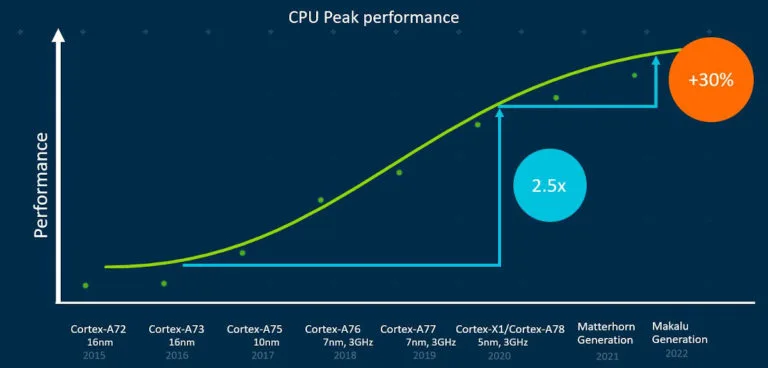
[link]De ez Arm roadmap. Az apple IPC-je efelett áll kb 50%-kal.
A dolog nem független attól, hogy a tervező mennyi tranzisztort kíván áldozni és milyen célra. Már az X1 is úgy jött létre, hogy az A78-tól másfélszer nagyobb és másfélszer többet fogyaszt. Nyilván lesz előrelépés csak annak tranzisztorban és fogyasztásban is ára lesz.""Whilst in the past 5 years Intel has managed to increase their best single-thread performance by about 28%, Apple has managed to improve their designs by 198%, or 2.98x (let’s call it 3x) the performance of the Apple A9 of late 2015."
Ez sem független a beáldozható tranzisztoroktól és fogyasztástól. Az intel 5 éve azért nem tudott lényegi előrelépést elérni, mert beállt a 10nm-es gyártástechnológia fejlesztése. Ez egy meglehetősen váratlan esemény volt, amivel egészen a Rocket Lake megjelenéséig nem tudtak mit kezdeni. Állítólag az ice lake (sunny cove) fejlesztése már kész volt, csak nem tudták legyártani. Ez persze nem jelenti azt, hogy ott lapul, vagy lapult a fiókban a mindentverő ellencsapás, csak hogy a következő 10nm-re készített design készen állt volna a gyártásra a következő években, ha a gyártósorok is készen állnak.Ezzel nem az intelt akarom mentegetni, csak alátámasztom, hogy az IPC növekedése mennyire nem független attól, hogy rendelkezésedre áll-e egy olyan node, aminek a megnövekedő sűrűsége és csökkenő fogyasztása tálcán kínálja az 5-15%-os előrelépést.
Azt gondolom, hogy a következő években azt fogjuk látni, hogy az intel elindult abba az irányba, hogy a fejlesztést nem teszi függővé a következő generációs gyártástechnológiától. De azt nem gondolnám, hogy a kimaradt 5 év IPC növekedése egyszerre ránk szakadna. De az elképzelhető, hogy nagyobb lépések lesznek, mint a 2012-2017-es időszak között volt.
Azt látni kell, hogy a M1 magjai merőben más cache hierarchiát követnek, mint az AMD és az intel procijai. Én azt gondolom, hogy a magasabb IPC a 6x akkora L1$-nek, 8x akkora L2$-nek köszönhető, és persze a 1.5-2x szélesebb feldolgozóegységeknek a magon belül. Ez az, amivel a hagyományos Arm designok közül is kitűnik.
(De nyilván nem olyan egyszerű, hogy csak belepakolom és kész.)Találgatunk, aztán majd úgyis kiderül..
-
#170
Petykemano
veterán
#54625216
#164
Petykemano
veterán
válasz
 #54625216
#164
üzenetére
#54625216
#164
üzenetére
"Nem hinném, hogy maga az x86 ISA lényegesen limitálna bármit is, azaz lehetne egy egyedileg tervezett x86-ot is teletömni hardveres gyorsítókkal"
Én nem vagyok szakértő, laikus szemlélőként látom azt, hogy az Arm esetén az A55, az A78 egy a terület-fogyasztás-teljesítmény hármas közötti egyensúlyi pontot jelent. Az A55 célja a legminimálisabb energiafogyasztás, ezért hiába megy új node-ra a gyártás, nem nő érdemben a teljesítménye. Ha a gyártástechnológia megengedi, akkor frekvenciát kitolhatják 100-200Mhz-cel, de a cél, hogy minél picibb és minél kisebb fogyasztású legyen. És úgy tűnik, hogy az A78 esetében is megállapítottak egy egyensúlyi pontot, ennek megfelelően az A77-hez képest csak pár (7?) százalékkal emelkedett az IPC. Az X1 rugaszkodik el ettől az egyensúlyi ponttal és +20% IPC-ért másfélszer akkora fogyasztással és másfélszer akkora tranzisztorköltséggel kell fizetni.Tehát laikusként ezt látva azt gondolom, hogy az x86-os procik esetén is egy választott egyensúlyi ponton vagyunk és az ettől való eltérés az IPC növekményhez képest aránytalanul magas tranzisztor és/vagy egy magra eső fogyasztási költséggel járna.
Bár az Anandtech hasábjain az jelent meg, hogy a x86-ban ISA miatti limitáció van, valahogy biztos meg lehet oldani. Bizonyára lehet szélesíteni a backendet és a frontendet, de valószínűnek tartom, hogy egy magasabb egyensúlyi állapoton jól működő egység (hogy ne legyen béna kacsa) számos olyan bonyolult áttervezési műveletből állna, mint amilyen a CCX-ben L3$ által kiszolgált magok számának duplázása volt a zen3-ban.
"viszont az Intel és az AMD licenszelési politikája egyszerűen nem teszi lehetővé az egyedi x86-ok fejlesztését, így aki saját cpu-t akar, az kénytelen arm-ban gondolkodni.
Az x86 vs arm soc közötti különbség sokkal inkább az általános cél vs. egyedi design között húzódik."Hát azért van egy Playstation széria és egy xbox széria is. A Ps5-ben és XSX,XSS-ben állítólag módosított zen2 magokkal szerelt proci van és az egész SoC-ban a cpu-n és a gpu-n kívül lehetnek egyedi hardveres gyorsítók, mint pl a PS5 Kraken tömörítője.
Szerintem ez inkább, de legalább annyira szoftveres kérdés is, mint hardveres. Az sem teljesen igaz, hogy az intel ne készítene megrendelésre, vagy igény szerint: állítólag a Lakefield a MS unszolására készült.
A hardveres specializációkat kihasználó szoftver nélkül viszont a hardveres specializációknak semmi értelme. Tehát aki saját cpu-t akar, annak ott kell kezdenie, hogy legyen egy saját szoftvere. Olyan ökoszisztémája, amiben nem csak dísznek lennének a hardveres gyorsítók nagyjából az apple-nek van, illetve az Android igényeihez igazodik a Qualcomm.De a heterogén számításban egyelőre még azt sem értük el, hogy egy GPU használata általános legyen. De ez nyilván ilyen róka fogta csuka, meg tojás-tyúk kérdés, mert egy általános szoftverrel arra a hardveres képességre lehet építeni, ami széles körben elérhető, hardverelemet meg akkor fognak beépíteni, ha azt széles körben elérhető szoftver használná.
lényegében ezt mondtad te is:
"Az Apple újítása viszont pont az, hogy nem csak egy általános célú hardverhez optimalizálja az OS-t és a szoftvereit, hanem hardver oldalról is megtámogatja a platformját."
Viszont azt látni kell, hogy az Apple nem csak hardveres gyorsítással tűnik ki. Nem azt csinálták, hogy beleraktak a chipbe, valami általános, közepes, polcról leemelhető ARM designt, amit bárki megkaphat és telepakolták hardveres gyorsítóval, hogy az majd megoldja.
Hanem a hardveres gyorsítókon kívül a cpu mag is lényegesen jobb, mint a polcról leemelhető. (Bár a kollégák elmondása szerint ez nem biztos, hogy mérhető lesz általános célú benchmark programokkal)Ez azért jelent nehézséget az Apple konkurenseinek, mert nem lehet azt mondani, hogy jólvan, nekik van hardveres gyorsítójuk, a mi általános célú procink viszont gyorsabb. Mert nem gyorsabb. Tehát aki az Apple-lel akar konkurálni annak a jó procin kívül hardveres gyorsítókra és azt használni képes szoftveres ökoszisztémára is szüksége van.
Lényegében ezt mondtad te is:
Azaz bárki is akarja felvenni velük a versenyt (értsd: nvidia, google, ms) az kénytelen lesz szintén saját soc-ban gondolkodni, amit x86 alapon jelenleg nem engednek az ápolók."
Csak abban mondanék ellent, hogy ezt feltétlenül csak úgy lehetne-e a jövőben megoldani, hogy a szoftveres cég házon belülre hozza a chiptervezést is arm vagy risc-v alapokra.
A szoros együttműködés nyilván szükséges.De az intel (oneapi) és a Xilinx megvásárlásával az AMD is egy olyan irányba indul el, ami kvázi egy svédasztalos chip-terveztetési lehetőséget biztosít a potenciális vásárlók számára.
Ez a szerverek terén meg is fog történni.
Azt viszont nem tudom, hogy kliensgépeknél ez hogy valósulhatna meg. Mert az rendben van, hogy pl MS terveztet az AMD-vel egy chipet, amit belerak a saját eszközébe (xbox, surface) de hogy kerül bele például egy HP, vagy Dell által összerakott notebookba? (mondjuk nem biztos, hogy ennek a MS-ot érdekelnie kell.)Találgatunk, aztán majd úgyis kiderül..
-
#175
Petykemano
veterán
Petykemano
veterán
Találgatunk, aztán majd úgyis kiderül..
-
#308
Petykemano
veterán
makkmarce
#307
Petykemano
veterán
válasz
makkmarce
#307
üzenetére
De, tényleg jobb.
A Specint szám az azt mutatja, hogy időben mennyivel gyorsabban készül el a feladat. Tényleg kicsit több mint 2x gyorsabban hajtja végre ugyanazt a feladatot az A12, mint az A55
A fogyasztási értékek közül a W az ami most legkevésbé számít. Az csak azt mutatja meg, hogy működés közben mennyi hőt termelhet.
Ami a hatékonyságot megmutatja az a Joule.
Mert ugye lehetne azt mondani, hogy jójójó, hát egy erős mag, hamar végez, de közben sokat is fogyaszt. De a Joule-ból az látszik, hogy az A12, miközben 2x gyorsabban hajtja végre a feladatot, addig számottevően kevesebb energiát is fogyaszt is el.IGazából az ábrából az derül ki, hogy az Apple magjai jók. mármint tényleg betöltik a big.LITTLE szerepet.
Ha valamit a nagy magon hajtasz végre, 4x gyorsabb, mint az energiahatékony magon, de ugyanazon művelet végrehajtása közben 2x annyit fogyaszt.A Qualcomm és a Samsung designjában viszont szinte ostobaság A55-öt tenni. Ha egy feladatot a nagy maggal hajtatsz végre, az összesséégben pont ugyanannyi energiát fog fogyasztani, mintha kismagokkal tennéd és még sokkal gyorsabban is végez. Energiában nem nyersz semmit a kis magok használatával. (max helyet)
Most már csak az a kérdés, hogy a teszt valóban helyesen méri-e az A55 magok hasznosságát.
Találgatunk, aztán majd úgyis kiderül..
-
#310
Petykemano
veterán
aprokaroka87
#309
Petykemano
veterán
válasz
 aprokaroka87
#309
üzenetére
aprokaroka87
#309
üzenetére
igen, igazad van. Nem big.LITTLE
Kicsit megtévesztő, hogy a wikin továbbviszik ezt a kifejezést és még rá is játszanak a betűméretekkel.Találgatunk, aztán majd úgyis kiderül..
-
#313
Petykemano
veterán
aprokaroka87
#311
Petykemano
veterán
válasz
aprokaroka87
#311
üzenetére
Remélem nem haragszol meg, ha azt mondom, szerintem a dinamIQ vagy big.LITTLE összefűzési keret részletkérdés a filozófia mellett, amely arról szól, hogy teljesítmenyre optimalizált "Nagy" magokat csomagolunk egybe energiahatékonyságra optimalizált jellemzően kis magokkal.
Találgatunk, aztán majd úgyis kiderül..
-
#314
Petykemano
veterán
makkmarce
#312
Petykemano
veterán
válasz
makkmarce
#312
üzenetére
"a joule az már számolt érték a fogyasztásból és sebességből, tehát vagy a sebességet és a wattot nézed, vagy csak a joule-t"
Egész pontosan így fogalmaztam: "A fogyasztási értékek közül a W az ami most legkevésbé számít. Az csak azt mutatja meg, hogy működés közben mennyi hőt termelhet."
Világos, hogy a Joule egy számolt érték. Ez azt mutatja meg, hogy a teszt lefutása során mennyi energiát használt el.ha a joule-t nézed, akkor sincs meg még 2x-es sem, nem hogy 6x-os
Ezt nem lehet így összevonni, hogy 2x gyorsabb és 2x kevesebbet fogyaszt, akkor 4x jobb.
2x gyorsabb és ugyanannyit fogyaszt. => a felhasznált energia feleannyi lesz a végénA 2x-es szorzó pedig a specintnél jön ki A12 Tempest vs Qualcomm A55. Ott tényleg 2x akkora az A55 energiafelhasználása.
Specfp-ben csak másfélszeres.még jó, hogy te jobban tudod, mint ők, hogy mit érdemes a telefonba tenni
Hát ránézek az ábrára és azt látom: a specint tesztet a Qualcomm 3 féle magtípusán végrehajtva közel ugyanannyi energiát használunk el. Csak a nagy magokon gyorsan hajtódik végre, a kicsiken meg lassan.
De gyere, számoljunk perf/W mutatókat.
Te melyik magtól várnál jobb perf/W mutatót? Én a kicsitől(specint)
A12 Vortex: 45,32/3,64 = 12.45
A12 Tempest: 29.43Exynos 9820 M4: 26,3/2,99 = 8.79
Exynos 9820 A75: 13.45
Exynos 9820 A55: 14.11SD 855 2845Mhz: 12.93
SD 855 2430Mh: 14.64
SD 855 A55: 16.9375(Specfp)
A12 Vortex: 54,84/4,27 = 13.77
A12 Tempest: 21.49Exynos 9820 M4: 11.37
Exynos 9820 A75: 13.75
Exynos 9820 A55: 12SD 855 2845Mhz: 14.02
SD 855 2430Mh: 15.72
SD 855 A55: 13.9Most már érted?
Az apple esetén a kis mag perf/w eredménye lényegesen jobb, mint a nagy magé. A Samsung és a Qualcomm esetében alig van különbség az egyes magtípusok perf/w mutatója között, fp esetén meg még gyengébb is. Tehát az A55 magokkal energiahatékonyságot nem nyersz, max területet.NA persze feltéve, hogy a specintet elfogadjuk életszerű tesztnek azokra az esetekre, amire egy kis mag ki lett találva. Ez volt ugye a zárókérdésem. Lehet, hogy egy értesítő kezelésére standby módban még így is sokkal alkalmas, mivel (amennyiben) a fogyasztás nagy része nem standby üzemmódban történik, hanem aktív használat közben.
Ne haragudj, de a többit a 6 meg 8 maggal nem is értem. Szerintem ezek a specint és specfp mérések egyszálas eredmények.
Találgatunk, aztán majd úgyis kiderül..
-
#316
Petykemano
veterán
makkmarce
#315
Petykemano
veterán
válasz
makkmarce
#315
üzenetére
Az A13 Thunderről írták, hogy ugyanazt a feladatot 2.5-3x gyorsabb hajtja végre, miközben feleannyit fogyaszt.
Ezt a "6x" dolgot engedd el.Én annyit mondtam, az Apple kis magja tényleg energiahatékonyabb, mint a nagy mag, ahogy az várható. Eközben a gyári arm magok specint/fp teszt alatt nem mutatnak lényegi különbséget egymáshoz képest.
És hogy miért érdekes így külön, az meg úgy jött elő, hogy az elemzés írója szerint az applenél tapasztalható hosszabb standby módban mérhető üzemidő oka arra vezezhető vissza, hogy az apple kis magjai számottevően energiahatékonyabbak, mint a gyári arm magok.
Nyilván más gyártók azért használnak A55-t, mert nincs más. És már harmadszor mondom el, hogy a specintben mérhető energiahatékonyság ellenére nyilvánvalóan kevesebb területet foglal és valószínűleg a mag felélesztése is kevesebb energiát használ.
De azért létszik, hogy lehetnek jobb és azzal együtt hosszabb az üzemidő.
Találgatunk, aztán majd úgyis kiderül..
-
#318
Petykemano
veterán
makkmarce
#317
Petykemano
veterán
válasz
makkmarce
#317
üzenetére
Szerintem az A55 design nem változik attól, hogy újabb és újabb és újabb chipekbe tervezik bele, sem pedig attól, hogy kisebb csíkszélességen gyártják le. A kisebb csíkszélességtől a fogyasztása persze annak is javul.
Ebből az ábrából a tényleges energiamenedzsment nem derül ki. Én is erre utaltam, amikor azt mondtam: vajon a specint/fp mérés alkalmas-e az energiahatékonyság mérésére.
Mindazonáltal az A55 elavultságának felemlegetése egy az apple készülékek jobb standby üzemidejének magyarázatára tett kísérlet volt.
Találgatunk, aztán majd úgyis kiderül..
-
#341
Petykemano
veterán
brumi1024
#337
Petykemano
veterán
válasz
 brumi1024
#337
üzenetére
brumi1024
#337
üzenetére
Szerintem az eredmény nagyon szép!
A kérdés legfeljebb az, hogy azzal, hogy az M1 gyorsabb mint a relatíve új 2 éves 5x akkora TDP-vel.rendelkező 2700X azzal egész pontosan mit akarunk üzenni?
Azt, hogy milyen ügyes az Apple?
Vagy mennyivel jobb az arm?
Vagy hogy milyen csodálatos a technológia fejlődése?Persze lehet, hogy mindegyikben van némi igazság.
Amikor az első szivárgások megjelentek a renoirról, abból is az látszott : a 7nm-en készített Renoir 35W TDP-vel eléri a 100W-os 2700X teljesítményét.
Ahogy a renoirnál a 7nm, úgy az Apple chipjénél tapasztalt alacsony fogyasztás egy részét a forradalmian új 5nm-nek (ami.már EUV) köszönheti.
Ez természetesen az M1 érdemeiből nem vesz el. Legkevésbé sem szeretném elvitatni azzal, hogy majd akkor hasonlítgassuk, ha...
De ez az AMD által nem használt 10nm-rel együtt 3 generációs gyártástechnológiai különbséget jelent. Ennyi előrelépés el is várható.Valószínűleg ha majd megjelenik az első 5nm-es mobil AMD termék, az is le fogja lépni 15W-ból talán a 105W-os zen2-ket is.
De az M1 egyébként a tesztben csodálatosan teljesít.
Én azt látom, hogy remekül muzsikál a nagy L1$ és L2$ éa a széles backend.
Én azt remélem, vagy mondjuk úgy, úgy vélem, bármilyen processzor design esetén nincs más út, mint ez. Az Apple igazi nagy érdeme az, hogy kb 50% IPC többlettel nagyjából mindenkit állva hagytak. A gyári armot is. Azt gondolom, a következő években a Nuvia is valami hasonlóval fog előjönni. De nem kizárt, hogy addigra mindenki. Addigra az Apple már 3-4nm gyártat majd.De az eredményekből az is látszik, hogy a teszt nagyon szereti a zen L3$-t is. A 2700X egyes magjai csak maximum 8MB/hoz fértek hozzá. Ezt duplázta a zen2 magonként 16MB-hoz való hozzáféréssel. Ez magyarázza, miért lényegesen jobb a 3950X, mint a 2700X kevés szálon is.
Ha a TDP-re kihegyezve akarjuk vizsgálni, akkor talán úgy igazságos, hogy a 3950X TDP-jét is lekonfiguráljuk biosból 45W-ra. Az utolsó 20-30W-ot jellemzően az utolsó párszáz megahertz teszi hozzá.
Ezen a pgbench teszten egyébként épp a cache méret miatt a Renoir valószínűleg nem szerepelt volna olyan jól.
Viszont az AMDnek most jött ki a zen3-as fejlesztése, ami szintén duplázta az egy mag által.elérhető maximális L3$ méretét. Én kíváncsi lettem volna, az hogy teljesít, de sajnos nem találtam ilyen bontott pgbench eredményeket.
Találgatunk, aztán majd úgyis kiderül..
-
#345
Petykemano
veterán
smc
#343
Petykemano
veterán
Az, hogy lehet-e skálázni, ez a nagy kérdés.
Akár frekvenciát - nyilván fogyasztás árán -, akár a magok számát.Egyik sem megoldhatatlan, de szerintem mindkettővel dolgozni kellhet.
A frekvencia skálázásával kapcsolatban egyrészt Abu tollából ismerjük, hogy a Vega frekvenciaemelésére az AMD tranzisztorokat áldozott, másrészt a 2015-2016-ban a zen fejlesztése idején voltak beszélgetések arról, hogy a magas frekvencia eléréséhez design oldalról hosszú pipeline szükséges . persze az még nem minden, mert a gyártástechnológia által kínált fogyasztás (a tranzisztorok állapotváltásának maximális gyorsasága és az ahhoz szükséges energia), valamint a hő elvezethetősége szempontjából fontos tranzisztorsűrűség is hatással van arra, hogy tud-e a frekvenciával skálázódni egy design.
Utóbbira jó példa szintén a zen, amelynél mérhető volt, hogy 4-4.1Ghz fölé egyszerűen nem megy. Nem azért, mert 1 szálon 4.2Ghz-cel már többet fogyasztott volna, mint 100W, hanem mondjuk 5W helyett az ahhoz szükséges feszültségen már mondjuk 10W lett volna.Azt is tudjuk ugye adott frekvencia eléréséhez és tartásához szükséges energia és feszültség a tranzisztor hőmérsékletének emelkedésével szintén emelkedik. Ha a design nagyon sűrű és feltekered a frekvenciát és feszültséget, akkor elkezd olyan mennyiségű hő termelődni, ami a sűrű designból nem tud elszökni/elvezetődni és az egyre melegedő tranzisztorhoz egyre nagyobb feszültséget kéne adni, különben képtelen tartani a frekvenciát. stb. Érted: instabillá válik. Ez a jelenség nem annyira a fogyasztással függ össze, hanem az úgynevezett hősűrűséggel (heat density)
Tehát hiába fogyaszt az M1 mondjuk csak 15W-ot, az nem feltétlenül jelenti azt, hogy van még 80W-nyi szabad fogyasztási keret a desktop CPU-khoz képest.
Az Apple 7nm-es designja hozta a névleges 100Mtr/mm2 sűrűséget, míg az AMD designjai ugyanazon a gyártástechnológián 40-60Mtr/mm2 között volt csupán.
Ha az Apple az M1-et is sűrűségre optimalizálta, akkor esélyes, hogy nem nagyon fog 3.1-3.2Ghz-nél feljebb skálázódni a frekvencia.
De ez nem jelenti azt, hogy ne lehetne olyan változatot készíteni, ami kevésbé sűrű. Az AMD a 14nm-es Zen cpu-k után a Globalfoundriesnál 12nm-en gyártotta a zen+ cpu-kat. Akkoriban azt mondák, hogy a 12nm-es tranzisztorok kisebbek, de az AMD ennek ellenére nem változtatott a designon, nem lett kisebb a lapka, viszont több lett az "üres tér" a tranzisztorok között és ezzel nyertek 300Mhz-et (1800X => 2700X)
Tehát nagyobb áttervezés nélkül csupán egy másik library használatával is készíthetnének akár 3.5-3.6Ghz-es M1' lapkát.
Legföljebb az a kérdés, hogy az megérné-e? Én azt gondolom, hogy egy ugyanilyen felépítésű lapkát, de 10-15%-kal nagyobb frekvenciát elérő nem tudna az apple kellő mennyiségben ellőni.A másik kérdés a magok számának skálázódása. Valószínűleg ez sem olyan triviális kérdés, hiszen a magok között cache-koherenciát kell teremteni. Szóval a magszám bővítésére valószínűleg több tranzisztort kellene áldozni pusztán annál, amennyit az egyes cpu clusterek elfoglalnak.
De szerintem ez meg fog valósulni. Ha feltételezzük, hogy az M1 100mm2, akkor az apple biztosan képes lenne 2-2.5x ekkora területen egy 2-3x akkora teljesítményű procit készíteni úgy, hogy abban már benne van a SLC bővítése és a kicsivel magasabb frekvencia elérése érdekében egy picit elengedett tranzisztorsűrűség.
Találgatunk, aztán majd úgyis kiderül..
-
#363
Petykemano
veterán
Petykemano
veterán
Érdekes kísérlet
Ha a zen3 frekvenciájából (és feszültségből) visszaveszünk (3.7-3.9ghz), akkor persze szignifikánsan lassabb lesz, mint az M1, de az egy mag HWInfo által mért fogyasztása nagyonis versenyképes. (5nm vs 7nm)Persze ez csak egy cpu mag értéke. A képek alapján a package powerben lényeges kükönbség van. Ami igazán nagy szám az az, hogy míg az 5600x mag fullosan hajtva (ST) 12W-ot fogyaszt, addig a package power 40W, ugyanez az M1 esetén úgy fest, hogy a package power kb 10%-kal nagyobb csak, mint a fullra terhelt CPU mag fogyasztása.
Túl azon, hogy a zen magok idle fogyasztása (300mW) lénygesen magasabb, mint az M1 magoké, ezért a különbségért nyilván az MCM és a 14nm-es IO lapka is felelős. Majd egy Cézanne-nal is érdemes lehet összevetni.
Találgatunk, aztán majd úgyis kiderül..
-
#365
Petykemano
veterán
ddekany
#364
Petykemano
veterán
Persze, 1 esetleg 2 éves lemaradásról beszélhetünk, de nem feltétlenül és kifejezetten design vagy architekturális.
A cikk üzenete nekem ez:
Egyrészt Az előny egy része abból származik, hogy az apple meg tudja fizetni (és meg tudja fizettetni a vásárlóival) azt, hogy a legpöpecebb 5nm-en gyártat. Ez nem csak a fogyasztásban segít, hanem abban is, hogy több cache-t tudnak belepakolni.
Másrészt az előny valamiféle architekturális fejlettségből fakad (amit nem magyaráz az 5nm sűrűsége), vagy döntések eredménye. Ugye erről már írtam pár gondolatot korábban: A zen3-nak egy 2x64 magos EPYC környezetben is koherensen kell működnie. Ennek lehet, hogy van bizonyos költsége, vagy megkötéseket eredményezhet.Ez persze semmit nem vesz el a M1 jelenleg mérhető előnyéből.
És mivel az Apple minden bizonnyal a továbbiakban is a legfejlettebb node-on fog gyártatni, ezért ezt az előnyt nyilvánvalóan meg fogja tartani.Az arm saját előrejelzései szerint az IPC növekedés üteme le fog lassulni és valóban az A77->A78 és az A13=>A14 átmenet egyszámjegyű IPC növekedést hozott.
Az intelnek lassan sikerül összekaparnia a gyártósorait és/vagy gyártástechnológiától független tervezéssel sikerülhet újra fejlődési pályára állniuk. Az elmúlt 5 év persze elveszett.
És az AMD zen is ígéretes a továbbiakban.Szerintem nem is annyira az a kérdés, hogy tudnak-e majd versenyképes CPU-t készíteni. Szerintem igen. A kérdés sokkal inkább az, hogy a versenyképes cpu-ba vagy mellé milyen gyorsítókat tudnak integrálni és hogy a saját gyorsítós elképzeléseikhez meg tudnak-e győzni szoftverházakat.
Találgatunk, aztán majd úgyis kiderül..









Új hozzászólás Aktív témák

ph A lapka processzorrésze igen erős lett, de az IGP-jéről elég keveset tudni.
- Milyen belső merevlemezt vegyek?
- Steam Deck
- Musk szerint már jövőre itt vannak a Tesla Optimus humanoid robotok
- Kompakt vízhűtés
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Politika
- Suzuki topik
- Okos Otthon / Smart Home
- Zenelejátszó építése, a kiváló hangzásért
- Nagyrobogósok baráti topikja
- További aktív témák...

- Intel Core i7-11700K processzor (használt)
- Beszámítás! Intel Core i7 6700K 4 mag 8 szál processzor garanciával hibátlan működéssel
- Új bontatlan, dobozos, számlás, garanciális i9 13900K CPU akció!
- ELADÓ - Ryzen 7 5800X
- Beszámítás! Intel Core i3 10105 4 mag 8 szál processzor garanciával hibátlan működéssel