- Magisk
- Samsung Galaxy A72 - kicsit király
- MIUI / HyperOS topik
- Ennyibe kerülnek a Huawei Pura modellek Európában
- Motorola Edge 40 - jó bőr
- Nothing Phone 2a - semmi nem drága
- Képeken az egyik kameráját elvesztő Sony Xperia 10 VI
- Mindent megtudtunk az új Nokia 3210-ről
- Fotók, videók mobillal
- Android szakmai topik
Hirdetés
-


AMD Radeon undervolt/overclock
lo Minden egy hideg, téli estén kezdődött, mikor rájöttem, hogy már kicsit kevés az RTX2060...
-


Sokat fogyaszt az AI, egyre több az adatközpont, kell az atomenergia
it Az AI-t kiszolgáló adatközpontok olyan nagy energiaigénnyel bírnak, hogy egyre több atomenergiára van szükség.
-


Mindent megtudtunk az új Nokia 3210-ről
ma Részletes képek, specifikációk és euróban megadott ár is van a legendás modell újraélesztett verziójához.






Új hozzászólás Aktív témák
-
#1
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
Engem meglepett, hogy az EMIB PHY milyen sok helyet foglal a lapkán.
Ha ez a IFOP alternatívája, akkor annyira nem meglepő, hogy az AMD eddig nem nagyon erőltette ezt az irányt, hiába, hogy esetleg lényegesen kisebb fogyasztással valósítaná meg ugyanazt az adatátviteli mennyiséget.Találgatunk, aztán majd úgyis kiderül..
-

vrob
aktív tag
Végre lehet látni is belőle valamit.
Érdekes lesz, fele akkora cache/core-ral az AlderLake-hez képest mennyit tudnak majd.
De ha nézzük, hogy egy ilyen complexben 15 mag van az amd 8-ához képest, plusz hozzávesszük a várható jóval jobb skálázódást az EMIB összekötéssel mint az IO modulon keresztül a Zen3-ban,
olyan 1,5X -ös összteljesítmény meglehet ezektől egy 64magos top Epichez képest. -
#5
Petykemano
veterán
vrob
#3
Petykemano
veterán
> olyan 1,5X -ös összteljesítmény meglehet ezektől egy 64magos top Epichez képest.
Megtennéd, hogy részletezed, hogy milyen előnyök milyen mértékben járulnak hozzá ahhoz, hogy az 56 magos SPR 1.5x jobb teljesítményt nyújtson, mint a 64 magos Milan?Találgatunk, aztán majd úgyis kiderül..
-
-
#7
vrob
aktív tag
Petykemano
#5
vrob
aktív tag
válasz
 Petykemano
#5
üzenetére
Petykemano
#5
üzenetére
A 64 magos Milan teljesítménye beesik per core viszonylatban, nem jól skálázódik amikor minden magra szükség van ami érthető a CCX-es felépítés miatt. A monolitikus 40 magos IceLake is többet ki hoz egy magból amikor mind pörög. Ettől persze összességében a 64 db Epic mag egyértelműen erősebb az IceLake megoldásoknál ... mielőtt ebbe belekapaszkodna valaki.
[linkhttps://www.anandtech.com/show/16594/intel-3rd-gen-xeon-scalable-review/8]
A Intel7 gyártástechnológián készült performance magok teljesítményét láttuk az AlderLake-ben.
A kettőt nem nehéz összerakni. -

tibaimp
nagyúr
Egyetértek!
Meg lehet nézni, hogy a 8 P magos Alber Lake a legtöbb tesztben megverte még a 16 magos Ryzen-t is, az 5950x-et [link] , így simán el tudom képzelni, hogy a 56 maggal, ha nem is 1,5x-es előny, de egy kisebb előny kijöhet a 64 magos Milan ellen.A tehén egy bonyolult állat, de ÉN megfejtem...| 2016-tól az tuti, hogy az angyalok is esznek babot...
-

Abu85
HÁZIGAZDA
Nem érdemes a szerver workloadot összehasonlítani a desktop workloaddal. Annyira különböző, hogy mások az előnyök. Jól látszik ez a 3D V-Cache-en is. Amíg ez a technológia desktopon a játékokban maximum +40-45%-ot ér, addig a szerverekben a Microsoft +50-80% közé rakta az általános előnyt. Akkora a különbség a workloadban, hogy nem lehet a desktopból kiindulni.
Egyébként a Sapphira Rapids-ról maga az Intel sem beszél úgy, hogy verni fogják vele a világot, inkább úgy fogalmaznak vele kapcsolatban, hogy felzárkóznak. Erre egyébként tényleg van esélyük, mert a gyártói tesztek szerint azért az 56-magos Sapphire Rapids ES nincs messze a 64-magos csúcs Milan platformtól, viszont a Milan-X nagy falat neki. A gond inkább az, hogy mire nagy mennyiségben elérhető lesz a Sapphire Rapids a piacon, addigra már ott lesz a sokkal gyorsabb Genoa, arra meg megint kevés lesz válasznak az Emerald Rapids, ami tulajdonképpen egy javított Sapphire Rapids.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#10
Petykemano
veterán
vrob
#7
Petykemano
veterán
Értem, hogy mire gondolsz.
Miből gondolod, hogy amikor a 64 magos Milan teljesítménye per core viszonylatban beesik, akkor az valamilyen architekturális/strukturális hiányosság, ami miatt nem skálázódik jól és nem pedig csupán arról van szó, hogy úgymond kifogy a TDP-ből?
lásd pl:
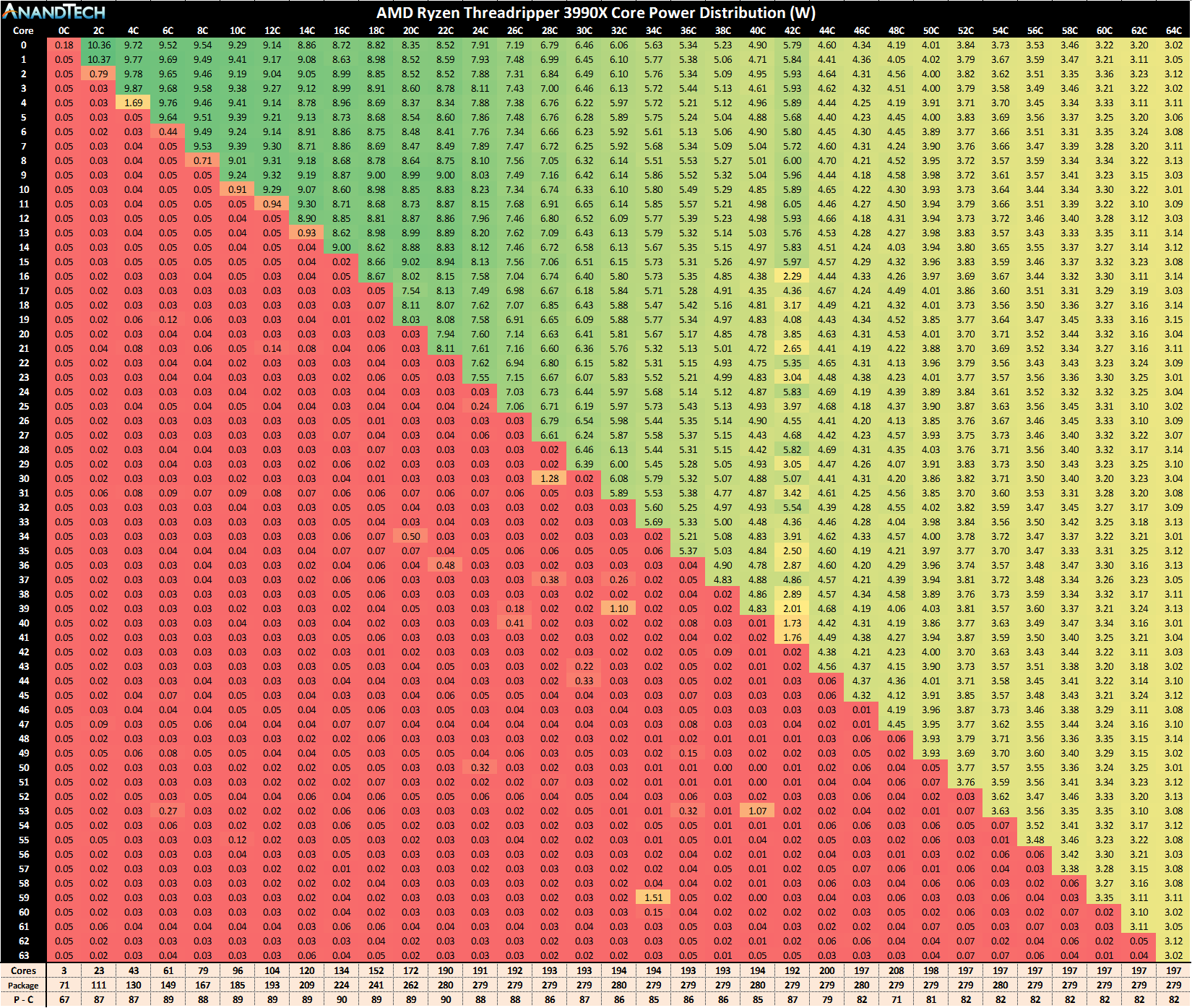
Ha jól emlékszem, a Milan 280W TDP kerettel rendelkezik, a Sapphire rapids pedig már 350W-tal.Találgatunk, aztán majd úgyis kiderül..
-
-
#12
vrob
aktív tag
Petykemano
#10
vrob
aktív tag
válasz
Petykemano
#10
üzenetére
Simán lehet hogy a TDP keret is szerepet játszik.
De az architektúra is. Az egyértelmű, hogy a felépítésük miatt a latency nagy a Zen-eknél. Igaz ezt ellensúlyozza a nagyobb cache. Bonyolult a képlet.
-
Abu85
HÁZIGAZDA
Mivel még nincs feloldva az NDA, így nem. De alapvetően arról van szó, hogy a Sapphire Rapids még nem igazán a teljes fejlesztés. Ki kell adni, mert egyszerűen nem késhet többet, de majd lesz az Emerald Rapids, ami az lesz, aminek a Sapphire Rapidsnak eredetileg kellett volna lennie még 2021-ben. Az Emerald Rapids magasabb órajelre képes, jobbak a hatékonysági mutatói, illetve javítják benne a CXL vezérlőnek azt bugját, ami miatt csak a CXL.io és CXL.cache komponensek működnek, míg az 1.1-es sztenderd részének számító CXL.mem nem. Ezt a Sapphire Rapids kiadásáig már nem tudták megoldani, mert fél évvel kellett volna tolni a startot, így inkább kiadják úgy ahogy van. Akinek iszonyatosan szüksége van a CXL 1.1-re, annak majd szállítanak egy év múlva Emerald Rapids upgrade-et garanciában.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

GeryFlash
veterán
,,Akinek iszonyatosan szüksége van a CXL 1.1-re, annak majd szállítanak egy év múlva Emerald Rapids upgrade-et garanciában."
Ezt hogy kell erteni, gyakorlatban hogy nez ki? Beszamitjak a regi es alig kell radobni arban?
Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
Abu85
HÁZIGAZDA
válasz
 GeryFlash
#14
üzenetére
GeryFlash
#14
üzenetére
Gondolom visszakérik a régit, és adnak egy újat, amiben már működik a CXL.mem (szerintem még fizetni sem kell érte, mert ugye eleve CXL 1.1-ként hirdetik a CPU-t, amihez kell a CXL.mem is). Nehéz ezt jól megoldani, mert ha kijavítják a bugot, akkor meg nincs értelme kiadni a Sapphire Rapids CPU-t, mert rácsúszik az Emerald Rapids-ra. Az meg durva arcvesztés lenne, hogy az Intel rövid időn belül már a második nagy szerverdizájnját törli, így inkább kiadják úgy ahogy van. Ez eredmények alapján 2021-ben jó lett volna. Ugyan nincs meg az egyértelmű előnye a Milan platformmal szemben, viszont face-to-face szinten simán eladható jól árazva. Ugyanakkor 2022-ben a Milan-X és a Genoa ellen kevés. Ezek játszva elintézik. A HBM-es modell viszont érdekes, de a jó sebességhez annyira specifikusan kell programozni, hogy kérdéses az érdeklődés. Nyilván azok számára lesz alternatíva, akik be tudják vállalni a meglévő kódok átírását.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#17
Petykemano
veterán
vrob
#16
Petykemano
veterán
1.2-1.3 különbségből egyékbént már önmagában a TDP elég sokat magyarázhat.
350W és 280W között 70W a különbség. Az a 64 magos Milan esetén kb 1W magonként.
Ha megnézed az ábrát amit az imént linkteltem [link] 4W vagy 3W egy magnak még mindig elég nagy különbséget tud eredményezni - szerintem.Vegyük például az 5800U példáját. Ami persze valójában egy kicsit alacsonyabb fogyasztási szintet jelent, mert 15W esetén kevesebb, mint 2W jut egy magra.
Mindenesetre itt ha az 5800U-t nézzük 25w vs 15W, akkor ez 24%-os többletteljesítményt eredményez (CB23) [link]
Ha a 35W-os 5980HS és a 25W-os 5800U közötti különbséget nézzük akkor is 18.5%-kal nagyobb MT teljesítményt ad. Ha 5W-nak vesszük az uncore fogyasztását, akkor az 2.5 helyett a 3.75 már elég közel lehet. Persze itt már sokat számít az is, hogy milyen a lapka minősége. Hisz látható, hogy a 35W-os 5980HS annyit hoz, mint a 45W-os 5800H. De azt feltételezhetjük, hogy a 64 magos EPYC a legjobb minőségű lapokat kapja fogyasztás szempontjából.Találgatunk, aztán majd úgyis kiderül..
-
-
Abu85
HÁZIGAZDA
A CXL 1.1 mindet igényli a hitelesítéshez. A type a felhasználás módjára vonatkozik, de ettől támogatni kell mindet ahhoz, hogy hitelesítést kapj. És amúgy a Sapphire Rapids támogatja is mindet, csak a CXL.mem nem működik. De az Emerald Rapids-ban fog, mert javítják, ami miatt most nem működik.
Ha megnézed a képet, akkor magad is rájöhetsz, hogy hülyeség, amit írsz, mert a Type 3 kevesebbet kér, mint a type 2. Szóval akkor a CXL már magán a szabványon belül is visszafejlődik a type 2-höz viszonyítva?

Egyébként nem kell ezért baszogatni az Intelt. Az ilyen előfordul. Nyilván jobb lenne, ha nem, de ha felakasztják magukat, akkor sem tudják megoldani időre ezt a problémát, törölni pedig nem akarják a Sapphire Rapidsot csak emiatt, mert egy rakás kötbéres üzlet várja már a rendszert egy ideje.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez nem területekről szól. Az egyes gyorsítók nem használják az összes CXL protokollt. A típusok csak példák, hogy az egyes protokollok mire jók. Egyébként a protokollok közül a CXL.mem a legfontosabb, mert ha megnézed a cégeket, akkor éppenséggel mindegyik arra veri, hogy legyen végre memóriakoherencia, mert anélkül egy rakás extra kódot kell beírni, ami alapvetően meghatározza a program sebességét is. És ez igazából szívás a tesztelésben, szívás a költségekben, szívás mindenben. Egyszerűen a szóban forgó kódrészek nélkül ez sokkal-sokkal egyszerűbb lenne. Nem véletlen, hogy az első exascale szuperszámítógép olyan rendszer, ami pont ezt a problémát oldja meg.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Albus_D
aktív tag
Átolvasva egy csomó cikket a témában, egyedül csak te beszélsz bugról ezzel kapcsolatosan. Az egész nemzetközi sajtóban senkitől nem olvastam ilyet.
![;]](//cdn.rios.hu/dl/s/v1.gif)
Egyedül az anandtech boncolgatja a témát, de persze ő sem ír hasonlókat, viszont remekül leírja a helyzetet. Valószínű innen vetted az információt, de te már úgy tálaltad, mintha bugos lenne, holott csak később másik termékben jelenik meg a cxl.mem.
"Naturally it was our expectation that all CXL 1.1 devices would support all three of these standards. It wasn’t until Hot Chips, several days later, that we learned Sapphire Rapids is only supporting part of the CXL standard, specifically CXL.io and CXL.cache, but CXL.memory would not be part of SPR. We're not sure to what extent this means SPR isn't CXL 1.1 compliant, or what it means for CXL 1.1 devices - without CXL.mem, as per the diagram above, all Intel loses is Type-2 support. Perhaps this is more of an indication that the market around CXL is better served by CXL 2.0, which will no doubt come in a later product."
Tőlük származik a fenti kép is egyébként.
Ezen kívül arról sem olvastam sehol, hogy csak az kap cxl 1.1 hitelesítést, aki mindhármat "tudja", viszont az egész sajtó tényként kezeli hogy a sapphire rapids CXL 1.1-nek megfelel. Még csak utalás sincs az ellenkezőjére.
Arra viszont találtam adatot, hogy ezek különálló protokollok, és nem igazán kell mindhárom ahhoz, hogy CXL 1.1-es legyen valami. [link] Erre még számtalan oldalt linkelhetnék, de mindegyik ugyan ezt írja le.
A CXL három fő protokollt használ:
A CXL.io az inicializáláshoz, összekapcsoláshoz, eszközfelderítéshez és felsoroláshoz, valamint a regisztereléréshez használt protokoll. Nem koherens betöltési/tárolási interfészt biztosít az I/O eszközök számára, és hasonló a PCIe Gen5-höz. Az is kötelező, hogy a CXL eszközök támogassák a CXL.io-t.A CXL.cache az a protokoll, amely meghatározza az interakciókat a gazdagép (általában CPU) és az eszköz (például CXL memóriamodul vagy gyorsító) között. Ez lehetővé teszi a csatlakoztatott CXL-eszközök számára, hogy alacsony késleltetéssel gyorsítótárazzák a gazdagép memóriáját. Tekintsd ezt úgy, mint egy GPU közvetlen gyorsítótárat. a CPU memóriájában tárolt adatok.A CXL.memory / CXL.mem az a protokoll, amely a gazdaprocesszornak (általában egy CPU-nak) közvetlen hozzáférést biztosít az eszközhöz csatolt memóriához a load/store parancsok használatával. Tekintse ezt úgy, mint egy dedikált tárolóosztályú memóriaeszközt vagy egy GPU/gyorsító eszközön található memóriát használó CPU-t.
A CXL.io kötelező ahhoz, hogy végpontot kapjunk a CXL-en, de onnantól kezdve rendelkezhetünk CXL.io-val és a CXL.cache és/vagy CXL.mem három kombinációjának bármelyikével. A CXL-esek az 1-es típust (CXL.io + CXL.cache), a 2-es típust (mindhárom) és a 3-as típust (CXL.io + CXL.mem) használják példaként.
Vagy:
he CXL standard defines three separate protocols:
CXL.io - based on PCIe 5.0 with a few enhancements, it provides configuration, link initialization and management, device discovery and enumeration, interrupts, DMA, and register I/O access using non-coherent loads/stores.CXL.cache - allows peripheral devices to coherently access and cache host CPU memory with a low latency request/response interface.CXL.mem - allows host CPU to coherently access cached device memory with load/store commands for both volatile (RAM) and persistent non-volatile (flash memory) storage.
CXL.cache and CXL.mem protocols operate with a common link/transaction layer, which is separate from the CXL.io protocol link and transaction layer. These protocols/layers are multiplexed together by an Arbitration and Multiplexing (ARB/MUX) block before being transported over standard PCIe 5.0 PHY using fixed-width 528 bit (66 byte) Flow Control Unit (FLIT) block consisting of four 16-byte data 'slots' and a two-byte cyclic redundancy check (CRC) value. CXL FLITs encapsulate PCIe standard Transaction Layer Packet (TLP) and Data Link Layer Packet (DLLP) data with a variable frame size format.[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
Konkrétan arról van szó, hogy az egész CXL lényege a memóriakoherencia. Ez az a protokoll, amit kurvára kér mindenki. Ezért készül egy szabvány, mert ezt a problémát az egyes gyártók zárt megoldással oldják meg. Az AMD az Infinity Fabric, míg az NV az NVLink interfésszel. És ez kurvára baj az Intelnek, mert ha NV gyorsítót választasz, akkor olyan host processzor kell hozzá, ami NVLinket használ, míg ha AMD gyorsítót rendel az ügyfél, akkor ahhoz Infinity Fabric kapcsolatot támogató host CPU szükséges. Röviden, egyik gyorsítóhoz sem jó az Intel CPU, és emiatt muszáj volt valamit lépni.
Eredetileg a Sapphire Rapids és a Ponte Vecchio lett volna erre az Intel válasza úgy, hogy a készülő Xe Link a CXL szabványt használta volna fel. Ezt jegyzi is az alábbi, korai dia:

Na most azóta egy rakás dolog megváltozott. A Sapphire Rapids például nem kezeli a CXL.mem protokollt. Be van építve, mert erre tervezték eredetileg, láthatod a fenti dián, csak nem működik. Emiatt nem is alkalmas memóriakoherens összeköttetésre a CXL-en keresztül, vagyis a Ponte Vecchio is áttért egy zárt interfészre, ami szimplán az Xe Link lesz, és már nem a CXL része. [link] - itt ezt megerősítette az Intel is ( Q: Does Xe Link support CXL, if so, which revision? A: nothing to do with CXL ), annak ellenére, hogy láthatod fentebb, korábban nem ezt ígérték.
Tök jó dolgok a tervek, csak kurva sok dolgon változtathat a gyakorlat, például az, ha valami nem működik. Hiába tervezed bele, hiába jó a szimulációkor, a fizikai dizájnban lehet bármikor lehet olyan jellegű bug, amire nem számítottak. És tekintve, hogy az Emerald Rapids alig 7 hónappal fogja követni a Sapphire Rapids fejlesztést, gyakorlatilag egy ilyen volumenű bugot nincs idő kijavítani, mert fél évvel csúszna az alapdizájn. Akkor meg már nem érdemes kiadni, mert két-három hét múlva ott lesz Emerald Rapids. Ki venne akkor már Sapphire Rapids CPU-t?
A CXL pedig a CXL.mem nélkül lényegében semmit sem ér. Ha érne bármit is, akkor az Intel nem tervezne zárt verziójú Xe Linket memóriakoherenciára, de mivel pont ez a funkció a lényege, így rákényszeríti őket az, hogy a CXL.mem protokoll nem működik a Sapphire Rapids CPU-ban.
Az Intel pedig a saját diáin az elmúlt években egy rakás olyan dolgot említett, amiből aztán a valóságban nem lett semmi. Lásd fentebb a CXL szabványra épülő Xe Linket. Ők gondolhatják a CXL 1.1-nek a Sapphire Rapids CPU-t, de kb. mindenki le se fogja szarni, hogy az Intel mit gondol, ha nincs benne CXL.mem, ami az egész szabvány lényege. Enélkül nem tudsz memóriakoherensen használni GPGPU-t, FPGA-t, bármit amin van fedélzeti tár, illetve egyik készülő CXL tárolótípust sem, mert a CXL-re épülő termékek 99,9%-a igényli ezt a protokollt.
Ezek tudatában döbbenetesen hülyének kell nézned az Intelt ahhoz, hogy azt feltételezd róluk, hogy szándékosan nem tervezik bele a Sapphire Rapids CPU-ba azt a funkciót, amit a CXL eszközök kb. mindegyike igényel. Az más kérdés, hogy itt a probléma tervezésből ered, vagy magával a szabvánnyal van valami gond.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Nekem mindegy, hogy más olyan hülyének nézi-e az Intelt, hogy állítólag pont a legfontosabb protokollt szándékosan kihagyják. Tény, hogy mostanában nincs a toppon a cég, de ettől még nem butultak el.
A másik dolog, hogy a CXL valamiért extrém módon marketingként van kezelve. Ott volt a SiPearl bejelentése az Intellel való társulásról. [link] - nem tűnt fel senkinek, hogy a CXL szabvány értékét hangsúlyozzák egy olyan gyorsítóval, ami nem is támogatja a CXL-t.
Itt lehet egy olyan probléma a háttérben, hogy a konzorciumtól valami eredményt várnak a tagok, de egyelőre a közelében nincsenek az eredménynek, így mindenhova öntik a marketinget, hogy ezt leplezzék. Továbbra sem tartom kizárnak, hogy magával a szabvánnyal nincs minden rendben, és nem feltétlenül az Intel hibázott. De ettől a probléma fennáll.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Az AMD sokkal erőteljesebben őrzi a Genoa titkait, mint az Intel a Sapphire Rapirdsét. Szóval ezt akkor tudjuk meg, amikor megjelenik. Papíron amúgy igen, a Genoában érkezne az AMD-nél a CXL. Ugyanakkor az AMD eleve a saját Infinity Fabric interfészére fókuszál, mert a CXL-re bármit köthetsz, míg az Infinity Fabricra muszáj AMD gyorsítót venned. Éppen emiatt az AMD a saját interfészére termékkapcsolásként tekint. Például az Instint MI200 és a készülő MI300 gyorsítócsalád pont ezért nem kap CXL-t. Azt akarja az AMD, hogy EPYC mellett kapd meg a fejlesztés összes képességét, és ne Xeon mellett, azt le se szarják, hogy az Intel hogyan oldja meg. Ugyanígy az NVIDIA is NVLinket használ, és ehhez hoznak egy Grace CPU-t, és szintén le se szarják, hogy az Intel ezzel a helyzettel mit kezd.
Az AMD a Xilinxnek a kritikus fejlesztéseit is át fogja rakni Infinity Fabric interfészére. Már a szoftveres beolvasztást meg is kezdték. Kukázzák a Xilinx saját fejlesztőkörnyezetét, és a ROCm-be olvasztják az egészet. Mindennek az a lényege, hogy a Xilinxtől nehezen tudnak megszabadulni a megrendelők, mert évek alatt méregdrágán megírt kódjaik vannak rá, és sokkal olcsóbb, ha elfogadják az AMD-nek a termékkapcsolását, mert a Xeont sokkal könnyebb EPYC-re cserélni, ugyanis az nem jár a kódok átírásával. Ezért volt nagy marhaság hagyni az AMD-nek megvenni a Xilinxet, de most már mindegy.
Ez most a cégek között egy kőkemény stratégiai háború. Az Intel csak azért épít szabványt, mert nincs más választásuk. Nincs olyan termékük, amivel el tudnának adni egy saját zárt interfészt, míg az AMD-nek és az NV-nek van számos ilyen termékük, és ezt használják fegyverként arra, hogy az ügyfél zárja be magát a gyártói interfészre.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Albus_D
aktív tag
Hú ez kemény.
Akkor az nvidának van saját rendszere, az amd-nek is, de az intelnek az alterával meg a cxl-el és saját gyorsítóival nincs. Illetve szót sem érdemel, és még bugos is. Amiről lehet még az intel sem tud, de a nemzetközi sajtó biztosan nem.Szerinted ezt az évet még túléli az intel? Csak azért kérdem, mert az amd azt a célt tűzte ki magának hogy éves szinten akkora forgalmat generál, mint az intel egy negyedévben.
Más, az új zenhez való alaplapok még mindig intel lan vezérlővel jönnek?
-
Abu85
HÁZIGAZDA
Volt az Intelnek saját rendszere, csak a korábbi CEO-k nagyon nem tudták, hogy mit kezdjenek vele. Végül le is lőtték a Xeon Phi kivégzése után. Az Intelnél most folyamatosan Krzanich korábbi döntései csapódnak le. Gelsinger a jelenben nem nagyon tud ezzel mit tenni, mert öt éve kellett volna felülvizsgálni a projekteket, most már csak úszni tud az árral. De persze egyáltalán nem segít nekik az sem, hogy a szerverpiacon a két legfontosabb kategóriában a leggyorsabb termékeket előállító cégeknek megengedték az egyesülést a hatóságok.
Biztos túléli az Intel, csak nem mindegy, hogy mikorra versenyképes termékkel előállnak, akkor milyen részesedéssel kezdik visszaszerezni az elvesztett piacot.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

#25954560
törölt tag
erdekes h mar ossze tudtak hasonlitani a milannal a teljesitmenyet. most kaptunk egy sapphire rapids rendszert, ES proci van benne 52 maggal, de csak 1.5GHz-en jar. mivel meg nincsenek teljesen kesz, nem is tudni igazabol mennyin fognak menni. teljesen normalis, hogy az ES alacsonyabb frekin fut, csak csodalkozom h mar ossze tudtak hasonlitani valahogy egy kiforrott AMD-vel. persze lehet h vannak jobban sikerult darabok... en mondjuk a hbm-es verziot varom, bar lehet hiaba





















![;]](http://cdn.rios.hu/dl/s/v1.gif)


Új hozzászólás Aktív témák

ph Ez nem csak a kupak alá, de konkrétan a lapkába kínál betekintést.

- Beszámítás! Intel Core i7 7700K 4 mag 8 szál processzor garanciával hibátlan működéssel
- Beszámítás! Intel Core i5 6500 4 mag 4 szál processzor garanciával hibátlan működéssel
- Intel Core i3-10105 processzor (használt)
- Intel I7 13700K 16mag/24szál - Új, Tesztelt - Eladó! 128.000.-
- ELADÓ - Ryzen 7 5800X - ÉRTÉKELÉSRE VÁR
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest