- Apple iPhone 15 Pro Max - Attack on Titan
- MIUI / HyperOS topik
- Samsung Galaxy Watch6 Classic - tekerd!
- Blackview A200 Pro - hajtűkanyar a középkategóriában
- Xiaomi Mi 11 Ultra - Circus Maximus
- Honor 50 - apám nevében
- Egy kabaré volt az Edge 50 család belgrádi bemutatója
- OnePlus Nord 3 - kapcsoljuk északot
- Yettel topik
- Duotts F26 - megoldjuk erőből
Hirdetés
-


Frissült a MediaTek középkategóriás ajánlata
ma Hivatalos a Dimensity 6300, ez lesz a MediaTek kínálatából kivezetésre kerülő 6100+ utódja.
-


Toyota Corolla Touring Sport 2.0 teszt és az autóipar
lo Némi autóipari kitekintés után egy középkategóriás autót mutatok be, ami az észszerűség műhelyében készül.
-

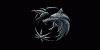
The Witcher - Jön az 5. évad, ezzel együtt pedig elkaszálták a sorozatot
gp A negyedik szezon forgatása a napokban kezdődött el, kíváncsian várjuk mikor láthatjuk a végeredményt.





-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

ftc
nagyúr
Én ugy gondoltam,hogy van egy C forditot .Természetesen C-ben irod meg a progit.Leforditod a progit egy UInteles gépen és minden optimalizácio nélkül ráereszted egy AMD-re.Mit fog produkálni és forditva.Ez csak érdekesség képpen kérdem mivel legtöbbször ugye Inteles gépeken történik a forditás,hogy van e kihatással valamit is a teljesitményre.
-

vedini
őstag
-

dezz
nagyúr
válasz
 #95904256
#893
üzenetére
#95904256
#893
üzenetére
Az FSB különbsége attól még ott van. Persze végülis tök mindegy, milyen tényezők által gyorsabb, azt kell behoznia a K10-nek.
szerk: viszont az teszteredmények többségében látható 20-25%-ból levonva azt a 14%-ot, már csak 6-11% marad, nem 10-20, átlagosan. A 20 kivételes eset.
vedini: Miért lenne ciki? Nem mindenkinek ez a kimondott szakterülete (vagy foglalkozik a témával mérnöki mélységben).
[Szerkesztve] -

#95904256
törölt tag
Hali dezz!
Az eredményeket átlagolva a tesztelt Penryn (3,33GHz) 35%-kal gyorsabbnak mutatkozik mint a QX6800 (2,93GHz). Az órajelet ''közös nevezőre hozva'' ( 35 * 2,93 / 3,33 ) is 30%-os előny mutatkozik. Nem 6-11%.
Az ''SSE4a'' meg csak ámítás. Csak az EXTRQ , INSERTQ , MOVNTSD , MOVNTSS utasításokat takarja. Amiből valjuk be őszintén igazából csak utolsó kettő az amivel talán találkozni is fogunk ( cache-t nem szennyező tároló utasítások ) a gyakorlatban.
Az Intel féle SSE4 viszont rengeteg új utasítást tartalmaz. Köztük egy pár lebegőpontos számítást támogató utasítással. Mivel a lista hosszú, így csak egy linket adnék. [link]
A memóriahozzáférés valóban jobban van megoldva a K10-nél, de most már látni is szeretném hogy ez mit jelent a gyakorlatban.
[Szerkesztve] -
dezz
nagyúr
válasz
#95904256
#906
üzenetére
Az ilyen egyszerű átlagolás értelmetlen. Tessék súlyozni egy kicsit.
Szal nem mindegy, milyen feladatnál mennyi gyorsulásra lehet számítani. Átlagos esetben, azonos órajelen 6-11% (de nyugodtan kerekíthetünk 5-10-re is), 1066-os Core2-höz képest. És lesz pár eset, amikor ennél nagyobb lesz a gyorsulás.
Tényleg csak 4 ''egyszerű'' utasítás az SSE4A? Szép... (Bár kérdés, mennyit számítanak majd.) Azért ezt meg kell néznem, hogy elhigyjem.
(Bár kérdés, mennyit számítanak majd.) Azért ezt meg kell néznem, hogy elhigyjem.
[Szerkesztve] -

marcias
őstag
Látom már egészen magas szinten folynak a viták, épp hogy a kötőszavakat értem
 Amikor arról beszéltetek, hogy ugye a K10-nek, ahhoz hogy ismét nyerő legyen, annyit kell dobnia a C2D-hez képest, mint amennyit a C2D dob a K9-hez képest. Itt 3 dolog fogalmazódott meg bennem:
Amikor arról beszéltetek, hogy ugye a K10-nek, ahhoz hogy ismét nyerő legyen, annyit kell dobnia a C2D-hez képest, mint amennyit a C2D dob a K9-hez képest. Itt 3 dolog fogalmazódott meg bennem:
1. A sima 2magos Phenom mennyivel lesz gyorsabb az X2-nél, illetve a C2D-nél (ha ezt egyáltalán meg lehet saccolni )
)
2. Esetleg inkább a 4magos rendszerben várható gyorsulás? Hiszen a C2Q nem igazi négymagos, hasonlóan a PentiumD-hez, ahol ugye az X2 szépen muzsikál ellene..
3. Sokféle hírt olvastam az asztali K10-ek megjelenését illetően, de várható még ebben az évben?
Illetve, egy érdekes kérdés, amire edig sehol nem kaptam választ.. A mostani gépem egy AMD AthlonXP 1700+-al üzemel (részletek a konfigomnál). Egy X2-es rendszert tervezek venni (4200-4800+). Léteznek erre összehasonlító tesztek, hogy általában mennyivel gyorsabb ez utóbbi? Akár csak hozzávetőlegesen, egész számokra, max tizedre kerekítve? Gondolok itt alkalmazásfutási gyorsaságra, másolás/tömörítés/renderelés stb.
Steam: marcias88
-
#95904256
törölt tag
Hali dezz!
Az ilyen egyszerű átlagolás értelmetlen.
Ott, azok az adatok szerepeltek. Az átlagolás egy köztes eredményt ad. Nem mindenki számára a megfelelőt, de egy demokratikus átlagot. Egyébként az ott szereplő adatokból jobb átlagot nem tudok számolni. Vagy ezek szerint értelmetlen volt maga a teszt is, ezzel együtt az a hozzászólásom is amiben linkeltem. Hm... néha előfordul.
Tessék súlyozni egy kicsit.
Na, ez a legyünk részrehajlóak kategória. Mi alapján súlyozzak? Nem láttam ehhez táblázatot. Vagy számoljak úgy hogy még kedvezőbb legyen az Intelnek?
A Penryn műveletvégzőit meg ne tessék lenézni, mert bizony tartalmaz pár erős meglepetést az AMD-nek. Mint pl. a ''Radix16'' osztómű ami állítólag kétszer gyorsabban oszt és nagy valószínűséggel pipe-olt vagy a 128 bites super shuffle engine ami 1 ( azaz egy ) órajel alatt képes az SSE shift műveletekre. Pl. A K10 és a Core 2 is csak 2 órajelenként tud indítani egy SHUFPx, UNPCKLxxx, utasítást, és ezek a műveletek bizony sok kódban hemzsegnek. Ezen kívűl az Intel-es weboldalon olyasmi is szerepel hogy az IPC értékre is rágyúrtak, meg sokminden másra... -
dezz
nagyúr
válasz
#95904256
#911
üzenetére
A súlyozást úgy értettem, hogy a hétköznapi használat során előforduló ilyen-olyan feladatok közötti arányt is beleszámítva. És az FSB különbözőségéből eredő eltérést is bele kellene számolni - ha tudnánk, mi mennyire múlik rajta. Vélhetően éppen a jétékok és a médiafeldolgozás során jön ki jobban.
Nos a nagy eltérések miatt nem igazán érdemes ilyen nagyátlagot számolni. Ez a szám az esetek egy részében (átlagos hétköznapi feladatok) erős túlzásnak bizonyul, más esetekben (médiafeldolgozás) meg túl alacsonynak. Tehát érdemes legalább néhány feladat-ketegóriát megkülönböztetni, és csak azokon belül átlagot számolni.
Jó dolog a Radix16-os osztás, azonban eddig kimondottan lassú volt a C2D osztása a K8-hoz képest, úgy tudom. Így valószínű beelőzte, de nem lett 2x gyorsabb a másiknál. (Az AMD egyébként az osztás megfelelő szorzással helyettesítését ajánlja, mert az meg eleve jóval gyorsabb.)
SSE4 vs. SSE4A(?): végülis a táblázatban látható új utasítások jó része olyan utasítások új variációi, amik már az SSE2/3-ban is megvoltak. El tudnád mondani, mire szolgálnak ezek az új variációk? Nekem úgy tűnik, korábban inkább floating-pointosak voltak, ezen újak meg inkább integeresek. Hacsak nem 16 bites integerekkel számolunk, nem lesz feltétlenül gyorsabb a dolog, inkább csak pontosabb (mármint egy 32 bites int v. fixpontos számítás egy 32 bites floating-pointnál). Persze pl. az egy utasításos dot product nem rossz dolog.
ftc: én is el tudom képzelni, hogy az ''SSE4A nagy része'' a Budapestben fog debütálni, hiszen korábban arról szóltak a hírek, hogy az SSE4A-ban majdnem minden benne lesz, ami az SSE4-ben, kivéve pár ''Intel 64''-hez kötődő művelet (bár nem tudom, melyek lennének ez utóbbiak). -
#95904256
törölt tag
Osztó utasítások latency/reciprocal throughput értékei (K10, Core2) :
single precision: 18(20)/15 , 6-18/5-17
double precision: 20(22)/17 , 6-32/5-31
integer 32 bit: 39 (K8) , 18-42/12-36
integer 64 bit: 71 (K8) , 29-61/18-37
Úgy tűnik egyedül a 64 bites lebegőpontos osztásban van csak lemaradása az Intelnek. Remélem nem csak erre vonatkozik a dupla sebesség.
Az AMD egyébként az osztás megfelelő szorzással helyettesítését ajánlja, mert az meg eleve jóval gyorsabb.
Ezt az Intel is ajánlja.
[Szerkesztve] -

Raymond
félisten
válasz
#65675776
#840
üzenetére
Na, par nap utan back in business
En meg arrol beszeltem hogy mar az MS bejelentese elott nem volt sok eselye az Itanium-nak desktop fronton elterjedni. Kijott az Opteron es a teljesitmenyevel es kompatibilitasaval mer elore kiutotte az Itanium barmilyen valtozatat. Meg ez Intel sem tudta volna lenyomi ezt a piac torkan. Foleg nem az akkor teljesitmennyel. Bassz meg most sincs ott ahol kene a sajat kategoriajaban Na mindegy, ez mar tortenelem...Privat velemeny - keretik nem megkovezni...
-

Andre1234
aktív tag
Hi...
Most én kicsit összezavarodtam.most akkor a Barcelona és a Phemon miben különbözik???
Mert a phemos a natív 4 magos cpu amiből lesz x2 desktop változat..
De a barca??
Valaki egy K10 roadmap-el előtudna rukkolni??
köszi..Ha x tart végtelenbe, akkor a prímek reciprok szorzatának negáltja 0-hoz tart...
-
dezz
nagyúr
Szal úgy érted, az AM2 lábkiosztásában már elkülönülnek ezen plane-ek, csak a mai alaplapokon még össze vannak kötve?
(#920): Huh, ez kicsit szíven ütött:
''and after hearing our friends at the motherboard companies talk, AMD is close to near/total panic mode right now as the Q3 Barcelona product launch schedule rapidly approaches.''
De utána ez egy icipicivel jobb kedvre derített (de azért nincs teljes egyenes arány a K10 hírek és a kedélyállapotom között ):
''At the same time, others have said that an earlier stepping of the core was overclocked from 1.8GHz to 2.5GHz without too much trouble.''
És itt mondják ki a tutit, azaz hogy lényegében nem tudnak semmit :
:
''All in all it's tough to say what clock speeds will be possible and when, but we do know for a fact that what we saw at Computex (Barcelona) ran slower than 2.0GHz.''
(#923): Ehhez még egy kis kiegészítés. A Barcelona a 4-magos szerver változat, mégpedig többutas rendszerekbe, 3-4db HT(2.0) busszal. Budapest: ugyancsak 4-magos szerver proci, de egyutas rendszerekbe, viszont már HT3.0-ával. Agena és Agena FX: a 4-magos asztali változat. Nos ez utóbbi lesz majd Phenom X4 és FX néven a boltokban.
Apropó... Miből lesz a cserebogár? Izé, miből lesz az s.F+-os Agena FX? A Barcelonából nem, mert az HT2.0-ás... De a Budapestből sem (elvileg), mert az meg csak egyutas (elvileg)... És ha van Agena FX, akkor miért nincs kétutas HT3.0-ás szerverchip? Itt valami titok lappang! (Nem szoktak teljesen különálló chipet csinálni csak desktopra.) Nézzük csak meg a die-shotot! 2 HT busz a 4-ből úgy van elhelyezve, hogy nem igazán lehet kihagyni, csak esetleg letiltani. (A másik kettő meg a szélén van, így könnyebben lehagyható.) Nos, szerintem a Budapestből lesz az Agena FX! Mégpedig úgy, hogy ott van szépen az a 2 HT busz, csak a Budapest ''kiadásban'' le van tiltva az egyik. De miért nem adják ki a Budapestet akkor kétutas szerverchipként is?
[Szerkesztve] -
Raymond
félisten
''Szal úgy érted, az AM2 lábkiosztásában már elkülönülnek ezen plane-ek, csak a mai alaplapokon még össze vannak kötve?''
Valahogy ugy. A chip tudja fuggetlenul attol hogy AM2 vagy AM2+ megy alatta de csak az utobbi lap tudja biztositani a kulonallo ellatast.
Az az utolso idezet nekem olyan ''cover all our bases'' tipusunak tunik. Hogy ne mondhassa senki ha veletlenul 2.3-on kijon hogy nem szoltak Vagy az is lehet hogy mert az utobbi par heten/honapban eleg sok pozitiv AMD-s cikk volt az Anandeknal probaljak kicsit higitani a rossz hireket.
Szvsz Agena FX ugyanugy a ketutas server/workstation chipekbol lesz mint eddig ugyhogy eloszor a Barcelona-bol. Aztan majd ahogy jon a tobbi.Privat velemeny - keretik nem megkovezni...
-
dezz
nagyúr
Oké, de elvileg az Agena FX HT3.0-ás, miközben kétutas (a s.F+ változat). A Barcelona meg HT2.0. Lagalábbis jól titkolják, ha HT3.0-ás mégis. De miért tennék? Vagy úgy gondolod, - a kiszivárgott(?) roadmapok ellenére - HT2.0-ás lesz először a kétutas Agena FX is? Sokan reklamálnak majd. Desktopon, 1-2, max. néhány task futtatása közben kritikusabb a memória-késleltetés, márpedig a másik proci ramjához való hozzáférés az egyik HT linken keresztül megy.
-

P.H.
senior tag
válasz
#95904256
#688
üzenetére
Tekinthető alapnak ez Intel-dokumentáció (http://www.intel.com/design/processor/manuals/248966.pdf)
Adós vagyok még egy válasszal ROB-ra vonatkozó kijelentésemre, de először egy helyesbítés: a 4-1-1-1 bottleneck Core2-re nem igaz. Valóban 4-1-1-1 felállás, de nem μop-ok a decoder-ek kimenetei, hanem micro-fused μops, ezt a fenti .pdf konzekvensen használja minden említéskor (nem úgy, mint egyes dokumentációk, amik oldalakon keresztül vezetik le, hogy „single-μop”, aztán a végére odabiggyesztik egy mondatba, hogy ezek valójában micro-fused μops…)
''All decoders support the common cases of single μop flows, including: micro-fusion, stack pointer tracking and macro-fusion. Thus, the three simple decoders are not limited to decoding single-μop instructions. Packing instructions into a 4-1-1-1 template is not necessary and not recommended. ''
Ezt bottleneck-nek tekinteni semmiképpen nem lehet, még az AMD megoldásánál is szélesebb, ezt így ebben a formában csak sorozatos op [mem],reg vagy microcode-ROM alapú utasítások tudják megfogni.
Intel ROB (és egy kicsit tágabban, és ott nem csak Core2-re gondoltam):
- Az Intel CPU-k esetében semmi nem cáfolja azt, hogy egyetlen, 128 bites egységméretű register-file van, tehát az integer register-ek is 128 bitesek (Core2 esetében kibővítették az integer ALU-kat is 128 bitre, ezek végzik pl. a SSEx logikai műveleteket, az int-FPU és FPU-int átkapcsolás ára egy + órajel késleltetés). Ha egy register-file van, akkor az rename miatt annyi belső register-nek kellene lennie legalább, ahány elemű a ROB (minden micro-fused μops-nak jusson más-más célregister átnevezés után) + a véglegesített register-értékek + a belső átmeneti register-ek. Ezt a nagy register-filet írni/olvasni kell, ez a ROB feladata. Emellett a μop-okban található argument placeholder-ek (hogy mondják ezt magyarul két szóban?) is 128 bitesek, az AMD 64 biteseivel szemben.
- Intel esetében egy hosszabb kódot figyelembe véve valamivel több μops keletkezik fordítás után, mint amennyi micro-op AMD esetében, ez a szám nem csökkent számottevően az idők folyamán (ennek egyik oka, hogy az Intel alapból 128 bites register-file-t és default adatméretet alkalmaz, Netburst óta biztosan, az execution pipe-okban törtek ketté 64 bites elemekre a 128 bites adatok, majd fűződtek össze, növelve a késleltetést). K10 esetében viszont drasztikusan csökken a szükséges micro-opok száma 128 bites műveletek esetében, felére. De nézzük végig a ROB- és Reservation Station-méreteket, utóbbi adja nagyjából az adott CPU out-of-order előrelátási mélységét:
Core2:
..ROB: 96 micro-fused μops
..RS: 32 entries
..decoders: 4-1-1-1 micro-fused μops/cycle
..ROB read ports: 2 (3?)
..Possible input registers/cycle: 4x3
Pentium M/Core Solo-Duo:
..ROB: 40 micro-fused μops
..RS: 20 entries
..decoder: 4-1-1 micro-fused μops /cycle (128 bites műveleteknél csak store-fusion van, load-op fusion nincs)
..ROB read ports: 2
..Possible input registers/cycle: 3x3
Netburst:
..ROB 126 μops
..RS: N/A
..decoder: 4 μops/cycle + trace cache
..ROB read ports: N/A
PPro/P2/P3: ROB:
..40 μops
..RS: 20 entries
..decoders: 4-1-1 μops/cycle
..ROB read ports: 2
..Possible input registers/cycle: 3+2+2
K7:
..Instruction Control Unit: 72 macro-ops (up to 144 micro-ops)
..Integer Scheduler (18 macro-ops) + FPU scheduler (36 macro-ops): 54 macro-ops (up to 18*2+36=72 micro-ops)
..IFFRF-read + FPU register-file read: 9+5/cycle
..Possible input registers/cycle: 3x3 + 2+2+1
K8, K10:
..Instruction Control Unit: 72 macro-ops (up to 144 micro-ops)
..Integer Scheduler (3x8 macro-ops) + FPU scheduler (36 macro-ops): 60 macro-ops (up to 24*2+36=84 micro-ops)
..IFFRF-read + FPU register-file read: 9+5/cycle
..Possible input registers/cycle: 3x3 + 2+2+1
- Hogy miért emeltem ki a ROB – Register File olvasások számát? Van itt egy súlyos maradvány bottleneck Core2 esetében:
As a μop is renamed, it determines whether its source operands have executed and been written to the reorder buffer (ROB), or whether they will be captured “in flight” in the RS or in the bypass network. Typically, the great majority of source operands are found to be “in flight” during renaming. Those that have been written back to the ROB are read through a set of read ports.
Since the Intel Core Microarchitecture is optimized for the common case where the operands are “in flight”, it does not provide a full set of read ports to enable all renamed μops to read all sources from the ROB in the same cycle.
When not all sources can be read, a μop can stall in the rename stage until it can getaccess to enough ROB read ports to complete renaming the μop. This stall is usually short-lived. Typically, a μop will complete renaming in the next cycle, but it appears to the application as a loss of rename bandwidth. Some of the software-visible situations that can cause ROB read port stalls include:
• Registers that have become cold and require a ROB read port because execution units are doing other independent calculations.
• Constants inside registers
• Pointer and index registers
In rare cases, ROB read port stalls may lead to more significant performance degradations. There are a couple of heuristics that can help prevent over-subscribing the ROB read ports:
• Keep common register usage clustered together. Multiple references to the same written-back register can be “folded” inside the out of order execution core.
• Keep dependency chains intact. This practice ensures that the registers will not have been written back when the new micro-ops are written to the RS.
These two scheduling heuristics may conflict with other more common scheduling heuristics. To reduce demand on the ROB read port, use these two heuristics only if both the following situations are met:
• short latency operations
• indications of actual ROB read port stalls can be confirmed by measurements of the performance event (the relevant event is RAT_STALLS.ROB_READ_PORT, see Appendix A of the Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3B)
If the code has a long dependency chain, these two heuristics should not be used because they can cause the RS to fill, causing damage that outweighs the positive effects of reducing demands on the ROB read port.
Annyira zavaró ez a szűk keresztmetszet, hogy az Optimization Reference szerzője tanácstalan, hogy hogyan kellene elkerülni. És ezalapján egy sima
movaps xmm1,[esi+ecx]
addps xmm1,[edi+ecx] vagy xorps xmm1,xmm2
movaps [ebx+ecx],xmm1
sub ecx,edx
jg …
ciklus is meggátolja a 4 micro-fused μop/cycle ROB-ba érkezését. (amennyiben esi, edi, ebx mondjuk tömbcím, tehát konstans, és az xmm2 mondjuk egy előjelváltó 128 bites konstans, edx-ben pedig a 10h érték van, előre felvett konstansként).
- Az Intel esetében a Reservation Station osztja el a μop-okat a 6 execution unit között. Minden órajelben hatot kell találnia a 6 execution port-ra („vízszintes” irány) out-of-order („függőleges” irány). Ezzel szemben AMD esetén a scheduler-eknek 9-et (dezz #734, raymond #736: jó az a kilences szám, 9 execution unit van, legalábbis K7 óta. Nem újdonság, de úgy látszik, nem minden csoda tart csak három napig. Az, hogy az „instructions” hogy került mögé „micro-op” helyett, azt a szerző tudja…), viszont fixed-issue miatt csak függőlegesen kell keresnie. Ez a fixed-issue végigvezet majdnem a teljes CPU-n, kissé VLIW-felépítésre emlékeztetve, meglehetősen leegyszerűsítve sok mindent (decode, execution, retirement…)
Én nem nagyon látom, hogy az Intel-ek egyszerűbb felépítésűek lennének, mint az AMD-k (1 horizontal-vertical vs ’6’ vertical ütemező, egy, 128 bites közös register-file vs két, 64 bites register-file - integer oldalon valós rename nélkül -, RISC vs valamennyire VLIW felépítés). Sőt. A bonyolultabb/nagyobb adatméretű ROB- és RS felépítést az Intel általában az execution unit-ok egyszerűsítésével szokta ellensúlyozni (mint pl. amit említettem, hogy közös ALU van az integer (8-16-32-64 bit), az MMX (64 bit) és az SSEx (128 bit) logikai műveleteknek; vagy annak idején a közös integer-FMUL egység, stb.).
Azt is azért látni kell, hogy a K7-K8-K10 vonal kevesebbet változott az idők folyamán szerkezetileg, mint mondjuk csak a Netburst a Villamette és a Presler között. Erre lehet azt is mondani, hogy mert olyan hatékony, azt is, hogy az AMD-nek nincs annyi feljesztési tőkéje, mint az Intel-nek, de ez már inkább hitvita és szimpátia kérdése, mint szakmai. Az, hogy az AMD miért nem tudja járatni ezt az alapvető felépítést az annak „megfelelő” órajelen (szerintem egy olyan 4 GHz-ig kellene dual-core K10-nek skálázódni, hogy megoldódjanak rövidtávon az AMD problémái), ezt pontosan nem tudjuk, de lehetséges, hogy ennek okát nem a szűk értelemben vett magokon belül kell keresni.
[Szerkesztve]Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Erre én tényleg nem tudok válaszolni, a többiek szerintem (akosf biztosan) sokkal több érdemlegeset tudnak mondani erre a kérdésre. Én mindent assembly-ben írok már pár éve(, legyen az hot-spot, vagy csak egy egyszerű háztartási kód, pl. egy szövegbeviteli mező), Delphi fordítja. Szeretem szó szerint viszontlátni ugyanazt a CPU-window-ban, mint amit beírtam.
Privát vélemény: a fordítókat szükséges rossznak tartom, általában alapszintű kódot csinálnak a saját beírt magas szintű programodból, messze nem olyan hatékonyat, hogy gyártók közti különbségekről lehessen beszélni. Nem kis részben ennek köszönhető a CPU-k fejlődésének egy-egy irányvonala is (jó példa a stack-engine mindkét részről, de mondjuk magáért az out-of-order-ért sem kevésbé felelősek a compiler-ek).
Más kérdés a beépített függvénykönyvtárak, főleg a math library-k. Azok egy része azért kézzel készül, ott lehetnek különbségek. De általában csak ilyen szinű trükközések vannak: [link]
[Szerkesztve]Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
#95904256
törölt tag
Hali P.H.!
A hozzászólásomban ugye azt említettem hogy az inteles mikro-opok jóval egyszerűbb szerkezetűek lehetnek mint az AMD-s makro-opok, így egyszerűbb felügyelő/vezérlő logikát igényelnek. Azonban már kezdek ebben kételkedni. Az intel a ''mikro-op fusion'' kiaknázását tanácsolja az Optimization Manualban, illetve szép számmal akadnak single mikro-op utasítások is. Ezek szerint mégis egy rakás függőségi információt kell tartalmaznak a mikro-opok, tehát mégsem egyszerűek.
Az utóbbi pár napban a Core2 ROB-jával játszadozom az Intel vTune segítségével. Az már látszik hogy a ROB-ot nagyon nehéz teletömni ( ROB.FULL esemény ) egy valamire való, többé-kevésbé optimalizált kóddal. Egyelőre kérdés hogy azért mert a sok renaming miatt nehézen tudja csak tölteni a dekóderekból vagy azért mert az execution unitok elég gyorsak.
Megjegyzés: Egy SSE/SS2 FP számolásokkal teli, K8-ra optimalizált kód a Core2-re adaptálva ( csak az utasítás sorrend módosításával! ) közel 30%-ot gyorsult az eredeti változathoz képest. Az adaptált kód K8-on viszont csak alig lassult pár százalékot. Ez azt jelzi hogy az K8 ICU-ja meglehetősen jó munkát végez. Kár hogy futási sebességben a Core2-es optimált kód mintegy 87%-kal gyorsabban futott le mint K8-on az arra optimalizált, azonos órajelen. ( Az eredeti kód is gyorsabb volt Core2-őn (128 bit SSE engine ). ) -
válasz
#95904256
#932
üzenetére
nagyon nem értek hozzá, de olvasgattam amit itt írogattok, tehát csak tippelgetek és javítsatok ki ha rosszul látom a kérdést
nem az lehet ennek a fő oka, hogy a c2 az egyszerre 128 biten tolja át azt a 128 bites sse utasítást míg az amd csak 2x64-en (tudom ennél kicsit sokkal sokkal bonyolultabb)?
ha esetleg így van akkor szerintem az amd 87%-os ''lemaradása'' nem is olyan nagyon rossz, és ahogyan olvastam a k10 pontosan 2x olyan gyors lesz ezen a téren, tehát az intel optimalizált kódban is megveri a k10 a c2-t.
nekem ez jött le az itteni hozzászólásokból.
-
dezz
nagyúr
Nézd csak ezt:
As of writing this Core 2 supports ld+ex and st(a)+st(d)
uOP fusion, and one load plus one store per cycle.
This suggests that at most two fOPs can show up for re-
tirement per cycle, plus another two uOPs.
I got a piece of code that can sustain the retirement of
two fOPs plus ~1.75 uOPs per cycle -- so I'm reasonably
certain of these limits.
[link]
(fOPs = fused uOPs) -
P.H.
senior tag
válasz
#95904256
#932
üzenetére
Meg akartam kérdezni, milyen jellegű kódnál jött ki a 87% különbség, de nem kérdezem, nincs miért. Dezz, megnéztem, aztán a K8 idevonatkozó adatait is.
K8 retirement-szélesség órajelenként 3 macro-op. De nem DirectPath Double utasítások esetén, ez minden 128 bites SSEx utasításra hatással van. A két 64 bites macro-opnak azonos órajelben, egyszerre kell visszavonulnia, így a 3. slot-ba sem kerülhet másik 128 bites utasítás egy macro-opja. Tehát a retirement leszűkül órajelenkénti 1 vectorSSE utasításra, legyen az op reg,reg vagy op reg,mem. (Ellenben Core2 4 vagy a korábbi Intel-ek 3 értékével, op reg,reg-re nézve...)
''Most 128 bit SSE and SSE2 instructions are implemented as double dispatch instructions. Only those that can not be split into two independent 64 bit operations are handled as Vector Path (Micro Code) instructions. Those SSE2 instructions that operate on only one half of a 128 bit register are implemented as a single (Direct Path) instruction.
[...]
A disadvantage may be that the decode rate of 128 bit SSE2 instructions is limited to 1.5 per cycle. In general however this not a performance limiter because the maximum throughput is limited by the FP units and the retirement hardware to a single 128 bit SSE instruction per cycle.
[...]
Instructions generated by Doubles can mix with other (Direct Path) instructions during decoding and retirement. The two instructions generated by a Double must however retire simultaneously, imagine a PUSH that does retire the memory store but doesn't retire the Stack Pointer update.. This leads to the limitation that both instructions generated by a Double must be in the same 3 instruction line during retirement.''
Vigasz, hogy K10 esetén DirectPath lesz a 128 bites utasítások többsége, így a decoder-bandwidth kétszeresére, a retirement háromszorosára fog nőni ezek esetében, kisebb latency és nagyobb throughput mellett, ez talán jelentősen megnöveli a SSEx-teljesítményt. Nem alaptalan Dezz [link] elmélkedése.
[Szerkesztve]Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Andre1234
aktív tag
Hi..
Szintén lenne egy kérdésem..
Most hogy AM2-es plattformok bios frissítéssel fogadni tudják majd a pehomon procikat, természetesen kis érvágással gondolok itt a HT sebességére, mennyi idő múlva lesz alaplap, amely teljesen az új architektúra kiszolgágására készül..???
Van vmi tervezet már az NV részéről???
Vagy az amd azért húzza az időt hogy egy tökéletes cpu alaplap konfigot nyomjon piacra amd -ati részéről??
Sztem van benne ráció mert természetes hogy a jelenlegi AM2 alaplapot fogadják a cput de nem hiszem, hogy az amd fanok kik már éhezve várják a phemont, nem vennének teljeses új alaplapot mely kihasználja a cpu-t..
Főleg ha az amd-ati kitalál plattformban is az NV-val szemben..Ha x tart végtelenbe, akkor a prímek reciprok szorzatának negáltja 0-hoz tart...
-

Mackósajt
senior tag
válasz
 Andre1234
#938
üzenetére
Andre1234
#938
üzenetére
Az AMD új lapkakészlete az RD790, illetve kistestvére, a 780 már kész van, és egyes alaplapgyártók bemutatták a vele készült első lapok mintadarabjait. [link]
Mire lesz Phenom, nyilván lesz tömeggyártás is.
Azt nem tudom, az nVidia mit tervez, de úgy néz ki, még nincsenek elkésve... -
#946
 Komplikato
veterán
dezz
#937
Komplikato
veterán
dezz
#937
Komplikato
veterán
Valamelyik plyetkaoldalon láttam valami olyat, hogy egy új mag 2.8GHz-en ketyeget ...
Meg volt ugyanazon oldalom egy kivehetetlen screenshot ami egy 2x4 magos gép priterheltségét mutatta. Nem tudom mi futott rajta, de közel 100%-on volt mind a 8 mag.
"Figyelj arra, aki keresi az igazságot és őrizkedj attól, aki hirdeti: megtalálta." - (André Gide)
-
#95904256
törölt tag
Következő hónapban az Intel megfelezi a négymagos Q6600 árát ( $530->$266 ). Ez már kezd elérhetőnek tűnni. Remélem az AMD még az idei karácsony előtt kirukkol az új desktop procikkal, valami hasonló áron. Az már látszik hogy júlisban nem lesz K10-esem.








 )
)






 Amikor arról beszéltetek, hogy ugye a K10-nek, ahhoz hogy ismét nyerő legyen, annyit kell dobnia a C2D-hez képest, mint amennyit a C2D dob a K9-hez képest. Itt 3 dolog fogalmazódott meg bennem:
Amikor arról beszéltetek, hogy ugye a K10-nek, ahhoz hogy ismét nyerő legyen, annyit kell dobnia a C2D-hez képest, mint amennyit a C2D dob a K9-hez képest. Itt 3 dolog fogalmazódott meg bennem: )
)










 :
:









Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Folyószámla, bankszámla, bankváltás, külföldi kártyahasználat
- Otthonfelújítási program (2024.)
- Apple iPhone 15 Pro Max - Attack on Titan
- MIUI / HyperOS topik
- Okos Otthon / Smart Home
- Call of Duty: Modern Warfare III (2023)
- EAFC 24
- Azonnali fáradt gőzös kérdések órája
- Samsung Galaxy Watch6 Classic - tekerd!
- Elemlámpa, zseblámpa
- További aktív témák...
